
In the last post of our “Neo4j Modelling for Beginners” series, we looked at bidirectional relationships. In this post, we compare the implications of qualifying relationships by using different relationship types versus using relationship properties.
Properties as qualifiers
Let’s say we want to model movie ratings in Neo4j. People have an option to rate a movie with 1 to 5 stars. One way of modelling this, and perhaps the first one that springs into mind, is creating a RATED relationship with a rating property that takes on 5 different values: integers 1 through 5.
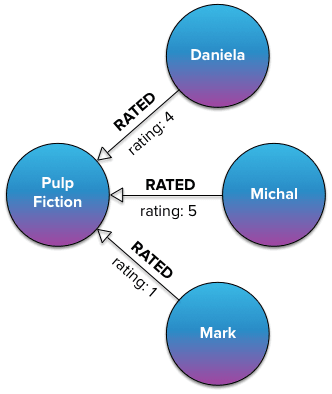
Writing queries using this model is fairly straightforward in both Java and Cypher. If we wanted to get all people who rated Pulp Fiction positively, i.e. with a rating greater than 3, we could just write
for (Relationship r : pulpFiction.getRelationships(INCOMING, RATED)) {
if ((int) r.getProperty("rating") > 3) {
Node fan = r.getStartNode(); //do something with it
}
}
or, equivalently, in Cypher
START pulpFiction=node({id})
MATCH (pulpFiction)<-[r:RATED]-(fan)
WHERE r.rating > 3
RETURN fan
Relationship types
Since we know all the possible relationship qualities up front, there is another option: using a separate relationship type for each rating. For example, we could define the following relationship types: LOVED, LIKED, NEUTRAL, DISLIKED, and HATED, corresponding to 5 stars down to 1 star, respectively. The above graph would then look as follows.
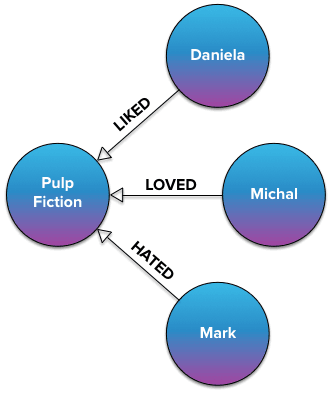
Both queries would have to be slightly modified to yield the same result, i.e., people who are fans of Pulp Fiction. In Java, one would write:
for (Relationship r : pulpFiction.getRelationships(INCOMING, LIKED, LOVED)) {
Node fan = r.getStartNode(); //do something with it
}
and in Cypher:
START pulpFiction=node({id})
MATCH (pulpFiction)<-[r:LIKED|LOVED]-(fan)
RETURN fan
Comparison
In terms of query syntax, there isn’t really all that much difference. If we had, for example, 10 different qualities of the relationship and wanted to query for 7 of them, one could argue the first approach is more convenient: it does not require listing all the relationship types we’re looking for.
Let us, however, explore the two approaches from a performance point of view. The first experiment is designed to find out whether there are any write throughput differences between the two approaches. We created 1,000 relationships between random pairs of nodes and measured the time taken to do so. We varied the number of relationships created in a single transaction from 1 to 1,000. The results are depicted in the following figure:
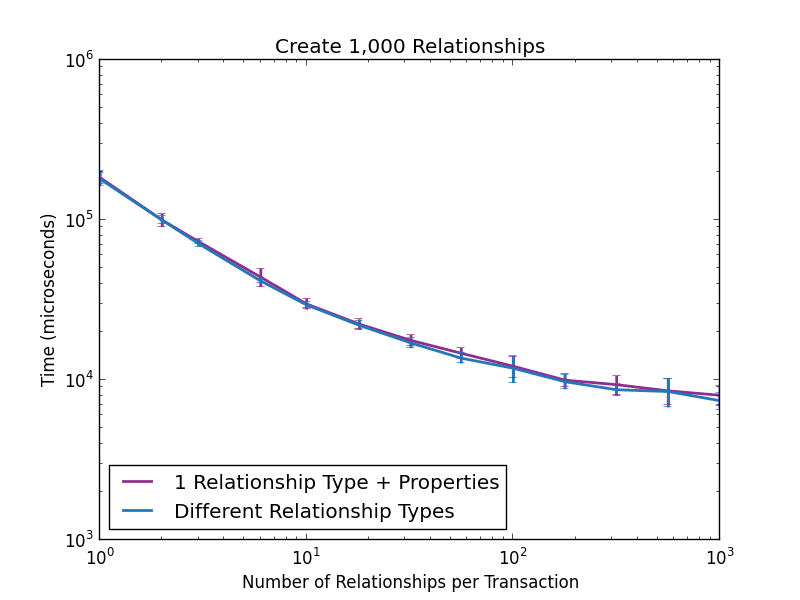
Clearly, there is no significant difference in write throughput between the two approaches. However, this is not true for traversals.
In the second experiment, we executed all the queries shown earlier 100 times on a graph with 100 nodes and 5,000 randomly qualified, uniformly distributed relationships (which makes the degree of each node 100, on average). We performed the experiments in three different settings.
- No caches involved, data read from disk
- Data in low-level cache, high-level cache turned off
- Data in high-level cache
The next two figures show the time taken to execute these queries in Cypher and Java, respectively.
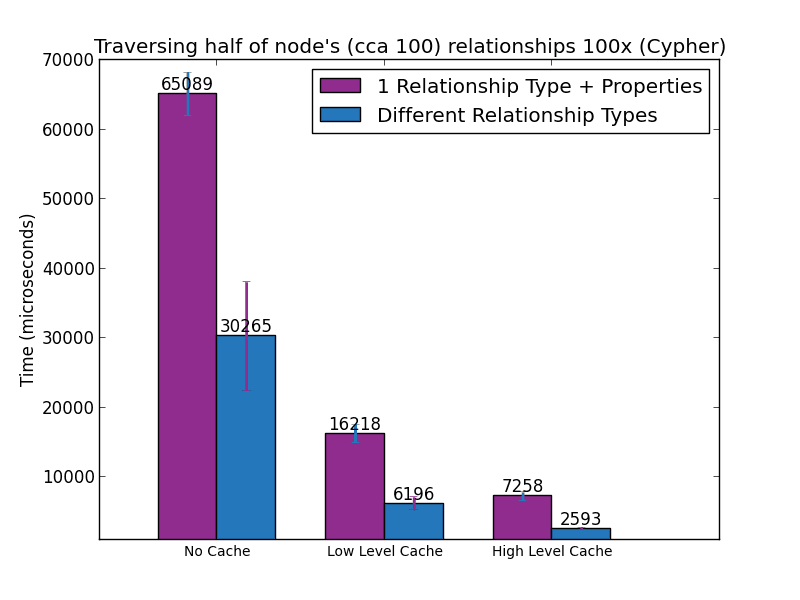
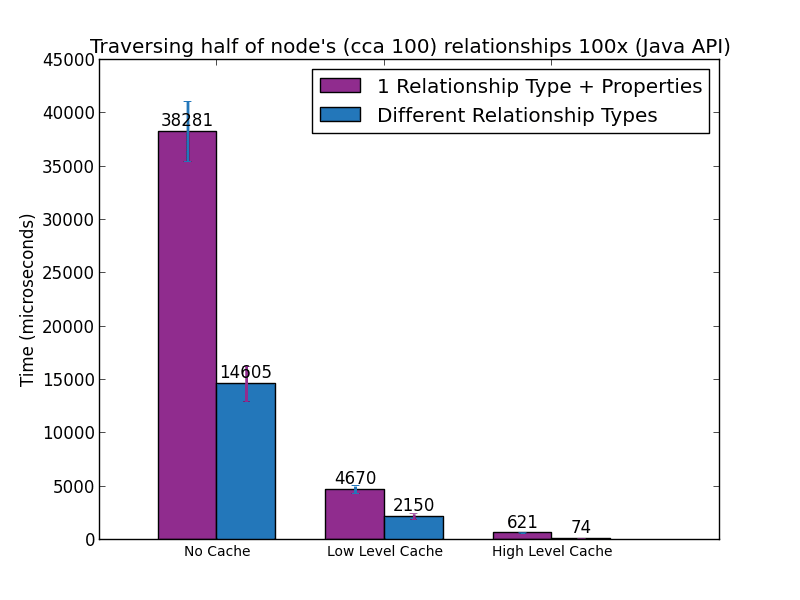
The multiple-relationship-types approach always outperforms the single-type-and-property approach, sometimes by as much as a factor of 8. There is a technical reason for this, which has to do with the way Neo4j organises its data on disk and in memory. But that is a topic for one of the next posts.
It is important to realise that we have only measured a single-hop traversal. If that is already 8x faster, a traversal 2 levels deep could be 64x faster, and 3 levels deep could be 512x faster.
Conclusion
When possible, choosing different relationship types over a single type qualified by properties can have a significant positive performance impact when querying the graph. The former approach is always at least 2x faster than the latter. When data is in high-level cache, and the graph is queried using the native Java API, the first approach is more than 8x faster for single-hop traversals.
