MATCHing Paths with Very Dense Nodes in Neo4j 2.2
· 4 min read
Last weekend, I came across a tweet announcing that Wikimedia released the dataset of the page clickstreams for February 2015. I found it interesting to download this dataset and see how people arrive on the Neo4j’s Wikipedia page.
The data is quite simple; we have page entities that relate to other pages. A page can either be a Wikipedia page, or a non-Wikipedia page such as Google. Relationships can represent a user click from a Wikipedia page to another page, or a user searching on Google or Wikipedia. The number of times an event occurs is also provided in the dataset.
Importing the Dataset
You can download the dataset here.
Importing the dataset is really straightforward and the code I used can be found in this gist.
Analysing the Data
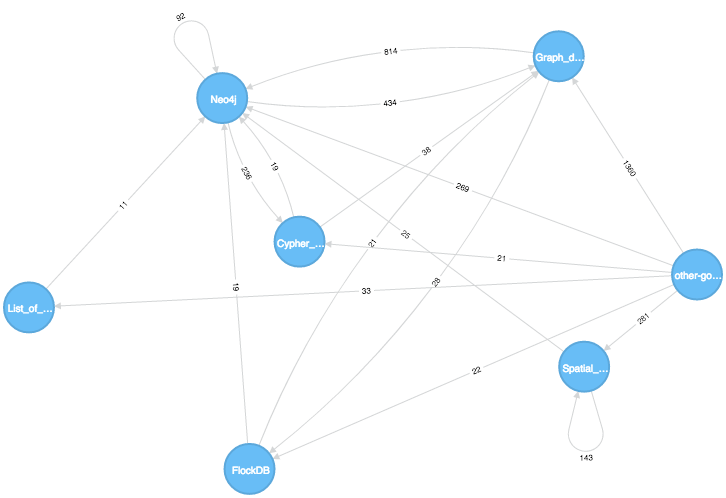
We can start with simple queries like the pages from which people are arriving to the Neo4j page:
MATCH (neo:Page {title:'Neo4j'})
MATCH (neo)<-[r:TARGET_BY_LINK]-(from)
RETURN from.title, r.occurences
NoSQL 282
FlockDB 19
Paxos_(computer_science) 22
Cypher_Query_Language 19
Graph_database 814
List_of_AGPL_web_applications 11
Spatial_database 25
Taking into account two degrees:
MATCH (neo:Page {title:'Neo4j'})
MATCH p=(neo)<-[:TARGET_BY_LINK*2..2]-(from)
WHERE neo <> from
RETURN extract(n in nodes(p) | n.title) as pages,
reduce(x=0, r in rels(p) | x + r.occurences) as occ
ORDER BY occ DESC
LIMIT 10
Neo4j, Graph_database, NoSQL 1450
Neo4j, Graph_database, Big_data 1045
Neo4j, Graph_database, Graph_(abstract_data_type) 967
Neo4j, Graph_database, Triplestore 897
Neo4j, Graph_database, Network_model 882
Neo4j, Graph_database, Nested_set_model 865
Neo4j, Graph_database, Graph_theory 863
Neo4j, Graph_database, DEX_(Graph_database) 856
Neo4j, Graph_database, Graph_(mathematics) 856
Neo4j, Graph_database, Cypher_Query_Language 852
So the NoSQL movement and the Graph ecosystem are the most common referrers, which is not too surprising.
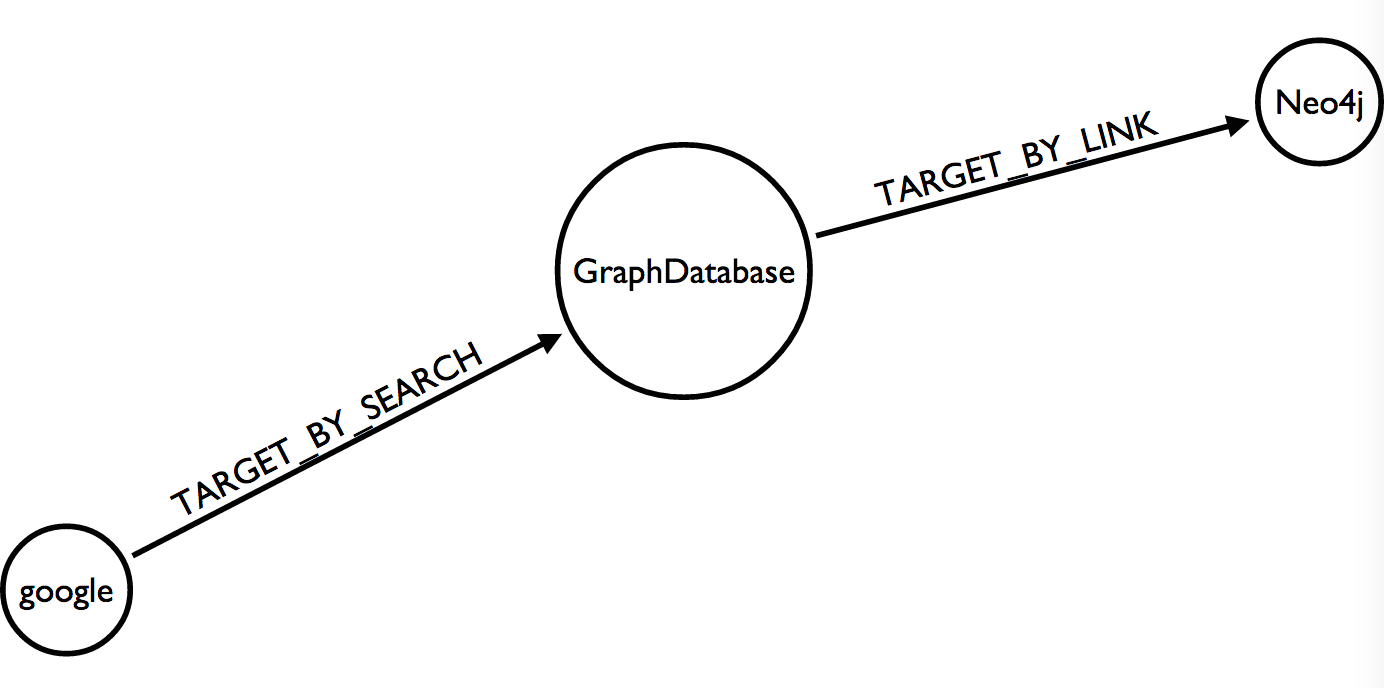
From Google to Neo4j
The last insight I wanted to gain is to know how people arrive at the Neo4j page from another one that they found via a Google search.
The query seemed obvious to me and I expected really fast response times as I’m describing the whole pattern and the page titles are indexed :
MATCH (neo:Page {title:'Neo4j'}), (google:Page {title:'other-google'})
MATCH (neo)<-[:TARGET_BY_LINK]-(x)<-[:TARGET_BY_SEARCH]-(google)
RETURN x.title
Unfortunately, this query took 24 seconds to return on my machine with the default 4GB heap settings for Neo4j.
NB: Note that the other-google Page node has more than 2 million outgoing TARGET_BY_SEARCH relationships.
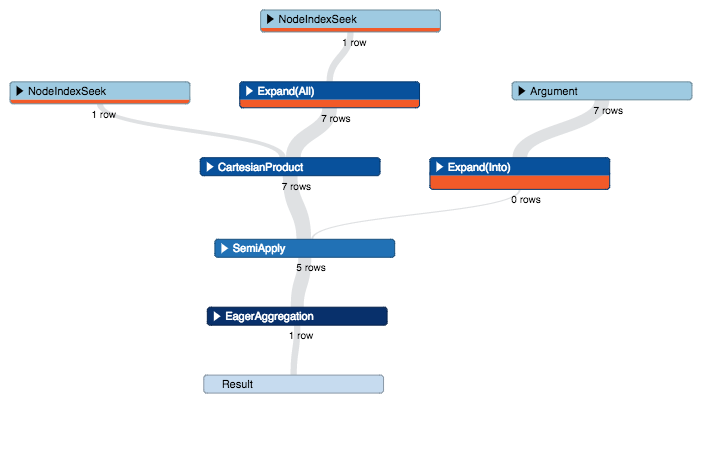
My first reaction of course was to analyse the execution plan with PROFILE :
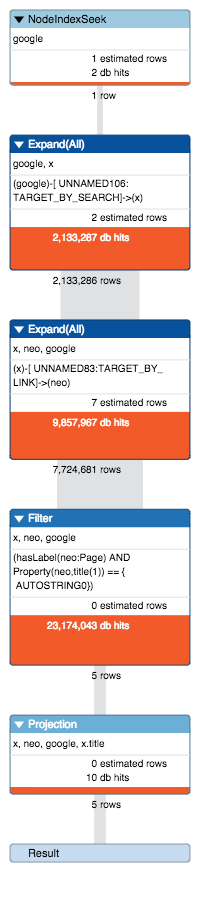
So why so much time and so many database accesses? I was really enjoying the 2.2 release; however, I was confused why the cost-based planner couldn’t figure out to run this simple query efficiently.
I tried different ways of doing the same query. Variable length paths, multiple relationships types etc… without any performance improvement.
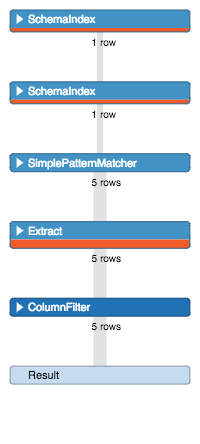
I spoke about this behavior with my friend http://twitter.com/mesirii[Michael] and he asked me to change the query to the following.
He said that calculating matches on a simple pattern like (x)<-[:TARGET_BY_SEARCH]-(google) now takes the degree of both nodes at runtime into account
and checks from the side with the smaller degree. The same applies to calculating the counts of simple path expressions
like size((page)-[:TARGET_BY_LINK]->()) where the degree of the given node is used instead of iterating over the relationships.
MATCH (neo:Page {title:'Neo4j'}), (google:Page {title:'other-google'})
MATCH (neo)<-[:TARGET_BY_LINK]-(x)
WHERE (x)<-[:TARGET_BY_SEARCH]-(google)
RETURN count(*);
Wow, stunning, amazing, query returning results in 14ms as I expected in my first attempts. It looks like Cypher needs more hints than in the previous 2.1.x versions.
You can still use the previous Cypher rule planner by prepending PLANNER RULE to your queries :
neo4j-sh (?)$ PLANNER RULE
> PROFILE MATCH (neo:Page {title:'Neo4j'}), (google:Page {title:'other-google'})
> MATCH (neo)<-[:TARGET_BY_LINK]-(x)<-[:TARGET_BY_SEARCH]-(google)
> RETURN x.title;
+---------------------------------+
| x.title |
+---------------------------------+
| "FlockDB" |
| "Cypher_Query_Language" |
| "Spatial_database" |
| "List_of_AGPL_web_applications" |
| "Graph_database" |
+---------------------------------+
However I couldn’t accept it as a long-term solution but more as a temporary workaround. Mostly because such queries make summing the relationship properties not so user-friendly anymore.
Thanks again to Michael, he asked Neo4j Cypher team and their answer was the following :
The cost based planner only knows from the database statistics that a
:Pagenode has between 0 and x millions relationships. So when planning the query it doesn’t have any runtime information and does not prefer either side of the query. At planning time there is no runtime information available, only counts for labels, relationships and property cardinalities and selectivities, so it actually doesn’t know if the assumption holds true later.
The solution is to tell Cypher where to start from with the USING clause.
MATCH (page:Page {title:'Neo4j'}), (google:Page {title:'other-google'})
USING INDEX page:Page(title)
MATCH (page)<-[:TARGET_BY_LINK]-(x)<-[:TARGET_BY_SEARCH]-(google)
RETURN count(*);
neo4j-sh (?)$ PROFILE MATCH (page:Page {title:'Neo4j'}), (google:Page {title:'other-google'})
> USING INDEX page:Page(title)
> MATCH (page)<-[:TARGET_BY_LINK]-(x)<-[:TARGET_BY_SEARCH]-(google)
> RETURN count(*);
+----------+
| count(*) |
+----------+
| 5 |
+----------+
1 row
12 ms
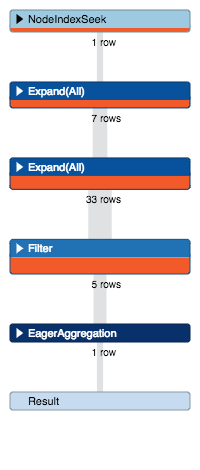
And the query is done in 10ms !!!
Conclusion
As always, the PROFILER allows you to quickly identify performance problems of your queries.
Thanks to Michael and the Neo4j Cypher team for fast support!