
Graphs are a perfect fit for IT Operations. Right from dependency management to impact analysis and capacity to outage planning, the interconnectedness of the components that make up networks and services, modelled naturally as a graph enable various teams such as support, help desk and DevOps to navigate potentially complex relationships.
Background
The size of networks has been rapidly increasing, and along with it, assets such as applications, services, and devices. IT managers and operations teams have been facing challenges around quick response times and incident analysis due to the inability of traditional databases, such as relational, to process heavily hierarchical and interconnected data across siloed systems of record. Moreover, this data changes reasonably frequently when you take into account data centre reconfigurations or applications being either introduced or taken out of service. Graph databases such as Neo4j are designed to model real-world networks of heterogeneous and hierarchically connected data in a schema-free fashion, allowing for the adaptability that strict-schema databases struggle with. A graph brings together very easily all the areas of IT that the business depends upon, both human and device, providing a single cross-domain view to anticipate and diagnose problems.
Use cases involve impact analysis, troubleshooting, dependency management, redundancy and upgrade or maintenance planning and operational intelligence.
GraphAware Hume
GraphAware Hume is GraphAware’s graph-powered insights engine. This blog post shows a very simple case of modelling IT Operations as a knowledge graph in GraphAware Hume and deriving actionable insights.
We’ll be talking about ACME, a fictional company with a large network infrastructure made up of various applications, as well as public-facing websites that are required to be up in order for them to conduct their business. Our graph is based on the excellent Network Dependency GraphGist by Kenny Bastani.
The goal
ACME has a team monitoring its IT infrastructure and responding to incident reports and user complaints. We want to provide them with actionable insights to enable them to react quickly and efficiently. Our knowledge graph in GraphAware Hume connects up systems of record, which maintain information about hardware, applications, VMs, etc., health check monitoring, incident management, as well as people and team rosters.
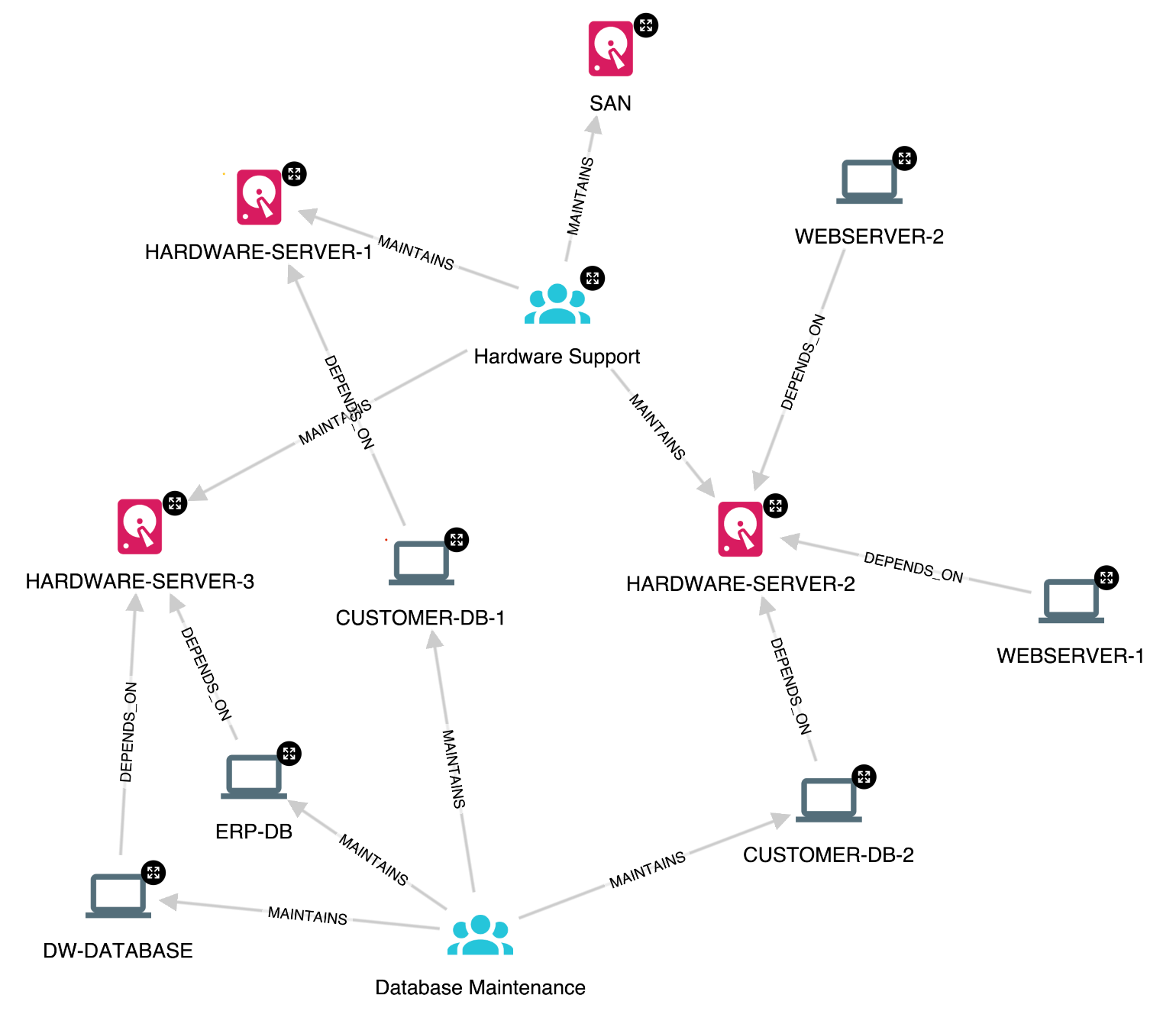
Here’s what it looks like-
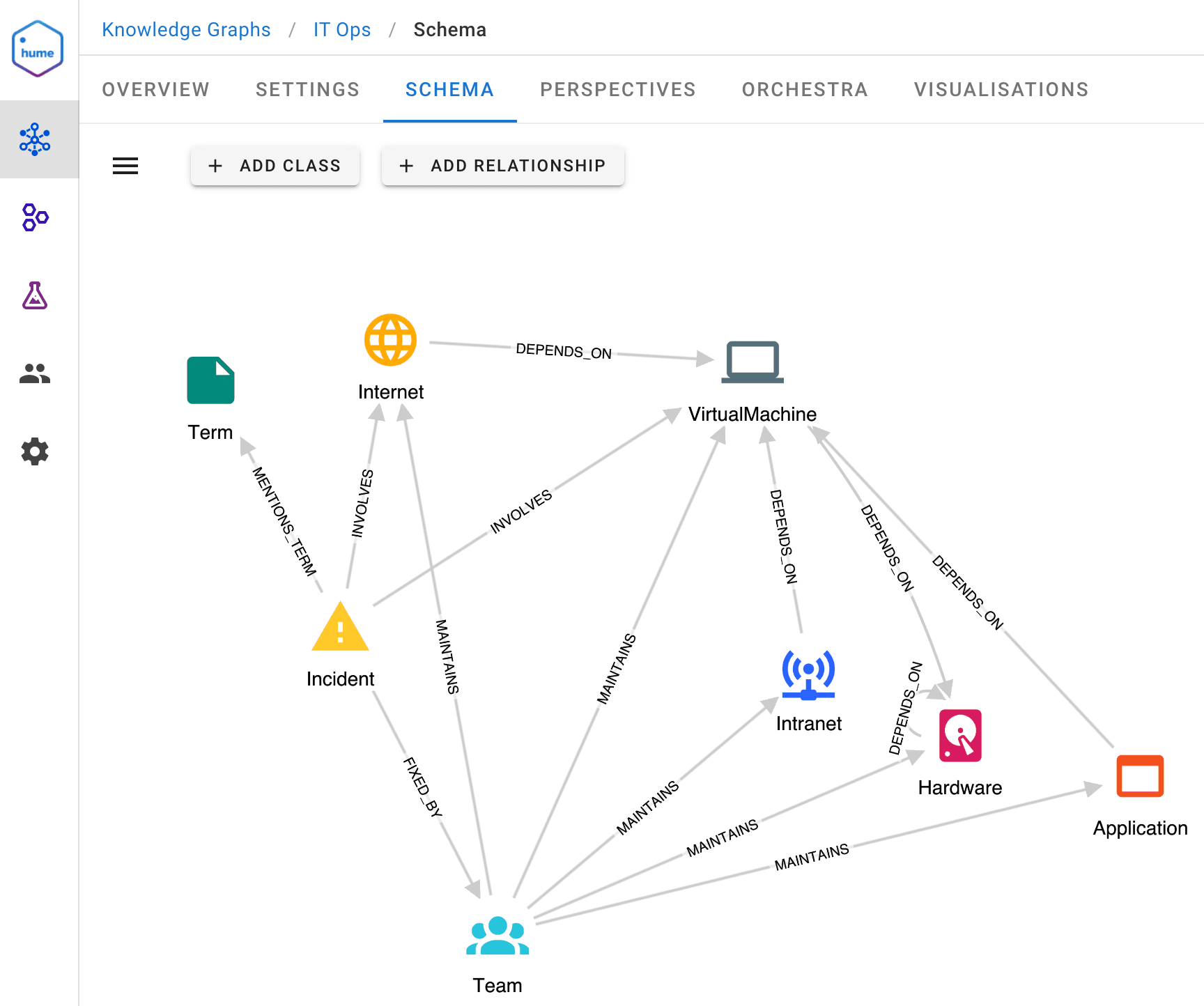
Nodes of type Hardware, Intranet, Internet, VirtualMachine and Application contain properties ip, system, type, host and health. The health property is continuously updated from the health monitoring tools, and for this blog, has values restricted to red, yellow and green, indicating system failure, intermittent problems, and normal operation, respectively.
Maintenance and support teams are also captured, and the MAINTAINS relationship indicates their responsibilities. This will be useful later on in this article.
Our knowledge graph is also integrated with the incident management system, which provides incident reports. We use the NLP functionality of GraphAware Hume to extract terms to assist help desks in their support activities.
Insights
Our first use case is impact analysis. Hardware Server 3 is being taken offline for maintenance. What is the impact on the rest of the system?
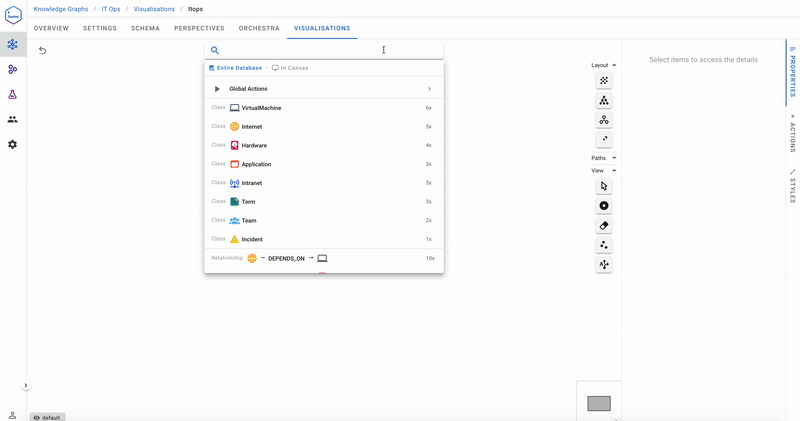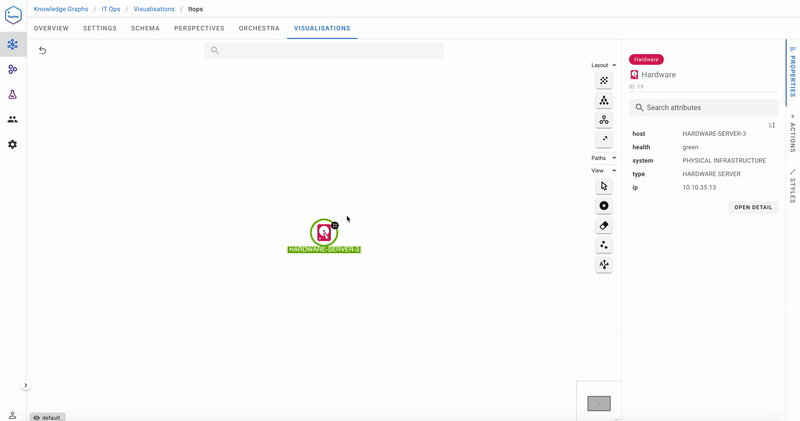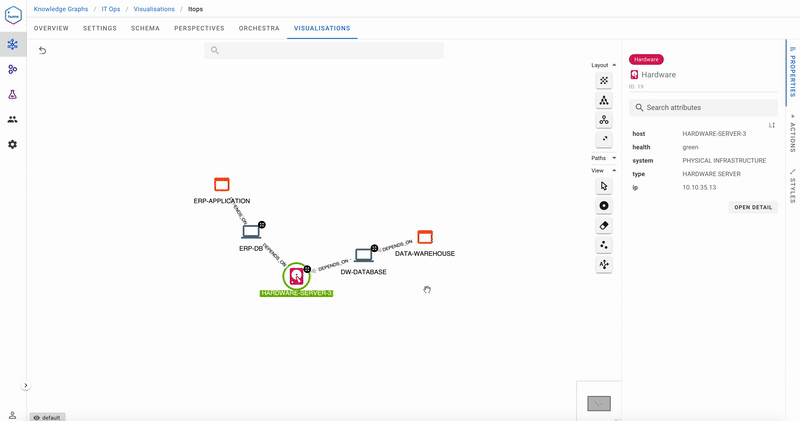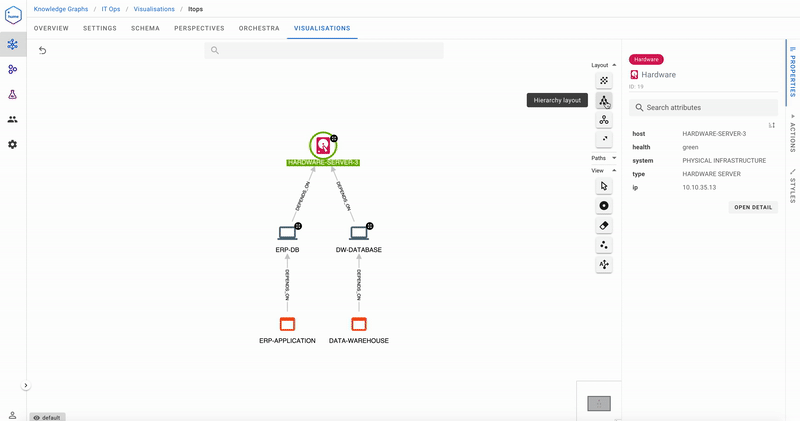
As demonstrated in this screencast, taking Hardware Server 3 out of action impacts both the Data Warehouse and ERP databases, which further impact the Data Warehouse and ERP applications. Analyse Impact was a Hume Action. Actions are a convenient way of making business queries available to the user without having to write any code.
This one is backed by a simple Cypher query:
MATCH p=(resource)<-[:DEPENDS_ON*]-(dependency)
WHERE ID(resource)=$id
RETURN p
Now let’s have a look at the ERP Application – deemed to be a critical resource over the next week. What are its dependencies, and where should the maintenance teams focus their attention during this important period?
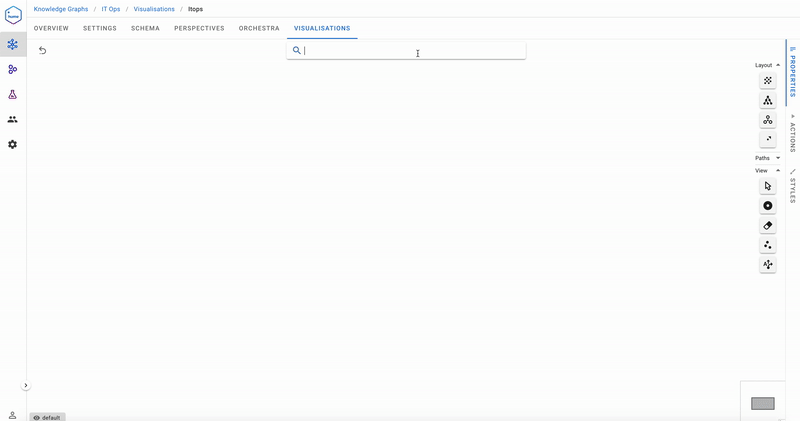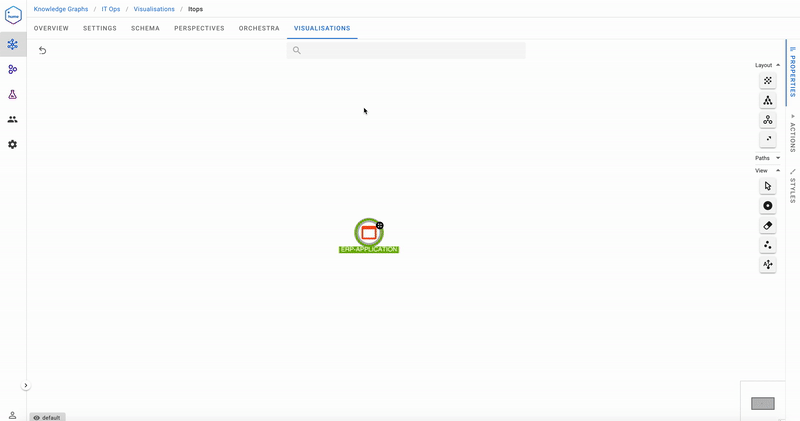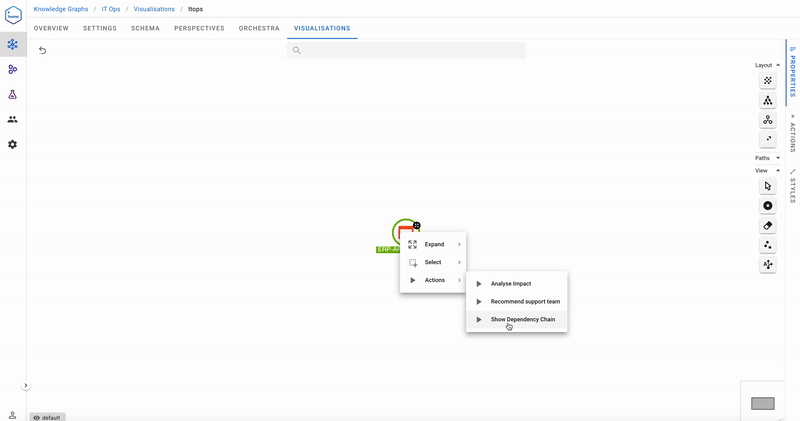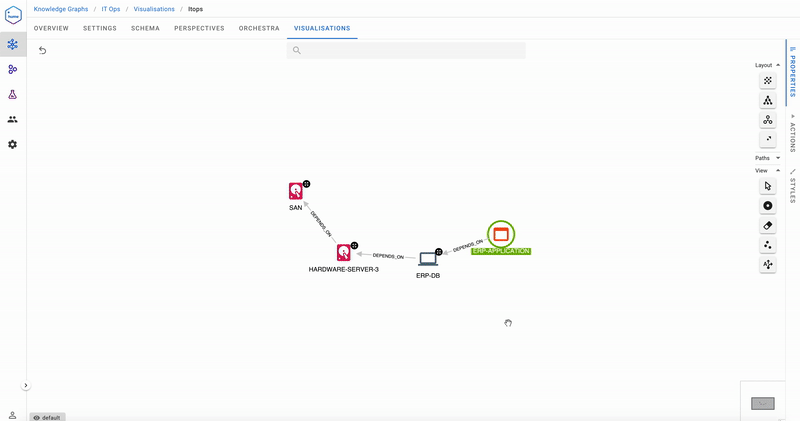
The dependencies show that it’s probably not a good idea to take Hardware Server 3 it down for maintenance next week! The dependency chain query is the inverse of Analyse Impact-
MATCH p=(resource)-[:DEPENDS_ON*]->(dependency)
WHERE ID(resource)=$id
RETURN p
Are there single points of failure in our infrastructure?
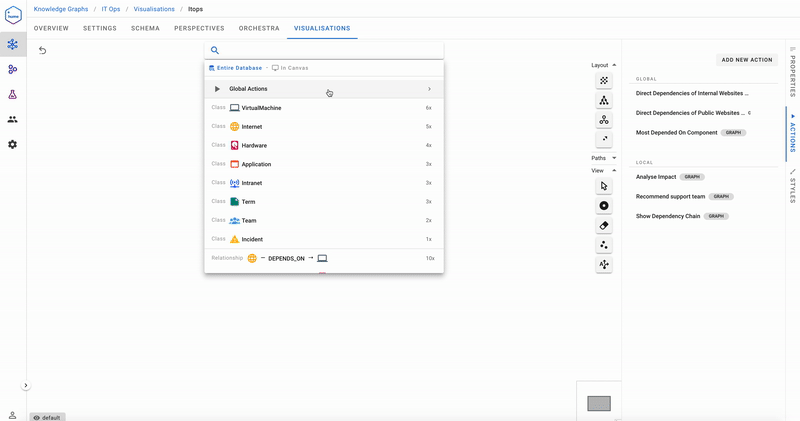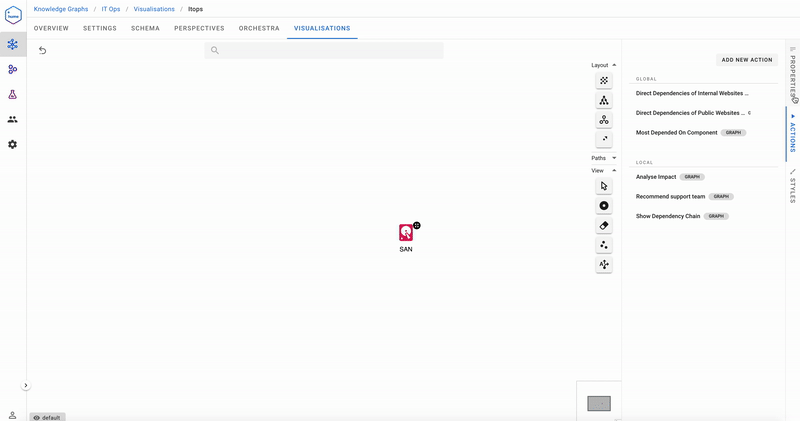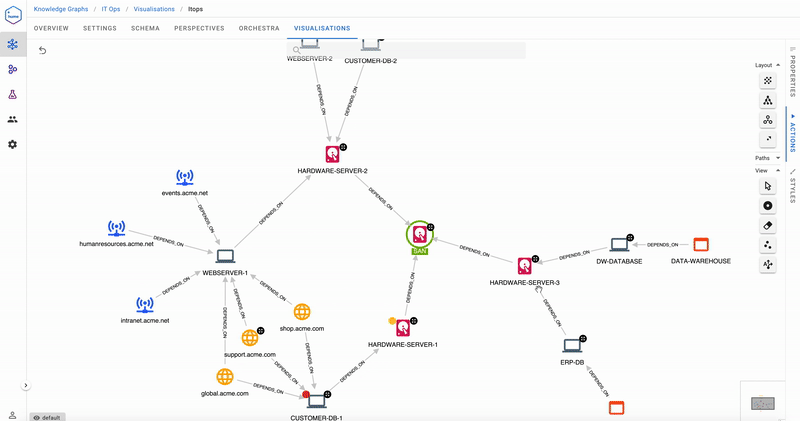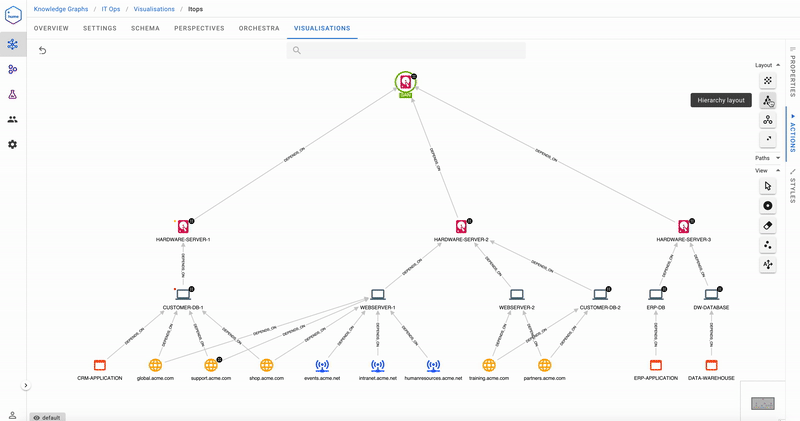
Indeed, failure of the SAN will bring everything to a halt! This was an example of a Global Hume Action, one which is not bound to any particular node. The Cypher that backs it is
MATCH (n)<-[:DEPENDS_ON*]-(dependent)
WITH n AS host, count(DISTINCT dependent) AS dependents
ORDER BY dependents DESC LIMIT 1
RETURN host
Another example of a Global Hume Action would be finding direct dependencies of all of ACME’s internal-facing websites.
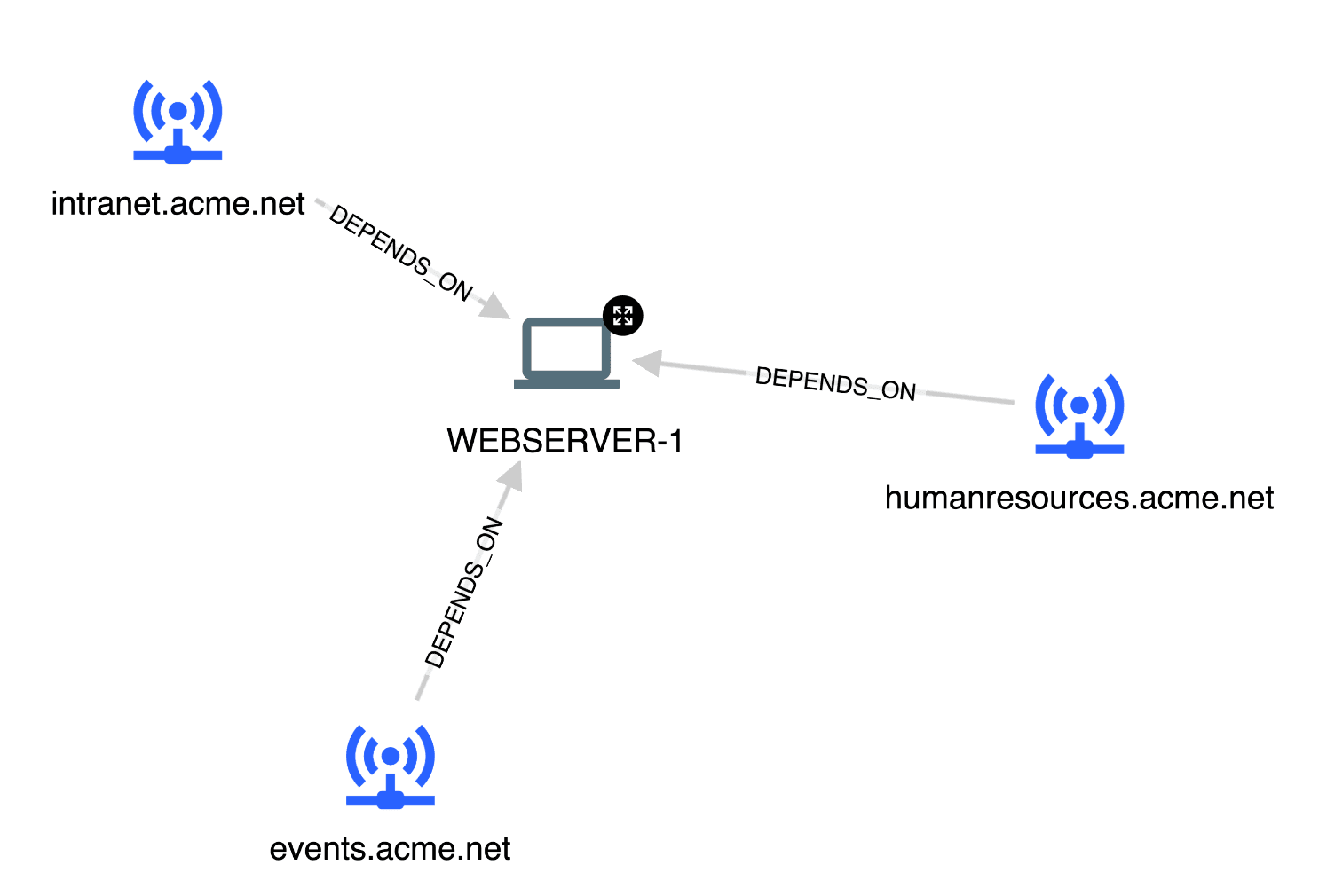
How about looking at the direct dependencies of the more important public-facing websites?
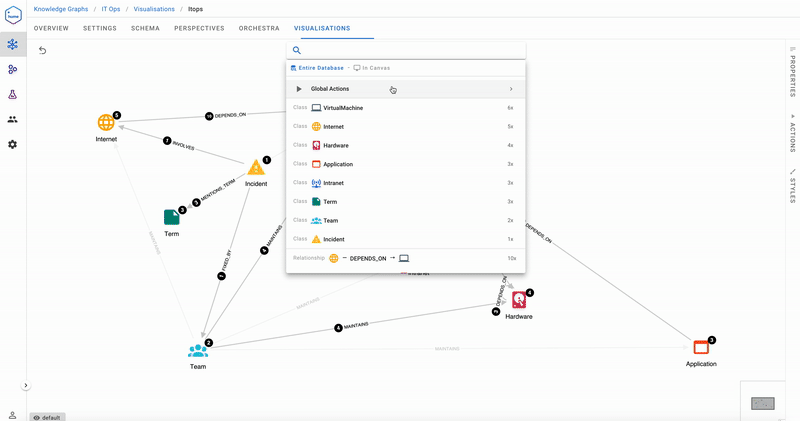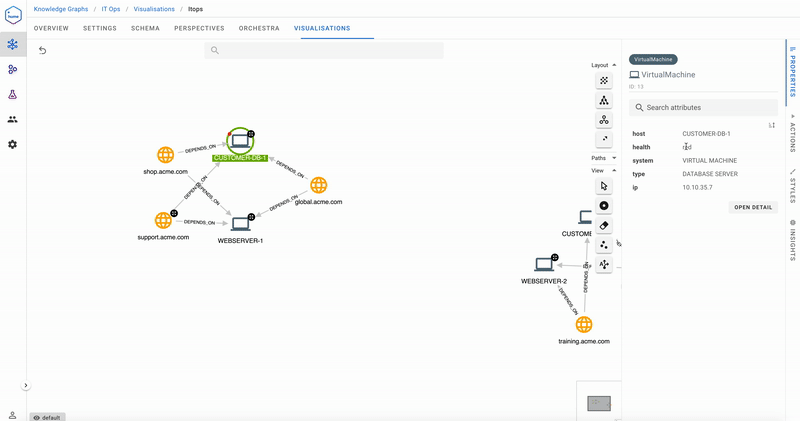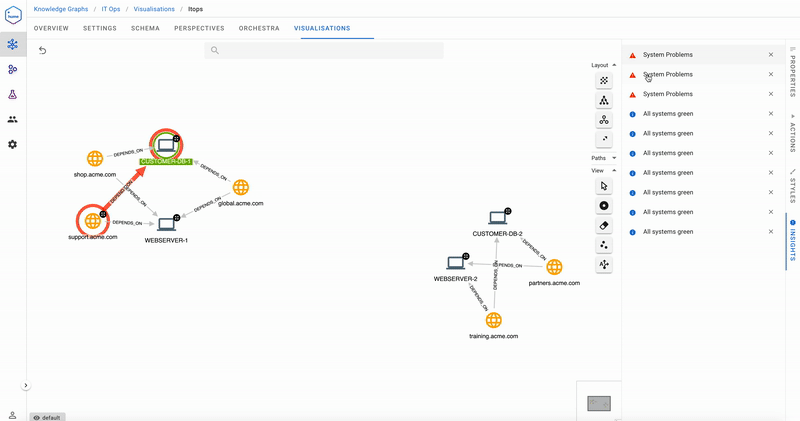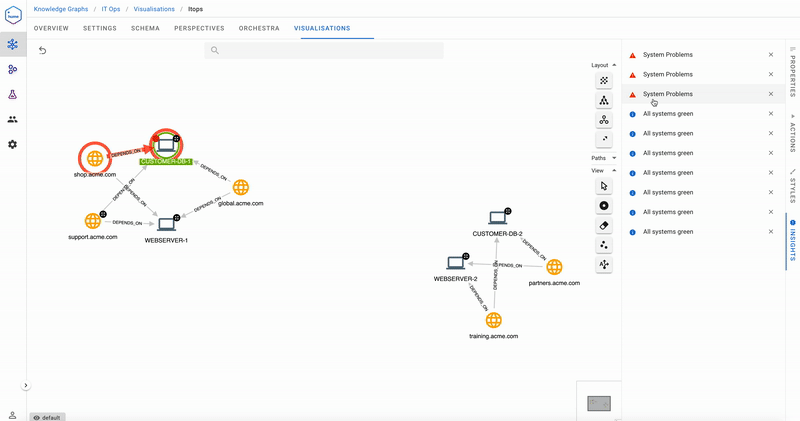
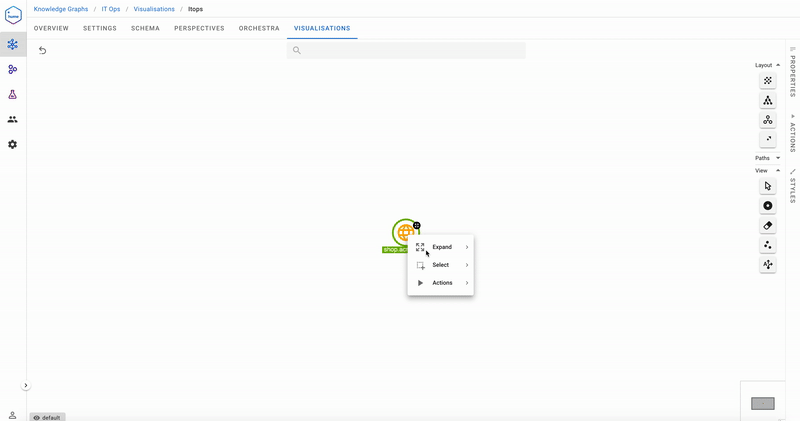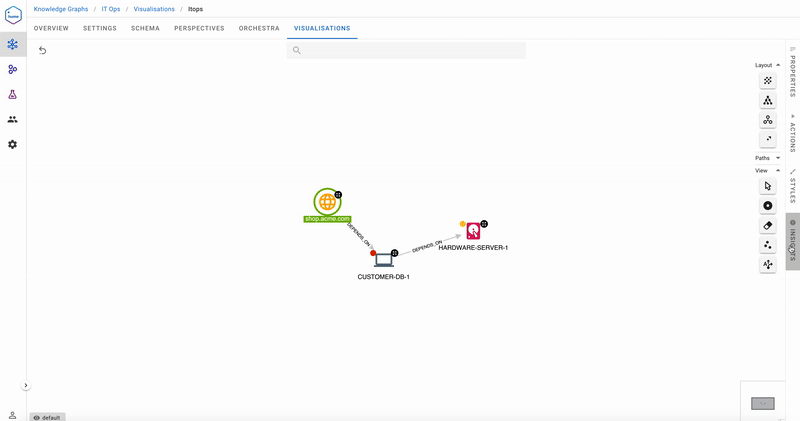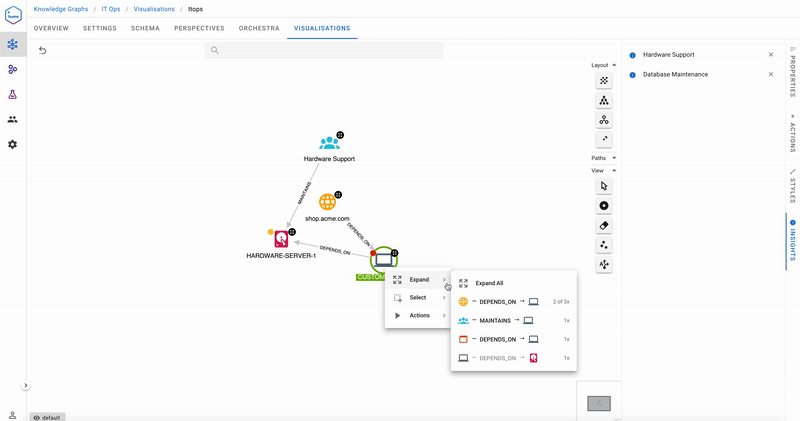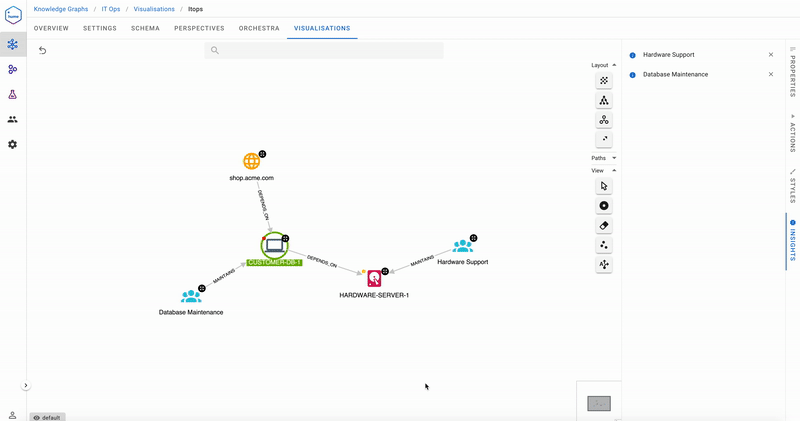
Uh oh- we have problems! The flashing red badge indicates that Customer DB 1 it is in a critical state- its health is red. We’re also able to immediately tell from the Insights pane that three public-facing websites are impacted.
In the meantime, ACME’s Help Desk receives a complaint that shop.acme.com has issues. Before Hume was deployed, the team struggled to identify which maintenance team to call, and more often than not, they were based on guesswork, leading to a lot of time wasted in hand-offs and a developing sense of mistrust when a maintenance team received an “emergency” call from the Help Desk. Now, with GraphAware Hume, the Help Desk is in a better position to call the team with the most likely capability to fix the issue.
The Help Desk team runs the action Recommend support team, and the Insights tab recommends they call Hardware Support first, and only if they must, alert the Database Maintenance team. In the past, ACME’s Help Desk would have called Database Maintenance first, seeing the red health, but in reality, this team would redirect to the Hardware Support team since their database was down due to disk issues. Acme Help Desk now feel much more comfortable dealing with incidents and maintenance teams, and has been recording quicker turnaround times.
Taking it further, because the Incident management system is integrated as a data source in GraphAware Hume, the next time the team receives a user complaint, in this case, that they are experiencing a degradation in search response, the team can look for similar incidents.
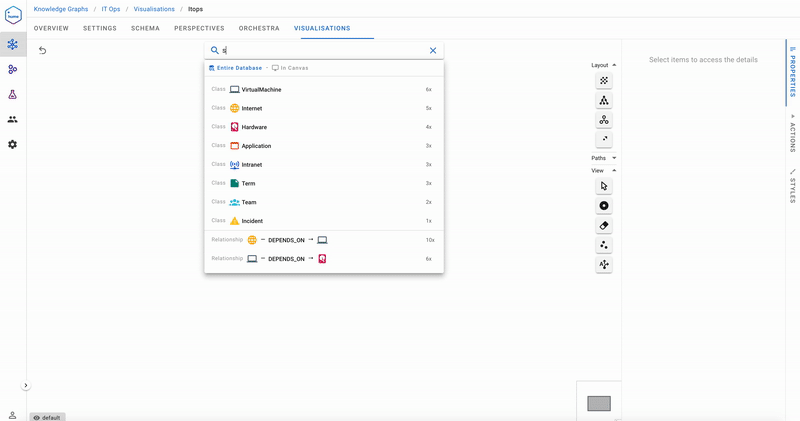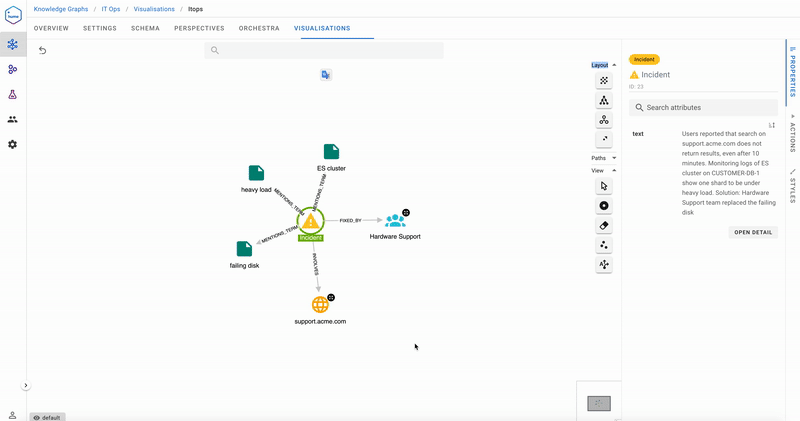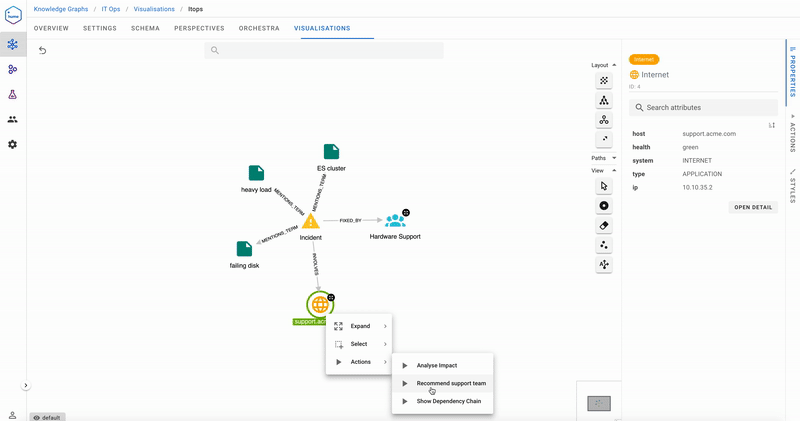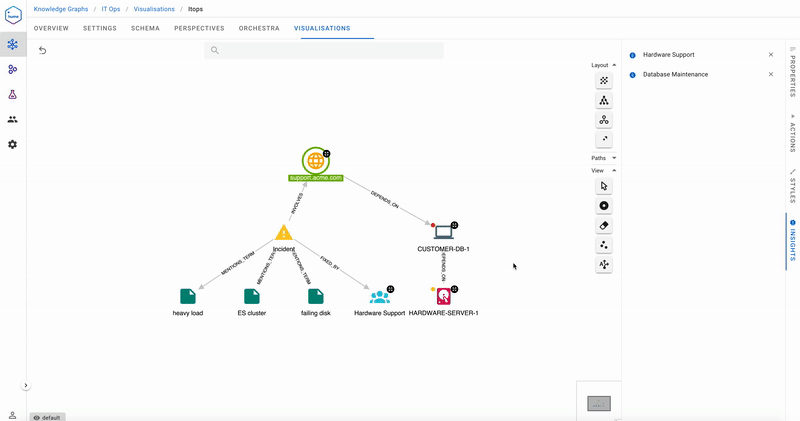
They find one and expand it to see which elements were involved. We see that the issue was fixed by the Hardware Support team, and relevant keywords extracted from the Incident text using Hume’s Keyword and Entity Extraction are also displayed.
Once more, they look for recommendations around which team to contact, and it is the notorious Hardware Support team, again, for the failing disk.
Conclusion
This knowledge graph, whilst tiny, still shows the power of graphs and GraphAware Hume. We’ve explored the basics of dependency management, impact analysis, and incident response.
E-mail us at info@graphaware.com, or call any of our offices to learn more about how GraphAware Hume can help your IT organisation.
