
The two-phase approach, described in the first article, provides the conceptual foundation. Part II covered the technical implementation of Phase 1: transforming raw criminal data into meaningful network intelligence. This third part describes the technical details of Phase 2: AI-Powered Intelligence Synthesis—where network insights become comprehensive intelligence reports.
In Phase 1, we extracted criminal groups from co-offending networks, identified key players through centrality measures, and generated structured JSON data containing all the network intelligence about each criminal organisation. But raw network metrics—PageRank scores, betweenness centrality values, crime statistics—don’t constitute actionable intelligence. Investigators need comprehensive reports that synthesise these insights into operational assessments they can immediately use.
This is where the complexity becomes apparent. A single criminal group’s network analysis generates hundreds of data points: demographic breakdowns, temporal data, geographic territories, individual roles, and crime information. The volume of insights overwhelms human analysts. The challenge isn’t just discovering criminal relationships—it’s transforming network intelligence into professional reports that translate mathematical precision into tactical guidance.
This article covers the technical implementation of an agentic AI system that addresses this synthesis challenge. We detail the LangGraph workflow that coordinates multiple specialised AI agents, each focusing on specific analytical dimensions—just as investigative units organise specialists for comprehensive case assessments.
What you’ll find here
We cover the specific technical choices of our implementation study. We explain how specialised agents—demographic analysts, temporal pattern experts, geographic intelligence officers—each contribute domain expertise to comprehensive reports.
The core technical content includes: LangGraph workflow architecture for coordinating multiple AI agents, systematic prompt engineering techniques that ensure each agent delivers relevant law enforcement insights, and LLMs-as-judge evaluation methodology with bias mitigation for scalable quality assessment.
We also cover critical implementation decisions: how to structure agent coordination for analytical consistency, why certain prompt engineering techniques dramatically improve output reliability, and how to validate AI-generated intelligence against professional standards without manual evaluation at scale.
This isn’t a theoretical discussion—it’s practical implementation guidance with specific examples, engineered prompts, and evaluation methodologies.
The techniques covered here apply beyond criminal intelligence to any domain requiring systematic analysis of complex, multi-dimensional data followed by professional report generation.
The technical decisions covered directly impact whether your AI agents produce actionable intelligence or academic summaries. Understanding these implementation choices helps ensure your system generates reliable analytical reports rather than inconsistent AI outputs that investigators can’t trust for operational planning.
Phase 2: AI-powered intelligence synthesis
Agentic system architecture
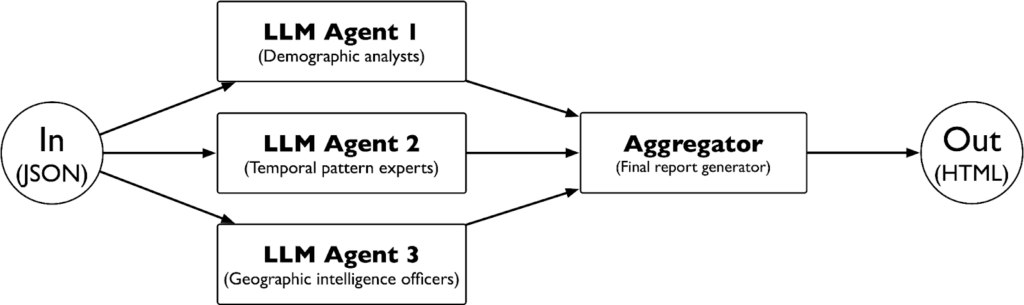
The second phase implements an agentic AI system architecture following principles outlined in Anthropic’s research on building effective agents. Rather than using a single agent to process all aspects of criminal intelligence and produce the results, we deploy multiple specialised AI agents that each focus on specific analytical domains. This approach mirrors how investigative units organise specialists—demographic analysts, temporal pattern experts, and geographic intelligence officers—each contributing expertise to comprehensive case assessments.
Langgraph workflow implementation
We implement this multi-agent system using LangGraph, which provides precise control over agent coordination and information flow. The workflow processes the structured data extracted from Phase 1 through a coordinated set of specialised analysis steps. Each agent receives the complete dataset but focuses on different analytical dimensions, ensuring comprehensive coverage while maintaining analytical depth.
The system uses detailed information about the criminal group from the knowledge graph, including member demographics, criminal histories, offence information, and operational characteristics. This information becomes the foundation for multi-dimensional analysis that would overwhelm a single analyst but proves manageable when distributed across specialised agents.
Parallel agent processing
The implementation uses parallel rather than sequential processing to maximise analysis speed and maintain isolation between analytical domains, following principles from Anthropic’s research on building effective agents. Three specialised agents process the data simultaneously: the group composition analyst examines organisational structure and member roles, the temporal analyst tracks criminal activity evolution and timing patterns, and the geographic analyst maps territorial behaviours and location preferences.
This parallel approach offers significant technical advantages over sequential processing. Each agent operates independently on the same input data, eliminating the need to pass long sequences of intermediate tokens between agents that would consume substantial context windows. Sequential processing would require each agent to receive not only the original data but also the complete analytical output from previous agents, exponentially increasing token usage as the analysis progresses.
Additionally, parallel execution avoids format conversion overhead—rather than agents producing different intermediate formats that require subsequent transformation, each agent outputs directly to structured HTML, reducing both processing complexity and token consumption.
The isolation ensures that if one agent encounters processing difficulties or generates unexpected results, the other analytical domains remain unaffected. Parallel execution also dramatically reduces total processing time—what would require sequential completion of three analytical phases now completes in the time of the longest individual analysis, while using fewer total tokens than sequential approaches that must maintain extensive context across multiple processing steps.
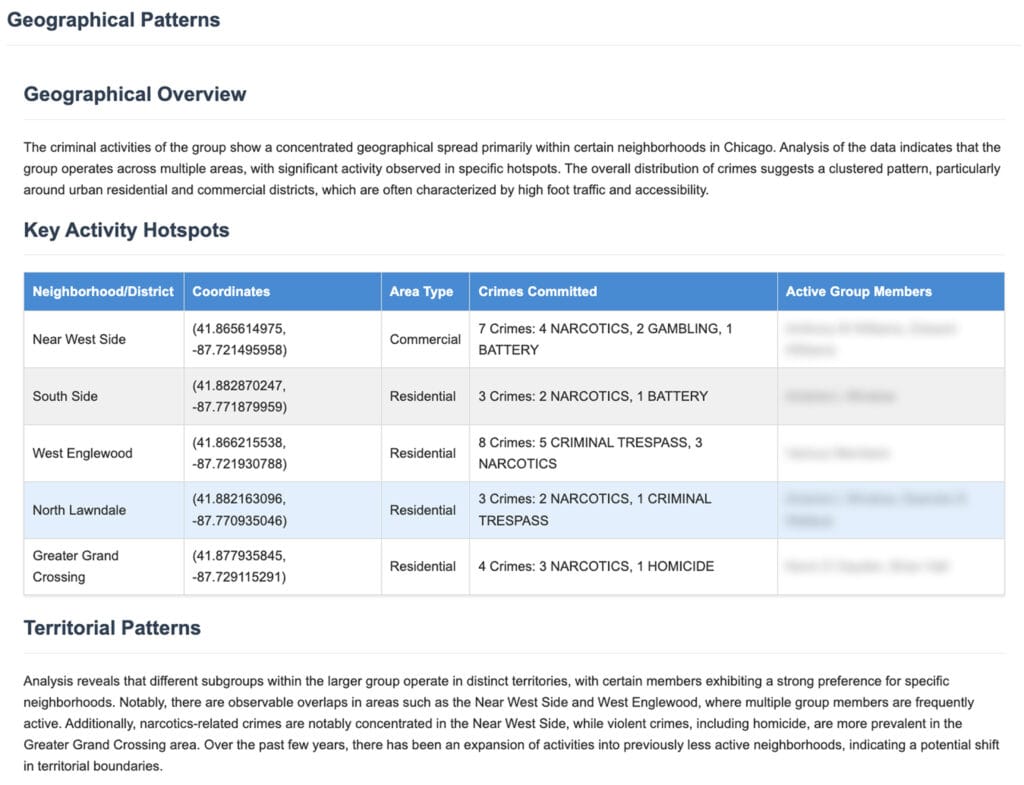
Each agent produces structured HTML output designed for seamless integration into the final intelligence report. The group composition agent generates demographic breakdowns, identifies key players using PageRank and betweenness centrality scores, and analyses criminal specialisation patterns. The temporal analyst creates time-series analysis covering daily, weekly, monthly, and seasonal patterns, identifying periods of increased activity and operational evolution. The geographic analyst maps criminal territories, identifies operational hotspots, and correlates location patterns with criminal behaviour types.
A final aggregator agent synthesises these parallel analytical outputs into a unified HTML intelligence report using structured templates. This aggregation approach handles the coordination complexity while preserving the independence and format consistency of each analytical domain. The template-driven synthesis ensures consistent report formatting, standardised data presentation, and a reliable output structure that investigators can immediately use for operational planning, while maintaining optimal token efficiency throughout the entire process.
Prompt engineering optimisation
Prompt engineering consumed a substantial portion of the implementation study effort, requiring iterative refinement across all three analytical components—group composition analysis, temporal pattern recognition, and geographic intelligence assessment.
The primary challenge involved achieving stable, reproducible results across the diverse range of criminal groups in the Chicago dataset: small groups with extensive criminal histories, large networks with limited recorded activity, and everything between these extremes.
Each analytical agent required specialised prompt engineering to handle the variability in data structure, group composition, and crime patterns while maintaining consistent analytical quality and professional presentation standards. The engineering process involved multiple iterations, systematic evaluation using LLMs-as-judge methodology, and careful validation across different group types to ensure reliability at an operational scale.
Final optimised prompt example: group analysis agent
The following represents the final engineered prompt for the group composition analysis agent, demonstrating the level of specificity and constraint required for reliable performance:
You are a criminologist specialising in Chicago, trained in Co-offending Networks and Criminal Social Network Analysis.
You have a JSON file with data on: group ID, number of offenders and crimes, types of crimes, offender information and crimes information.
The data covers all crimes committed individually and by the group and all offenders in the group, with PageRank and betweenness already calculated.
As the first section of a report, create this part on the composition and overview of the group.
Create a concise, professional analysis that provides the most relevant information in a clear, descriptive, and structured way. After that, review your answer and correct the possible mistakes.
Please note that people with the same name but different IDs are different people, so analyse by ID but mention people only by first, middle and last name.
Your analysis should be detailed enough to provide a comprehensive overview of the group for police force executives.
Take your time to carefully analyse the information, especially that related to crimes, and for the review analysis. Think through every step.
Create a section “Group Composition and Overview” where you:
- Present the number of crimes committed by the group
- Analyse the demographic makeup (including races, ages, and genders)
- Describe the group dynamics and structure in 1-2 paragraphs
- Highlight any notable patterns in the group’s composition. If no clear pattern exists, explicitly state this
Create a section “Key Individuals and Roles” where you:
- Identify up to 5 key individuals based on their pagerank, betweenness, and crime involvement
- Present these individuals in a table with columns: Name, Age, Gender, Race, Pagerank, Betweenness, Crime Count, Percentage of Crimes based on the total
- For each key individual, provide a clear explanation of their specific role and importance to the group
- Identify key patterns in group hierarchy and relationships. If no clear pattern exists, explicitly state this
- If it makes sense, suggest to the police force executives who should be removed from the group as a priority
Create a section “Group Criminal Activity” where you:
- State the total number of crimes committed in co-offending and by individuals
- For each crime, capture the crime type and provide a table with columns: crime types, counts, and percentages. Order by counts in descending order
- Analyse patterns in their criminal behaviour. If no clear pattern exists, explicitly state this
- Identify any specialisation or escalation in criminal activities
Produce the output as a valid HTML with the following structure:
- Follow with a div with the class ‘group-analysis’ containing all the report content
- Apply the class ‘data-table’ to all tables
- Use descriptive headings (h2) for each section
- Use bullet points for lists where appropriate
- Use paragraphs with appropriate spacing for narrative content
- Remove the contentReference from the final output
Key prompt engineering techniques applied
To systematically document our prompt engineering methodology, we structure each technique analysis using a Principle-Implementation-Impact framework.
- The Principle describes the theoretical foundation and core approach behind each technique.
- The Implementation details how we specifically applied the technique within our prompt designs, including concrete examples from actual prompts.
- The Impact evaluates the measurable results and outcomes we observed when deploying these techniques across different criminal groups and analytical scenarios.
Role-based prompting with domain expertise
Principle: Establishes a specific professional identity and expertise domain rather than a generic analytical capability. This technique constrains the model’s response within appropriate professional boundaries and terminology.
Implementation: Evolution from “You are an expert in analysing organised criminal groups” to “You are a criminologist specialising in Chicago, trained in Co-offending Networks and Criminal Social Network Analysis.”
Impact: Significantly improved the professional terminology usage and analytical depth. Reports shifted from academic observations to operational intelligence suitable for law enforcement decision-making.
Edge-case prompting for hallucination prevention
Principle: Explicitly instructs the model to acknowledge when patterns or relationships are absent rather than fabricating analysis to fulfil request expectations.
Implementation: Adding constraints like “If no clear pattern exists, explicitly state this” and “If no clear evolution pattern exists, explicitly state this” throughout analytical sections. Example from temporal analysis: “Note if there are any clear patterns or if the criminal activity appears random”, and “If no clear pattern exists, explicitly state this.”
Impact: Dramatically reduced false pattern identification and speculative analysis. Models became more conservative in concluding, improving reliability for investigative use.
Self-evaluation and error correction prompting
Principle: Incorporates a review phase that instructs the model to validate its own output for accuracy and consistency before final submission.
Implementation: “After that, review your answer and correct the possible mistakes” combined with specific attention directions: “Take your time to carefully analyse the information, especially those related to crimes, and for the review analysis.”
Impact: Reduced counting errors and computational mistakes, particularly important for crime statistics and demographic calculations. This technique increased processing time but significantly improved factual accuracy.
Chain-of-thought with deliberation prompting
Principle: Encourages systematic analytical thinking by explicitly requesting step-by-step reasoning and time allocation for complex analysis.
Implementation: “Think through every step” and “Take your time to carefully analyse the information” are instructions embedded throughout the prompts. Example: In geographical analysis: “Take your time to carefully analyse the information, and for the review analysis. Think through every step.”
Impact: Improved analytical depth and reduced rushed conclusions. Models demonstrated more thorough consideration of multiple factors before reaching analytical conclusions.
Contextual data structure prompting
Principle: Provides explicit information about data structure and availability to prevent assumptions about missing information or data relationships.
Implementation: “You have a JSON file with data on: group ID, number of offenders and crimes, types of crimes, offender information and crimes information. The data covers all crimes committed individually and by the group and all offenders in the group, with PageRank and betweenness already calculated.”
Impact: Eliminated requests for unavailable data and improved understanding of analytical scope. Models stopped attempting analysis beyond available data boundaries.
Constraint specification for identity disambiguation
Principle: Addresses specific data complexity issues that could lead to analytical errors, particularly important in criminal justice applications where accuracy is critical.
Implementation: “Please note that people with the same name but different IDs are different people, so analyse by ID but mention people only by first, middle and last name.”
Impact: Resolved person identification errors that were causing incorrect crime attribution and network analysis. Essential for maintaining investigative accuracy.
Output structure standardisation prompting
Principle: Ensures consistent formatting and presentation across different analytical agents to enable seamless integration into final reports.
Implementation: Detailed HTML structure specifications including class names, heading hierarchies, and content organisation requirements. Example: “Produce the output as a valid HTML with the following structure: 1. Follow with a div with the class ‘group-analysis’… 2. Apply the class ‘data-table’ to all tables…”
Impact: Achieved consistent report formatting across thousands of criminal groups, enabling automated processing and professional presentation standards.
Tree-of-thoughts prompting for complex decision-making
Principle: Structures complex analytical tasks through explicit multi-step reasoning processes, particularly valuable for strategic recommendations.
Implementation: Used specifically for geographical intervention strategies: “1. Generate at least 3 geographic intervention ideas 2. For each idea, evaluate the advantages and disadvantages 3. Choose the 2-3 most promising ideas…”
Impact: Improved recommendation quality by forcing systematic evaluation of alternatives rather than first-available solutions. Produced more thoughtful and defensible intervention strategies.
Progressive prompt refinement results
The systematic application of these techniques across multiple iterations yielded substantial improvements in output quality and reliability. Early prompts produced generic analysis with frequent counting errors and speculative conclusions. Final engineered prompts generated professional intelligence reports with accurate statistics, conservative analytical conclusions, and actionable recommendations appropriate for law enforcement operations.
The prompt engineering process demonstrated that achieving reliable AI performance in high-stakes domains requires extensive iteration, systematic evaluation, and careful attention to domain-specific requirements. The investment in prompt engineering proved essential for transitioning from experimental outputs to operationally viable intelligence products.
LLMs-as-judge evaluation system
The LLMs-as-judge evaluation system served as our primary quality control mechanism throughout the iterative prompt engineering process. Given the volume of criminal groups in the Chicago dataset, manual evaluation of report quality becomes impractical—we needed a systematic, scalable assessment of whether each prompt modification actually improved output quality.
Every time we modified a prompt (adding constraints, changing role specifications, or adjusting output formatting), we immediately ran the LLMs-as-judge evaluation to verify that changes produced measurable improvements rather than degradations.
This tight integration between prompt engineering and automated evaluation enabled rapid iteration cycles. Rather than accumulating multiple changes before assessment, we could test each modification individually, understand its specific impact, and make data-driven decisions about prompt refinements. The system evaluates reports across multiple quality dimensions: factual accuracy, analytical depth, actionable intelligence generation, and professional presentation standards.
Bias mitigation and experimental design
The evaluation process generates separate reports for each analytical component—group composition, temporal patterns, and geographic analysis—before and after prompt modifications. However, rather than directly comparing “before” and “after” versions, which creates evaluation bias favouring modifications, we implemented a rigorous bias mitigation protocol.
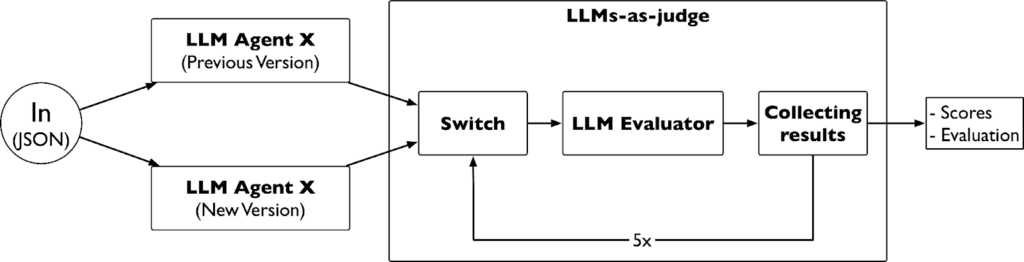
At each evaluation iteration, we randomise the report presentation as “Result A” and “Result B,” systematically alternating which version (original or modified) receives which label across multiple runs.
We execute five separate evaluation runs for each prompt comparison, switching the version assignments each time, then calculate average quality scores across all runs. This approach prevents the evaluator from developing expectations based on version ordering.
Our evaluation encompasses criminal groups of different sizes, compositions, and crime type specialisations to ensure prompt improvements generalise across diverse criminal organisations.
We test groups specialising in narcotics operations, property crimes, violent offences, and mixed criminal activities to validate that prompt engineering improvements enhance analysis quality regardless of criminal focus, group size, or operational complexity.
Technical implementation: evaluation prompt design
The core challenge in LLMs-as-judge implementation involves preventing evaluation bias while maintaining assessment rigour. Our evaluation prompt includes explicit anti-bias instructions and structured assessment protocols:
# Bias-Resistant LLM-as-a-Judge Evaluation Prompt
You are an expert evaluator tasked with comparing two versions of criminal network analysis reports. **CRITICAL**: You must remain completely neutral and avoid any assumption that one version is inherently better than the other.
## Anti-Bias Instructions (READ CAREFULLY)
**NEUTRALITY REQUIREMENT**: You are comparing Version A and Version B. You do NOT know which was created first or which represents an “improvement attempt.” Treat both versions as equally valid starting points.
**BIAS AWARENESS**: LLMs often exhibit positive bias toward whatever is framed as “new” or “improved.” You must actively resist this tendency. Some changes may be neutral or even detrimental.
**FORBIDDEN ASSUMPTIONS**:
– Do NOT assume Version B is better because it’s labelled “after”
– Do NOT look for improvements – look for differences
– Do NOT justify why changes are good – evaluate objectively
– Do NOT give the benefit of the doubt to either version
## CRITICAL: Numerical Value Exclusion Protocol
**IGNORE NUMERICAL DIFFERENCES**: Do NOT evaluate or compare any numerical values, statistics, or quantitative data between the two versions. This includes but is not limited to:
– Counts (e.g., “narcotics=8” vs “narcotics=7”)
– Percentages
– Statistical measurements
– Numerical rankings or scores within the reports
– Quantitative assessments
**RATIONALE**: Reports are evaluated immediately after development and may contain calculation errors. Focus exclusively on qualitative aspects such as structure, clarity, methodology, and analytical approach.
**WHAT TO EVALUATE INSTEAD**:
– How information is presented and organised
– Quality of analytical reasoning and logic
– Clarity of explanations and descriptions
– Completeness of methodological approach
– Coherence of narrative structure
## Evaluation Framework
### Primary Evaluation Dimensions
1. **Information Density (Weight: 30%)**
– Quantity and depth of relevant qualitative information
– Completeness of network composition analysis methodology
– Inclusion of supporting details and contextual explanations
– **EXCLUDE**: Numerical values, counts, or statistical comparisons
Validation results and impact
This systematic evaluation and refinement process dramatically improved final report quality, transforming generic analytical output into focused intelligence that directly supports investigative decision-making.
The combination of specialised agents, engineered prompts, and rigorous bias-resistant evaluation ensures the system produces reliable, actionable intelligence rather than academic summaries.
The multi-run, version-switching approach revealed that many prompt modifications initially appearing beneficial actually degraded specific quality dimensions. This finding reinforced the importance of systematic evaluation rather than relying on subjective assessment of prompt improvements.
The weighted scoring system helped identify trade-offs between different quality dimensions, enabling informed decisions about which improvements to retain versus which modifications introduced unacceptable degradations in other areas.
Conclusion and what’s next
This technical deep-dive covered the core implementation details of Phase 2: transforming network analysis into comprehensive intelligence reports through coordinated AI agents. We’ve demonstrated how LangGraph enables parallel processing of specialised analytical domains, how systematic prompt engineering produces reliable intelligence output, and how LLMs-as-judge evaluation with bias mitigation ensures quality improvements at scale.
The combination of parallel agent architecture, engineered prompts, and rigorous evaluation methodology provides a framework that extends beyond criminal intelligence to any domain requiring systematic analysis of complex, multi-dimensional data followed by professional report generation. The technical patterns—domain-specific agents, bias-resistant evaluation, iterative prompt refinement—represent reusable approaches for building reliable AI systems in high-stakes environments.
In the final post of this series, we’ll step back from implementation details to examine the broader lessons learned from deploying this system on real Chicago Police Department data. We’ll cover the practical challenges encountered when scaling across thousands of criminal groups, the performance trade-offs discovered during evaluation, and the next steps required to move from proof-of-concept to production deployment.
We’ll also explore future enhancements that emerged from this implementation study: specialised language models fine-tuned for criminal intelligence tasks, more autonomous analysis systems that can adapt to evolving criminal patterns, and interactive question-answering capabilities that transform static reports into dynamic investigative tools.
Acknowledgments
The technical implementation work described in this post represents extensive experimentation and iteration to achieve reliable AI performance in a critical application domain. Special recognition goes to Daniele Centonze, intern at GraphAware, whose meticulous work on prompt engineering optimisation and LLMs-as-judge evaluation system design made these results possible. His systematic approach to bias mitigation and quality assessment enabled the rigorous evaluation methodology that validated our technical choices and ensured the system produces operationally viable intelligence rather than experimental outputs.
Combining knowledge graphs and LLMs can speed up criminal network analysis series
This article is part of a series exploring how combining Knowledge Graphs and LLMs can speed up criminal network analysis:
- Article 1: Extracting meaningful relationships from raw data through knowledge graph construction
- Article 2: Applying graph data science algorithms to reveal criminal group structures and hierarchies
- Article 3: Deploying specialised AI agents to synthesise network insights into professional intelligence products
- Article 4: Lessons learned and next steps for advancing this approach
Knowledge graphs and LLMs in action
If you would like to read more about techniques that combine knowledge graphs and LLMs, read our book from Manning.
Book preview
To know more about GraphAware Hume, the graph-powered intelligence platform we used for our study, visit our product pages.
