
When developing web applications with frameworks like Vue.js, the best approach is to subdivide them into well-defined and reusable components for the user interface, with the business logic being encapsulated in ‘services’.
In an ideal world, every new feature added should follow this approach, and all components and services should remain at a reasonable size, so that you can quickly glance at each file and understand what it does.
The problem
The reality is usually much less ideal: good principles are followed rigorously when the project is young, but as new features, bug fixes, and different developers accumulate, components and services can become bigger and bigger, and the separation of concerns starts fading.
That happens even more quickly when a visualisation library like d3 is included in the project. Suddenly, the component needs to address many different needs: fetching, filtering and transforming data into the shape expected by the library, handling the library lifecycle and events, orchestrating other controls that somehow ended up in the same component (it’s just a simple checkbox… and a slider… and a little toolbar…)
Many of these concerns could be moved into separate services or components, but after hundreds of lines of code, nobody cares anymore, and code quality rapidly deteriorates.
The solution
Refactoring is the art of changing the shape of source code without changing its functionality. The most common refactorings are:
- rename: classes, methods, properties, parameters…
- extract method: split a long method by moving part of the logic to a new one
- inline: the opposite operation of the extractions
- move method: this is less common, but we will be using it in this tutorial. When a method in a class mostly handles the state of an external object, or of a single property, it’s probably better to move that method inside the class of that object. This will increase encapsulation and readability.
- extract class: this will be the main focus in the next paragraphs. The idea is simple: when a class is doing too much, we create another class and move some of the methods and properties there. In the original class, we add an instance of the new class as a member and we can access the exported functionalities.
In this tutorial, I’ll focus on refactoring a Typescript class. It gives us the advantage of detecting at compile time some of the mistakes possible when moving code around. However, this process can be adapted to any other language.
The struggle
The problem with the extract class is that it’s never clear which members belong to the class and which ones can be moved. This is even more the case when the class is big and maybe written by someone else. So we need a tool to help us identify which groups of members belong together, so we can make the extraction with minimal effort.
Graphs to the rescue
The elements of the problem are perfectly modelled by a graph. We have a class with methods and properties. Every method can access all the members of the class, and that will determine which methods we want to export. If we find a group of nodes that mostly access each other, with minimal dependency on the nodes outside that group, then we have found a candidate class to extract.
In graph theory, such a group is called a community, a very familiar concept when talking about people and social interactions.
Here is the plan:
- We want to put all members of the class into a graph database. In this tutorial, I’m going to use Neo4j.
- For each method which accesses a member of the class, we’ll create a relationship between the corresponding nodes.
- When the graph is prepared, we will use a community detection algorithm to split the members into related groups.
- We will choose the best group to extract into a separate class, and we’ll do the refactoring.
Installation
To install Neo4j, just follow the user documentation. In the following instructions, I’m going to assume that there is an empty Neo4j database accessible at the standard location bolt://localhost:7687.
For the analysis of the generated graph, we will need the Louvain community detection algorithm, which is present in the GRAPH ALGORITHMS plugin available from the Neo4j desktop interface.
We will use a small program that will parse the Typescript code, and we’ll do it in Typescript. You can find the parser tool in this repository.
The parser tool
I’ll briefly explain what the program does, commenting along the code.
import [...] from 'ts-morph';
For the parser, we will use this library: ts-morphAST browser made with it, where you can paste some code and immediately inspect the AST.
import v1 from 'neo4j-driver';
We also import the official Neo4j driver for JavaScript to communicate with the database.
async function asyncForEach<T>(array: T[], mapper: (x: T) => Promise<void>): Promise<void[]> {
return Promise.all(array.map(mapper));
}We will use this function to properly wait for the completion of multiple async operation. This is useful for correctly closing Neo4j sessions and the Neo4j driver connection.
const driver = v1.driver('bolt://localhost', v1.auth.basic('neo4j', 'ts-ast-graph'));
const project = new Project();
This will initialise the database connection and the parser object.
process.argv.slice(2).forEach(file => project.addExistingSourceFileIfExists(file));
const classes = project.getSourceFiles().flatMap(sourceFile => sourceFile.getClasses());
The classes object will be a collection of all the classes present in the passed source files. Our objective today is just to refactor one of them.
const classes = project.getSourceFiles().flatMap(sourceFile => sourceFile.getClasses());
await asyncForEach(classes, async (c: ClassDeclaration) => {
const session = driver.session();
const className = c.getName();
console.log('class name:', className);
await session.run('MERGE (c:Class {name:$className}) RETURN c', {
className,
});
Here we are extracting the name of the class and storing it as a node in the graph. The merge keyword will insert the node only if it isn’t already present, so we can run the program more than once without ending up with duplicate nodes.
c.forEachChild(child => children.push(child));
await asyncForEach(children, async child => {
switch (child.getKindName()) {
The parser will enumerate all the properties and methods of the class. I didn’t take into account static methods and nested classes, both because they are not so frequent (in the projects I’ve seen up until now) and also quite easy to refactor manually.
case 'PropertyDeclaration':
{
const propName = (child as PropertyDeclaration).getName();
console.log('property: this.' + propName);
await session.run(
'MATCH (c:Class {name:$className}) ' +
'MERGE (c)-[:OWNS]->(p:Property {name:$propName}) ' +
'RETURN p',
{ className, propName }
);
}
break;
We store every property in the graph by creating a corresponding node and connecting it to the containing class.
case 'MethodDeclaration':
{
const methodName = (child as MethodDeclaration).getName();
await session.run(
'MATCH (c:Class {name:$className}) ' +
'MERGE (c)-[:OWNS]->(m:Method {name:$methodName}) ' +
'RETURN m',
{ className, methodName }
);Nothing new here, every method will have a node in the graph with the label Method and its name as identifier.
const propertyAccessElements = extractStructure(child, [
'PropertyAccessExpression',
'ThisKeyword',
]);
console.log(
propertyAccessElements.map(
seq =>
' access this.' +
(seq[0] as PropertyAccessExpression).getName()
)
);
await asyncForEach(propertyAccessElements, async seq => {
const accessedPropName = (seq[0] as PropertyAccessExpression).getName();
await session.run(
'MATCH (c:Class {name:$className})-[:OWNS]->(m:Method {name:$methodName}) ' +
'MERGE (c)-[:OWNS]->(p {name:$accessedPropName}) ' +
'MERGE (m)-[:ACCESS]->(p) ' +
'RETURN p',
{ className, methodName, accessedPropName }
);
});
Methods may access other class members anywhere in the AST. So we need to recursively search the method tree if we find a PropertyAccessExpression method whose first child is this. Whenever we find one, we store the accessed member as a node together with an ACCESS relationship between it and the node of the calling method.
Note that at this point, we don’t know if the accessed element is a property or a method: we could find out with a more thorough analysis of the AST, but there is no need. If all properties are declared, then we either have the member node already stored (so the merge command will only match it) or we will encounter it later in the class (so the second merge command will match the member and apply the correct label to it).
function extractStructure(node: Node, kindStructure: string[]): Node[][] {...}
function extractSubStructures(node: Node, kindStructure: string[]): Node[][] {...}That is a quick implementation of a depth-first search in the AST.
That’s all for the parsing code. Let’s execute it:
npm run start <your-class-file.ts>As an example i will use this small class (called demo.ts) in the repository.
class Demo {
someNumber:number;
someString:string;
crossCall(){
console.log(this.multiply(5));
}
accessBoth(){
console.log('hello '+this.someString.repeat(this.someNumber));
console.log(this.someNumber);
}
constructor(n:number,s:string){
this.someNumber=n;
this.someString=s;
}
multiply(x:number){
return x*this.someNumber;
}
squared(){
return this.someNumber*this.someNumber;
}
greet(){
console.log("hello "+this.someString);
}
greetFormally(){
console.log("Good morning "+this.someString);
}
}The graph
After executing the parser on the Demo class, we can open the Neo4j Browser and look at the generated graph.
MATCH (n) RETURN nYou may have to move the graph around a bit to see everything properly. Here’s the resulting graph:
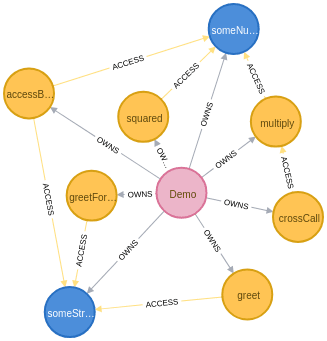
Now we will apply the* *Louvain community detection algorithm to separate methods and properties into groups based on how much they access each other.
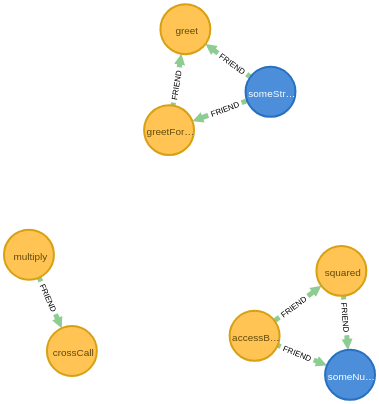
CALL algo.louvain('','ACCESS',{write:true,writeProperty:'community'}) YIELD nodes,communityCount,iterations,loadMillis,computeMillis,writeMillisWe also want to visually see the detected groups, so we will use a technique that exploits the force directed visualization available in the Neo4j browser. What we want is to create relationships that connect all the members of the same communities.
MATCH (m),(n) WHERE m.community=n.community AND m.name<>n.name MERGE (m)-[:FRIEND]-(n)And now we look at the groups. For the next query, it’s better to uncheck the flag ‘Connect result nodes’ in the Neo4j Browser settings panel. This will prevent the browser from showing the ACCESS relations.
MATCH p=(m)-[r:FRIEND|ACCESS]-(n) RETURN pOf course, this is clearly not the best example to demonstrate the power of this algorithm, but it’s small enough to show the process. The results are much better and more useful in bigger classes with more members.
Here is the resulting graph:
Another option is to look at both the ACCESS and FRIEND relationships, which gives more information but is also harder to reason about. To do this, we use this query:
MATCH (m)-[r:FRIEND|ACCESS]-(n) RETURN m,n,rWhich results in this visualisation:
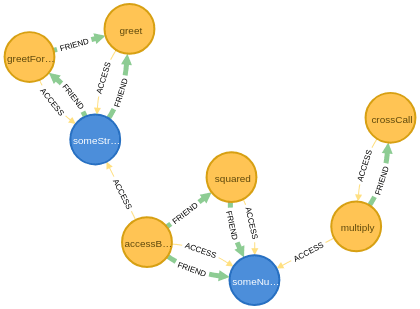
My approach at this point would be to refactor the class, extracting the most independent group, possibly including at least one property.
My choice based on that criterion would be the greet and greetFormally methods and someString property. By doing that, we isolate the string functionality in a separate object, and we only need to replace one connection, which is the accessBoth method accessing the property.
The steps are simple: we start by creating a new class with an appropriate name and creating an instance of that inside the old class.
There is also the option of extracting a base class, but in my opinion, it is only appropriate when many classes share the same set of members.
class StringManipulator{
}
class Demo{
[...]
stringManipulator=new StringManipulator();
[...]
}After that we copy all the chosen members from the old class to the new one, and we also copy the relevant part of the constructor:
class StringManipulator{
greet() [...]
greetFormally() [...]
someString:string [...]
constructor(s:string){ [....] }
}Up to now, the compiler should not be complaining, and we could run tests to verify that nothing is broken.
So let’s start breaking things: we remove all the declarations that have been copied, and we replace the references with methods and properties in the stringManipulator object.
For example:
accessBoth(){
console.log(‘hello ‘+this.stringManipulator.someString [...]);
[...]
}The compiler and the unit tests will help and accelerate the process.
After the class has been refactored and tested, we can decide that we are already satisfied or simply restart the process. If we want to do that, we will need to remove the old graph with the query:
MATCH (n) DETACH DELETE nConclusions
A graph-assisted approach to code refactoring, as demonstrated in this little tutorial, can be a very useful technique in giving new life to projects that have become difficult to maintain. Please comment if you have other ideas on how to take advantage of graphs in the development of a software project!
If you want to know more about refactoring, I suggest the classic book “Refactoring” by M. Fowler.