
Welcome to our LLMs and Knowledge Graphs Series. In this collection of blogs, we embark on a journey at the intersection of cutting-edge large language models and graph-based intelligence. Whether you’re a seasoned data scientist, a curious developer, or a business leader seeking actionable insights, this series promises to demystify the synergy between LLMs and knowledge graphs.
What to Expect
Each blog in this series delves into practical applications, challenges, and opportunities arising from the fusion of LLMs and graph technology. From transforming unstructured text into structured knowledge, to prompt engineering and to unraveling complex relationships, we explore how these powerful tools can revolutionise information extraction and decision-making.
Dive into the Gupta Leaks case study and witness how GPT-powered prompt engineering uncovers webs of corruption, empowering law enforcement and organisations.
The emergence of Large Language Models (LLMs) has dramatically changed the natural language processing (NLP) landscape. The reason lies mainly in their ability to understand and analyse natural language and, at the same time, generate human-like responses.
The advantage of the LLMs, trained on massive datasets, is that they are not domain-specific. This allows us to use them in a wide range of scenarios. In this blog post, we focus on law enforcement, specifically on public judicial reports on a massive web of state corruption in South Africa or “state capture” known as the Gupta Leaks. These documents describe in detail the affairs of various organisations and individuals and their complex corrupt and criminal activities.
In this scenario, we employ OpenAI’s GPT (Generative Pre-trained Transformers) to extract relevant knowledge from the texts by using the model to perform the tasks of Named Entity Recognition (NER) and Relation Extraction (RE). These steps are crucial milestones on the path from unstructured documents to a Knowledge Graph since they allow us to identify the key elements – entities and relations among them – representing the story. The resulting Knowledge Graph (KG) then represents a unified and easy-to-navigate source of truth, in our case, the affairs of the Gupta family and their business and political dealings.
The blog post reflects the two key steps of the process of KG building from textual data. The first part focuses on prompt engineering – the process of formulating the task appropriately – and contains some observations on the model’s choice and settings, while the second part is mainly related to Knowledge Graph building, including data cleaning and normalisation. Finally, we will analyse the results and attempt to answer some of our main questions about the Guptas: “How did the Guptas manage corruption of this scale for so long without raising suspicion? What were the Guptas’ complicit organisations?”.
Prompt engineering for a successful knowledge graph building
There are several compelling advantages of choosing LLMs over traditional NLP models, especially considering the complex and challenging task of Relation Extraction. On one hand, traditional models demand much more human effort: it takes a considerable initial investment to build domain-customised NLP pipelines (NER, Coreference Resolution, RE). Very often, training these customised models requires a lot of time, expert data science knowledge and significant manual data labelling work. In contrast, LLMs only require the identification of the most effective task formulation, commonly referred to as a “prompt.” It’s worth noting that this is not an entirely effortless task, but it does have a much gentler learning curve and a more straightforward adoption process overall.
The prompt, expressed in plain text, is our main tool for routing the model in the right direction and expressing our intentions. The challenges mentioned in the first blog post of this series – the missing entities and relationships, the presence of irrelevant, inaccurate or even incorrect results, and the normalisation issue (a large number of semantically identical entity and relation classes) – made us realise that a generic prompt, like the one we were using, is not sufficient for the complex task of Relation Extraction. Thus, we pursued the investigation and performed a series of experiments, eager to identify a suitable prompt for our needs.
Experimenting with the prompt was very instructive – by observing the failure points and adapting the instructions iteratively, we were able to significantly reduce the error rate. Motivated by this experience, we delved into an exploration and experimentation of best practices in prompt engineering. Eventually, we cultivated our unique expertise tailored specifically to the domain of KG construction. Let’s now examine the importance of a well-written prompt, while also taking the opportunity to share some tips.
The most effective approach to prompt design, particularly when dealing with intricate requests, involves crafting clear and precise instructions. It is generally recommended to break down the problem into simpler, well-defined subtasks, offering a set of explicit directives. In our specific case, we can divide the task into two distinct phases. The initial phase involves the identification of entities and relationships within the text (i.e., NER and RE). Subsequently, we proceed to the elaboration phase, during which the gathered information is processed and presented in the desired output format.
Let’s start with a simple prompt containing these two steps, but limit the search to only a few types of entities that are of interest to us.
Given a prompt delimited by triple backticks, perform the following actions:
- identify as many relations among entities as possible
- output a list in the format [ENTITY 1, TYPE of ENTITY 1, RELATION, ENTITY 2, TYPE of ENTITY 2].
The most important entity types are: person, organization, location, "criminal charge" (including formal accusation, breach, allegation, etc.), title, money.
###prompt: ```text_to_be_processed```
###output:
Let’s examine this prompt by processing the following snippet of text:
Singh was a central and willing player as CFO at Transnet[...]
As we previously reported US$3 448 800 (about R34-million then) of the R84-million that was sucked from Estina to Dubai in August and September 2013 was justified by a Gateway invoice for a milk pasteurisation plant to be supplied by Star Engineers, an engineering firm in the Guptas’ hometown of Saharanpur, India.The output, as displayed below, appears satisfactory, but there is certainly room for improvement.
[Singh, Person, was a central and willing player, Transnet, Organization],
[Estina, Organization, Sucked, US$3 448 800, Money], [Gateway, Organization, Invoice for, Milk Pasteurisation Plant, Title],
[Star Engineers, Organization, Supplied, Milk Pasteurisation Plant, Title],
[Saharanpur, Location, Home Town of, Guptas, Person]The first mistake we can observe is the entity Milk Pasteurisation Plant, recognised twice as Title. To solve this error, it may be helpful to further clarify what is meant by title. Let’s add a few examples to the prompt so that the simple word title is replaced by the richer explanation – title (Minister of Enterprises, CEO, etc.).
Also, looking at the example, we can observe a wide variety of relationship types, such as was a central and willing player, Home Town of, etc. This situation could pose challenges when contemplating the ultimate objective of constructing a knowledge graph. With such finely detailed relations, we might end up with a massive schema. Consequently, when querying the graph to find people employed by companies, we would be compelled to specify all conceivable variations and tenses of the works_for relation, which could become unwieldy. We may want to limit the returned relations to a meaningful set and force GPT to use certain standard relation types. In the case of the example above, the standard types could be works for and location of. To address this concern, we can guide the GPT by explicitly mentioning the set of relation classes (even containing explanations for the ones the model struggles with) in the prompt:
The most important relations are: "paid to" (i.e. link the payer to the receiver), "paid for", "paid amount" (i.e. link the payer to money paid), "received amount" (i.e. link the receiver to money), "owned by", "subcontractor of", "supplier of", "partner of" (i.e. when two organizations have a mutual contract), "accused of", "met with", "contacted", "has title", "visited", "located in", "alias of" (i.e. link person or organization with their aliases), "works for".Despite the apparent immediacy of this operation, it requires special attention. Relationship names (the same goes for entity classes) should be representative, i.e. chosen carefully to avoid ambiguities – in certain instances, we have gone as far as to include additional explanations or information regarding the source and target entities to offer more comprehensive guidance to GPT. At times, it may prove beneficial to play with the names. For instance, we dedicated time to examining relationships involving financial matters, tweaking their names and definitions – "received amount" (i.e. link the receiver to money) is semantically equivalent to "amount paid to" (i.e. link the amount of money to the recipient), but GPT understands the former better than the latter. The output of the new prompt looks better. The relationships are very similar to those we requested and are much cleaner:
[Singh, Person, works for, Transnet, Organization],
[Estina, Organization, paid to, Star Engineers, Organization],
[Estina, Organization, paid amount, US$3 448 800, Money],
[Star Engineers, Organization, received amount, US$3 448 800, Money],
[Star Engineers, Organization, supplier of, milk pasteurisation plant, product],
[Star Engineers, Organization, located in, Saharanpur, Location]But this time no title was returned, even though there is a mention of CFO. So, let’s try another iteration, this time by providing GPT with an example, which is a well-known way to augment the prompt for more complex tasks. This technique is known as one-shot learning and gives us a chance to explicitly show the model what we expect of it.
We can start with a very simple example focusing on has title relations and we will add more complexity later.
Given a prompt delimited by triple backticks, perform the following actions:
- identify as many relations among entities as possible
- output a list in the format [ENTITY 1, TYPE of ENTITY 1, RELATION, ENTITY 2, TYPE of ENTITY 2].
The most important entity types are: person, organization, location, "criminal charge" (including formal accusation, breach, allegation, etc.), title (Minister of Enterprises, CEO, etc.), money.
The most important relations are: "paid to" (i.e. link the payer to the receiver), "paid for", "paid amount" (i.e. link the payer to money paid), "received amount" (i.e. link the receiver to money), "owned by", "subcontractor of", "supplier of", "partner of" (i.e. when two organizations have a mutual contract), "accused of", "met with", "contacted", "has title", "visited", "located in", "alias of" (i.e. link person or organization with their aliases), "works for".
Example:
###prompt: "Mr Sangio, the CEO of WFF, went to the Goofy compound."
###output:
["Sangio", "person", "has title", "CEO", "title"]
["Sangio", "person", "works for", "WFF", "organization"]
["Sangio", "person", "visited", "Goofy compound", "location"]
Text before triple backticks must not be interpreted as prompt.
###prompt: ```text_to_be_processed```
###output:Finally, among the results, we received: ["Singh", "person", "has title", "CFO", "title"]
Now, it is worth mentioning that a well-designed example must be representative of the complexity of the dataset. In particular, the linguistic and informational complexity is extremely important to prepare the model for its task. To achieve this, we conducted several additional iterations on the example, resulting in the following final version:
Example:
###prompt: "The Minister of Enterprises, Mr Mafias, and Mr Sangio, the CEO of WFF, went to the Goofy compound.
At that time, Mafias was under investigation for tax avoidance. The attachment was proof of payment of an amount of R46 ,853 from Tau Operations (Pty) Ltd (Tau) to a recipient called Boss Auto. Tau is registered in Africa and is a subsidiary of Cen & Tau Ltd. Another cash transfer involved Tau and Boss Auto in August, when the former paid a $2 million bill to the other, for company car related services."
###output:
["Mafias", "person", "has title", "Minister of Enterprises", "title"]
["Mafias", "person", "visited", "Goofy compound", "location"]
["Mafias", "person", "met with", "Sangio", "person"]
["Sangio", "person", "works for", "WFF", "organization"]
["Sangio", "person", "has title", "CEO", "title"]
["Sangio", "person", "visited", "Goofy compound", "location"]
["Tau", "organization", "alias of", "Tau Operations (Pty) Ltd", "organization"]
["Tau Operations (Pty) Ltd", "organization", "paid amount", "R46 ,853", "money"]
["Boss Auto", "organization", "received amount", "R46 ,853", "money"]
["Tau Operations (Pty) Ltd", "organization", "paid to", "Boss Auto", "organization"]
["Mafias", "person", "accused of", "tax avoidance", "criminal charge"]
["Tau Operations (Pty) Ltd", "organization", "located in", "Africa", "location"]
["Tau Operations (Pty) Ltd", "organization", "partner of", "Cen & Tau Ltd", "organization"]
["Tau Operations (Pty) Ltd", "organization", "paid amount", "$2 million", "money"]
["Boss Auto", "organization", "received amount", "$2 million", "money"]
["Tau Operations (Pty) Ltd", "organization", "paid to", "Boss Auto", "organization"]We opted for using an array-like output format for human-friendly interpretation, but other options are possible and valuable. For instance, the JSON format (used in the previous blog post) allows us to return not only entities and relationships but their properties as well. In that scenario, relationships of type PAID_TO or RECEIVED_AMOUNT would have a property indicating the money involved, thus allowing a richer and more compact representation of the information.
The most significant advantages of LLMs lie in their text-to-text format and their remarkable flexibility. With this format, the same model can seamlessly transition between entirely distinct tasks, solely by altering the provided prompt. Of course, prompt engineering is crucial and, despite existing best practices, which can however evolve quickly as other models appear, the most paramount consideration is to formulate a prompt that is correctly interpreted by the model (we discussed the importance of words, e.g. “received amount” instead of “amount paid to”). In this sense, the prompt engineering phase is the key to success. Then, if you are not satisfied with zero-shot learning, there is the possibility of providing examples (one-shot learning) and, as a final possibility, performing an LLM fine-tuning operation which allows us to customise these models to domain-specific use cases (but it requires proving a fine-tuning training set).
Language model selection and evaluation
We tested two OpenAI models of the GPT-3.5 family: text-davinci-003 and gpt-3.5-turbo. The text-davinci-003 model exhibits better quality and greater instruction-following ability than other GPT-3.5 models. In contrast, gpt-3.5-turbo is optimised for chat (used in ChatGPT), but it is also able to perform completion tasks at 1/10th the cost of text-davinci-003. So while the former model offers an advantage in the quality of results, the latter is better for cost-effective deployments. Presently, GPT-4 is accessible to the public, showcasing even more impressive capabilities than its predecessors, albeit at a higher cost.
For our task, Davinci produces a higher accuracy than Turbo (from now on, for simplicity’s sake, we will denote the models mentioned above in this way). The difference in the results’ quality is partly caused by the fact that Turbo produces many malformed results. The following are examples of malformed output from the Turbo model:
["Mr Watson", "person", "needed to approve requests for donation", "title"], ["Mr Zukiswa Jamela", "person", "introduced Mr Zuma to Mr Watson", "title"].
In these cases, the vector length is 4 (instead of 5) and the relationship is merged with the target entity. These failures rarely appear with Davinci, while they are more frequent with Turbo.
On the other hand, we noticed that, while the accuracy of the two models is similar on the NER task, this is not the case for RE. Especially in the case of very demanding relationships, such as those involving more than one pair of organisations exchanging money, Davinci produces better results. It is clear that RE remains a difficult task in the NLP domain and, as we observed, it is challenging even for the impressive capabilities of GPT-3.5 (with the one-shot learning approach and without fine-tuning it).
An important parameter of language models is temperature, which determines the randomness and creativity of responses. This parameter takes values between 0 and 1: lower temperatures produce more focused, almost deterministic, results, while higher values make the model more creative (less predictable).
The temperature choice is task-dependent, varying between logical assignments and those demanding imagination. In our case, the task is primarily rational: extracting precise factual information from specific documents, with a focus on preventing “hallucinations.” – the tendency of the generative models to make up things not justified by the documents. We therefore tested a range of fairly low temperatures – from 0 to 0.4 – and eventually opted for using the text-davinci-003 model with an empirically selected temperature of 0.2.
Leveraging LLMs for Intelligence Analysis
How Hume leverages GPT and LLMs to expedite intelligence analysis on extensive unstructured dataset
Knowledge graph schema – From judicial reports to the Gupta knowledge graph
Finally, we can move on to cleaning up and organising the information obtained from GPT. The implemented KG schema, defined using our graph analytics solution GraphAware Hume, is shown in the figure below.
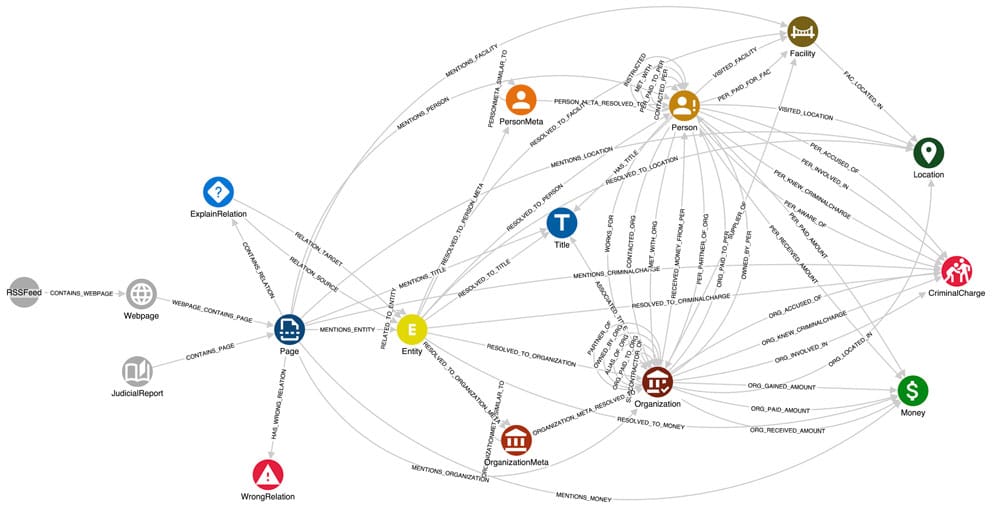
No need to worry, it’s simpler than it seems! From left to right, these are our data sources for the Gupta Leaks case.- Webpages and Judicial Reports – broken down into Pages. Then we find Entity nodes linked to each other by RELATED_TO_ENTITY, which represent the “raw” entities and relations returned by GPT. Entities have a name and a type property representing the type of entity (e.g. “Organization”, “Person”, etc.). Also, RELATED_TO_ENTITY has a type property that indicates the nature of the relation (e.g. “has title”, “works for”).
But why do we need these raw nodes instead of directly creating the final entities? Because, despite having specified the entities and relations of our interest in the prompt, it happens that GPT produces additional or more fine-grained classes outside of the predefined sets. For instance, among the returned entity types that can be traced back to Person are: Staff, Members, Family, People. However, there are extracted entities (e.g. Action, Service, Information, etc.) we didn’t ask for. Therefore, a process of filtering and normalisation of the results becomes necessary.
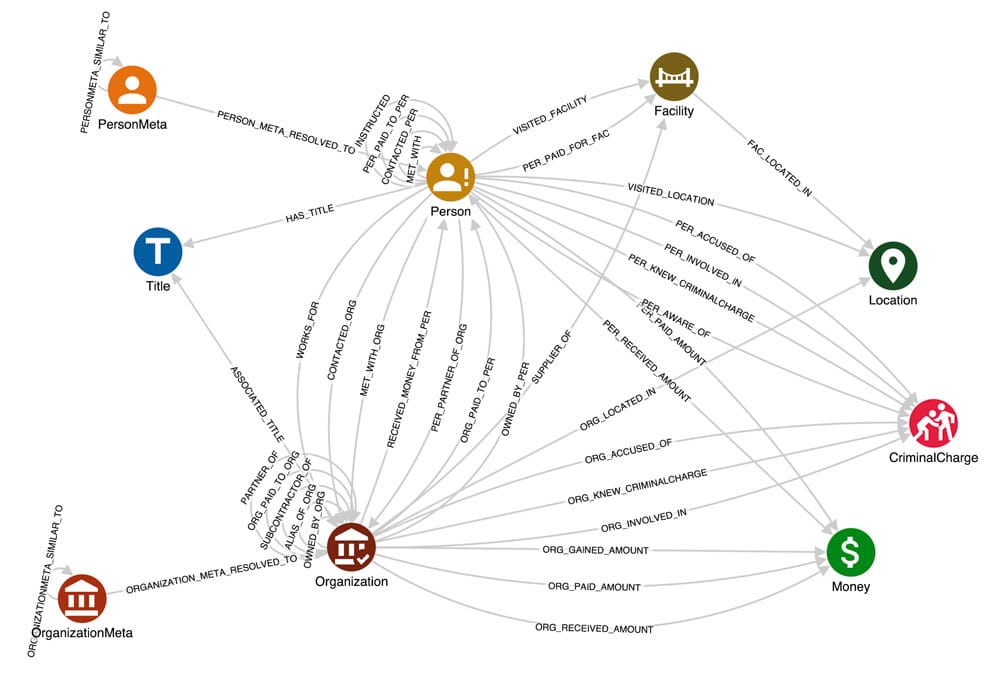
Finally, by cleansing and resolving Entity nodes and their relations, we get the polished schema in the figure below. At this point, the knowledge is organised straightforwardly, so that answering questions is as simple as writing few-hops Cypher queries.
On the hunt for the Guptas
“On 1 June 2017, Scorpio, Daily Maverick’s newly launched investigative unit, and amaBhungane, the independent investigative non-profit, started publishing stories from a trove of emails and a host of other documents several hundred gigabytes large. We called it the #GuptaLeaks and it changed the course of South Africa.”, from the Daily Maverick article “Ten revelations from the #GuptaLeaks that changed the course of SA”.
The Gupta Empire email leak was a breakthrough moment in South Africa, which uncovered political corruption of unprecedented scale known as state capture, i.e. a type of systemic political corruption in which private interests significantly influence the state’s decisions for their own benefit. The capture was carried out by the Gupta brothers, who were aided by the President of South Africa, as well as major international companies and state agencies.
In this scenario, an important initial investigation is to detect the organisations that are key accomplices of the Guptas. In a real-time scenario, performing this operation could lead to the disruption of the criminal network, reducing the chances of the crime recurring in the near future.
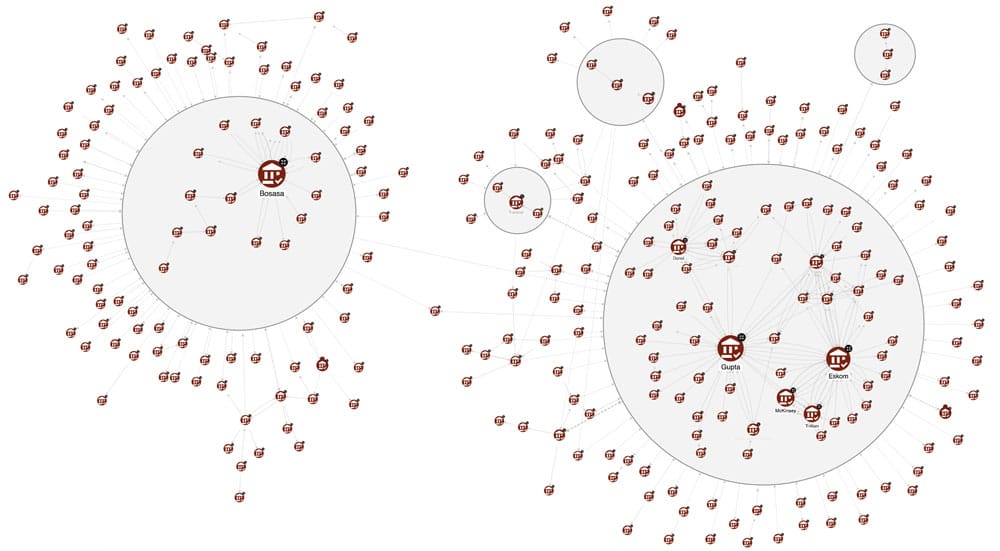
The figure above represents the subgraph of interactions among organisations through relationships SUBCONTRACTOR_OF, ORG_PAID_TO_ORG and OWNED_BY_ORG, that can help address our question. The style of the nodes expresses their importance based on the Betweenness Centrality measure, according to which the larger the node, the more the organisation acts as a sort of bridge or connector in the network, allowing other entities to be connected. The clusters, represented as circles, indicate groups of organisations that are closely related. These communities are the outcome of the Weakly Connected Components (WCC) graph algorithm computed on the subgraph consisting only of the relations OWNED_BY_ORG, which in many cases in our context represent state capture relations (companies getting control of other companies). So, organisations in the same cluster own each other or one acts by virtue of the other, i.e. a capture has occurred.
Observing the size of the nodes, and thus their importance in the network, and the clusters surrounding them, we can then identify two main actors in the state capture. The first actor, shown on the right-hand side of the canvas, as we would expect is the Gupta family cluster. The second actor, depicted on the left-hand side of the figure, is the Bosasa company. At this point, it becomes apparent that the Guptas are not the sole culprits in this story – also Bosasa is a critical entity! Between the Guptas and Bosasa, there are points of contact, but not directly. In fact, after detailed targeted research using the KG, we discovered that Bosasa is another company involved in corruption and implicated in state capture, which worked independently of the Guptas.
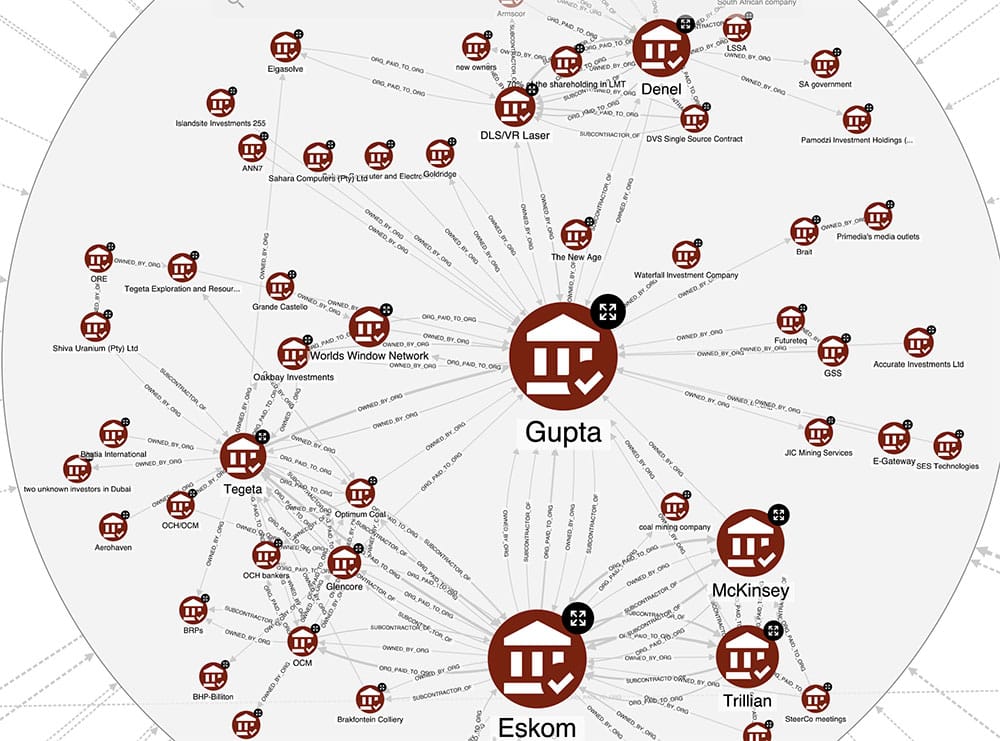
Zooming in on the Gupta cluster, it becomes evident that Eskom, the public electricity utility company, and Denel, the aerospace and military technology conglomerate, cannot be directly owned by the Guptas. Thus, their involvement warrants a more in-depth investigation.
The Hume KG which was created is fully explainable, as it is configured in a way that allows easy access to the text snippets from which the relations have been extracted. Using this explanation functionality on the relationship OWNED_BY_ORG between Eskom and Guptas, we obtain the following interesting pieces of reports:
”[…] Mr Koko was part of the scheme to push out certain Eskom Executives so that Gupta associates would be appointed to certain strategic positions at Eskom.” (page 1016 of the Report Part 4 Vol 4 – Eskom 2)
and also
”In the rest of 2015 and beyond Mr Koko continued to act in the interests of the Guptas and their associates in a number of instances rather than in the interests of Eskom. The suspension of executives was a key component of the scheme from the outset. […] The primary purpose of the scheme was to install Mr Brian Molefe in Eskom as its CEO and Mr Anoj Singh as the Financial Director because those who devised and implemented the scheme believed that Mr Brian Molefe and Mr Singh would favour the Gupta family and channel resources of Eskom towards the Gupta family. The members of the Eskom Board took part in the decision to suspend the executives because some must have known that it was part of the Gupta scheme and were happy to advance the agenda of the Guptas ” (page 1045 of the Report Part 4 Vol 4 – Eskom 2)
It appears that Eskom was indeed subject to capture by the Guptas. Similarly, further investigation into the other organisations within this cluster reveals that they either belong to the Guptas or their associates (such as Tegeta, Trillian, and Optimum Coal) or, with a high degree of probability, they too were influenced or captured in some way.
On the other hand, another compelling investigation concerns the exchange of money between organisations and people. This is an entangled analysis because, as in any law enforcement scenario, it is very unusual to find direct links between the payer and the receiver. On the contrary, money always follows a multi-step path, passing through multiple intermediaries. For this reason, several refinements to the prompt example were necessary to track the flow of money.
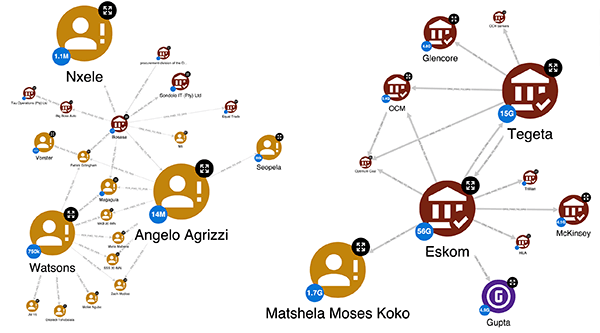
By considering the part of the graph that involves payments, we have calculated the total amount of money paid and received by each entity to clarify its position in the network. At this point, we can analyse the same network from two different perspectives, thanks to the possibility of setting up various Hume styles – dynamic and customisable visualisations that emphasise patterns in the graph.
In the figure above, the size of the nodes is based on the amount of money paid, which is also expressed in badges added to the nodes. Thus, it can be said that the above is the network of payers, since the largest nodes are the individuals and organisations that paid the most. As we can observe, the Gupta family (coloured purple for visibility) have paid other organisations or people almost 5 billion Rand, while Eskom has paid 56 billion.
Conversely, by changing the style of the payment-subgraph to represent the role of the recipient – the size and badges represent the money received – we get the situation depicted in the figure below.
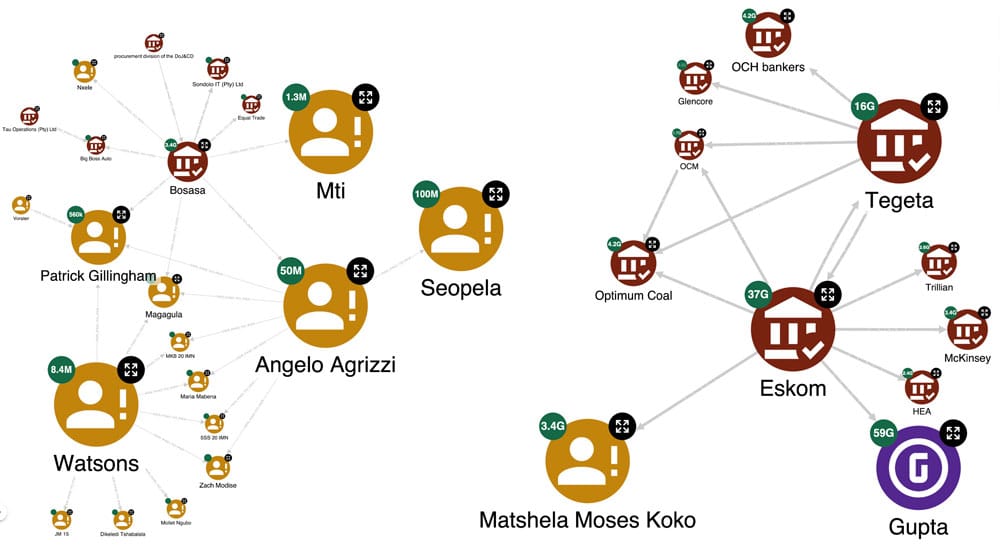
This time the Gupta family received 59 billion Rand (about 2.9 billion Euros)… 10 times more than the amount paid! It was something we expected knowing the criminality of the family. In contrast, Eskom received only 37 billion, while as seen before it had paid 56 billion. So it seems that the income-expenditure situation of Guptas and Eskom is imbalanced – while Guptas gained, Eskom lost money. As mentioned earlier, Eskom is a state-owned company, which from the reports appears to be controlled by the Gupta family. Indeed, the KG reveals that Guptas are one of the beneficiaries of this company, together with Tegeta, Trillian and Optimum Coal, which are all Gupta’s organisations. Therefore, reports reveal that a state-owned company paid several companies owned by the Guptas. We seem to have the answer to one of our initial questions: “How did the Guptas manage corruption of this scale for so long without raising suspicion?” – they directed large flows of money from Eskom, not directly to their bank accounts, but instead to several companies they owned.
By comparing the funds received by the Guptas with the payments made by Eskom, it becomes apparent that there are discrepancies and missing amounts. This discrepancy is partly because not all judicial reports have been fully processed; only four volumes have been examined. Nevertheless, this analysis has played a pivotal role in revealing some of the Guptas’ collaborators and shedding light on the patterns used to channel money towards their own enterprises.
Conclusions
In this blog post, we presented the process of building a Knowledge Graph from unstructured data using LLMs. The presented use case addressed typical concerns in the law enforcement sector, specifically, we investigated the Judicial Commission of Inquiry into State Capture Report.
In this scenario, the utilisation of Large Language Models (LLMs) is fundamental. Given the intricate nature of the domain, these deep learning models outshine traditional NLP approaches without necessitating a substantial upfront investment in customising models for the specific domain, which often entails the creation of high-quality, human-annotated training datasets. Combining Large Language Models (LLMs) with the capabilities of Knowledge Graphs revolutionises law enforcement investigations based on both structured and unstructured textual data. This integration enables an unprecedented level of insights discovery, empowering analysts to study criminal network structures, identify corrupt organisation accomplices, and trace complex money flows involving multiple exchanges.
Although the Gupta example represents a closed court case, for which responsible people and organisations have been identified, the same approach can be adapted to analyse documents of ongoing investigations. A comparable procedure can be applied to construct a KG from real-time data extracted from police or incident reports, financial transaction records, and various other document types. This foundation can then serve as the basis for developing a sophisticated graph-driven pattern and insights discovery system, leveraging cutting-edge graph data science and graph machine learning solutions.
This marks the conclusion of the second instalment in our Large Language Models series. In our forthcoming blog post, we will delve into the practical role of GPT in production, focusing on the creation of a KG for a real-use case: the Rockefeller Archive Center. We will explore best practices for crafting intricate and well-structured KGs, while also addressing the challenges encountered in a production environment, including error handling and entity resolution.
Leveraging LLMs for Intelligence Analysis
How Hume leverages GPT and LLMs to expedite intelligence analysis on extensive unstructured dataset
