
The Metropolitan Museum of Art recently published a dataset of more than 470,000 works of art under the CC-zero License. Representing such a collection as a knowledge graph allows us to explore it in a unique way – seeing the artworks, their authors, donors, mediums, tags, or art movements deeply connected, being able to traverse the links between them and discover unexpected relations.
The inspiration to explore this dataset spring from an exciting challenge by Neo4j, the Summer of Nodes: Week 2, make sure to check it out.
To create and explore the Art knowledge graph we will use Hume insights engine. The full Metropolitan Art collection is available for download at this repository, however for the sake of simplicity, we will work only with this cut.
Building the Art Knowledge Graph
Ingesting the artworks
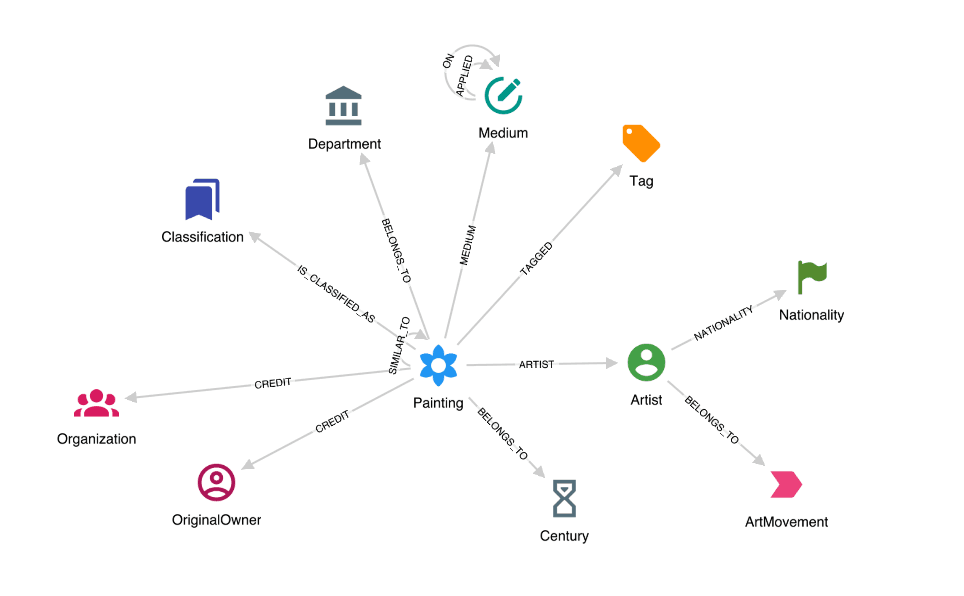
We describe the structure of the graph using Hume Schema. In the middle of the schema there is a Painting class representing an artwork. It is connected to other classes based on Classification, Department it belongs to, which Medium was used to create it, how it is Tagged, and who is the Author or who donated it to the museum (the [CREDIT] relationship). Artists have one or more Nationalities and some belong to an ArtMovement. Moreover, the Painting class has attributes objectId, name, resourceUrl (link to Metropolitan Art Museum website), sizeX, sizeY, radius (in case the painting is a circle), accessionYear and credit (a sentence describing how the museum acquired the painting).
The dataset is distributed as a csv file with each artwork in a single row. Hume Orchestra enables us to process and ingest rows of the csv into the graph. We start simple with only five components.
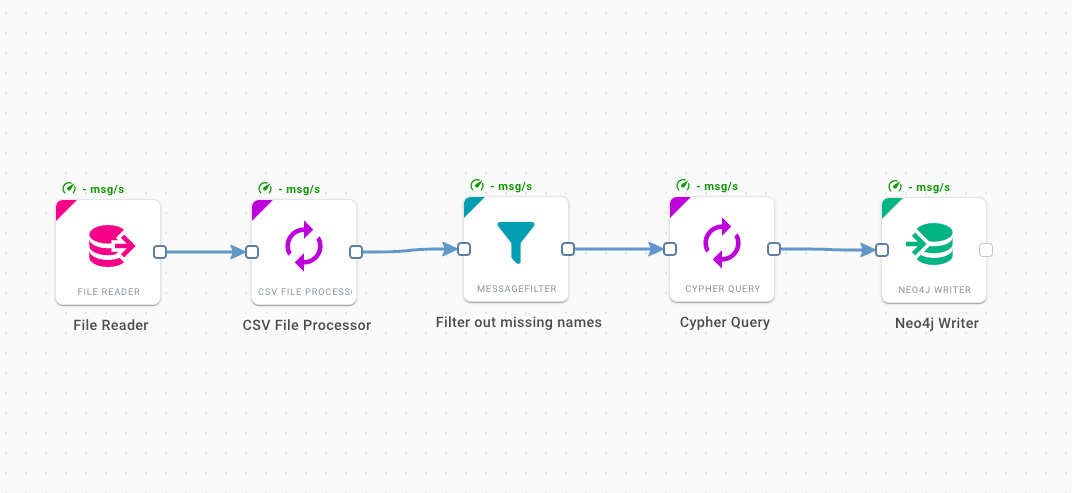
The File Reader loads the csv file from a local folder, then the CSV File Processor parses the file and produces a single message for each row in the table. Next, we will use Filter to remove all the rows with missing titles; a single line of python code will do the job return not body['Title'] is None. Finally we will write a Cypher query to be executed on each message and run it with a Neo4j Writer.
The excerpt below shows how we set some of the attributes and create Department and Tag nodes related to the painting.
MERGE (painting:Painting {objectId: toInteger($objectId)})
SET painting.objectId = toInteger($objectId),
painting.name = $title,
painting.resourceUrl = $resourceUrl,
painting.accessionYear = $accession,
painting.credit = $credit
WITH painting
MERGE (d:Department {name:$department})
MERGE (painting)-[:BELONGS_TO]->(d)
WITH painting
UNWIND split($tags, '|') AS t
WITH painting,t
MERGE (tg:Tag {name: t})
MERGE (painting)-[:TAGGED]->(tg)
...
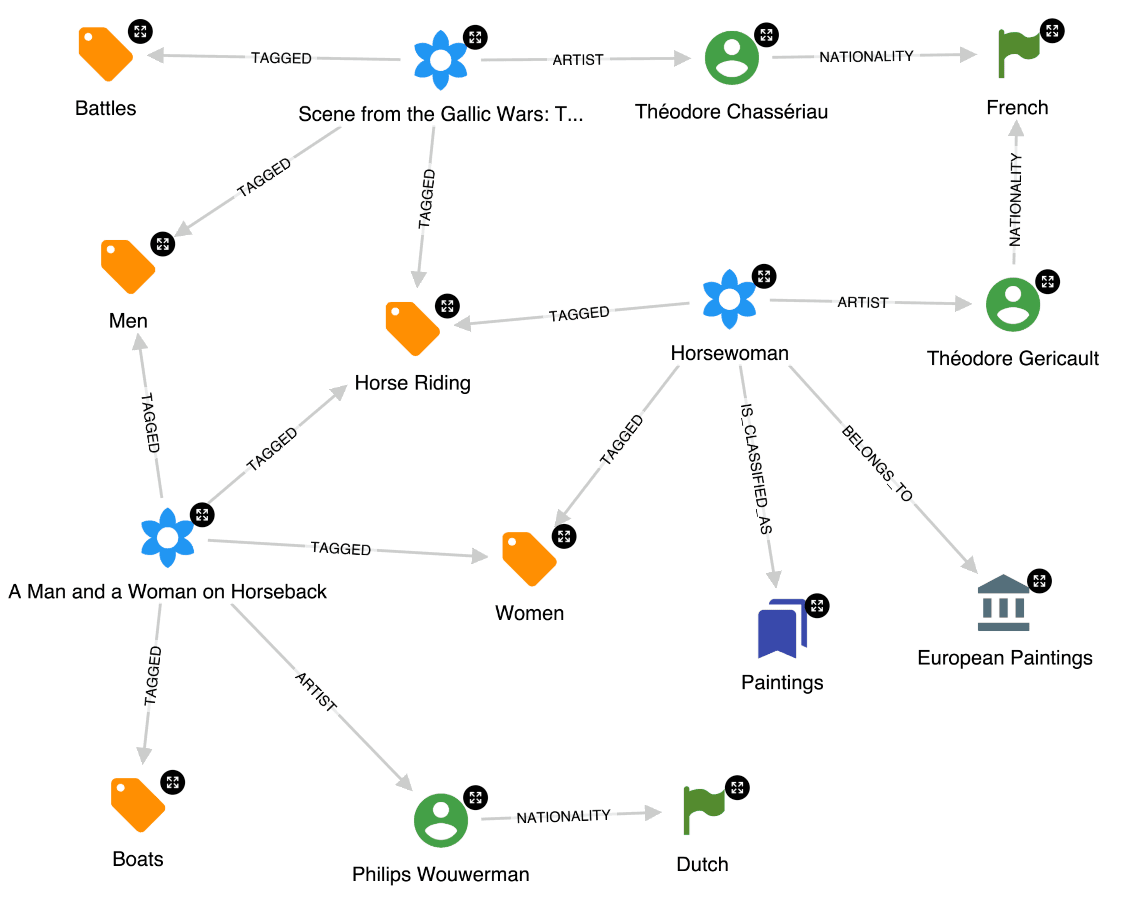
After running the workflow, the base of our knowledge graph is in place. We can already start exploring and get graphs like this one with three paintings, their authors and tags.
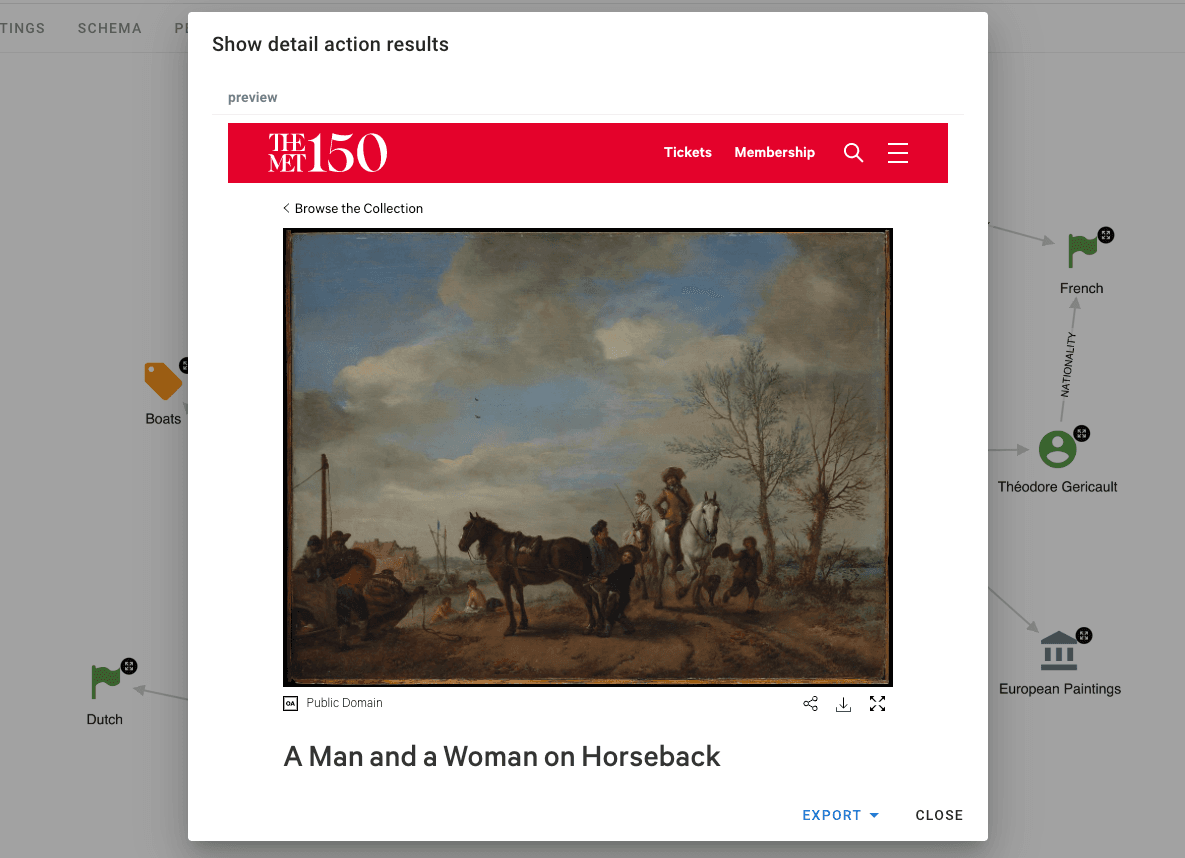
Action: Show me the painting!
Naturally, we would like to see how the paintings look. Are there really boats in the Dutch painting with men and women riding horses? We will add a Hume visualisation action to do that.
Unfortunately, it is not that simple, the dataset does not include any images, just the resourceUrls – links to the museum website, where the paintings are shown. Moreover, the Metropolitan Art Museum website is well secured against content scraping, so it would be very difficult to load the page by Orchestra, extract the image and display it.
Luckily, there is a different way. Hume Actions have various return types, one of them is TABLE. The knowledge graph settings provide an ‘Allow HTML rendering in Table results’ option, which does exactly what we would expect. The initial intention of this feature was to enable the users to highlight parts of texts in their TABLE results. We will exploit this behaviour and create an action which returns a table with a single cell. This cell contains HTML with an iframe which renders the museum URL directly without any processing. Since this is not content scraping, it is allowed by the website. Moreover, this approach gives us more capabilities like zooming in, multiple photographs of one painting, or sharing the image which are provided by the museum website.
In the Hume Visualisations we create a LOCAL action runnable on nodes with class Painting, with return type TABLE, and with the following cypher query:
MATCH (p:Painting) WHERE id(p) = $id
WITH replace('<div><iframe style="width: 720px; height: 70vh; border: 0px;"src="$resourceUrl"/></div>',
'$resourceUrl', p.resourceUrl) as preview
RETURN previewAfter running the action, we will see the pop-up window below, which contains an iframed gallery website with the painting we wanted to see. And there is indeed a boat on a river in the background.
This must be oil on canvas
Another interesting attribute of the Artworks is the Medium. We would like to represent it in the graph as well. For some paintings the medium description is simple like Ivory or Oil on canvasTempera on wood; golden ground or Oil, gold, and white metal on wood. To capture the medium and it’s decomposition we propose the following schema:
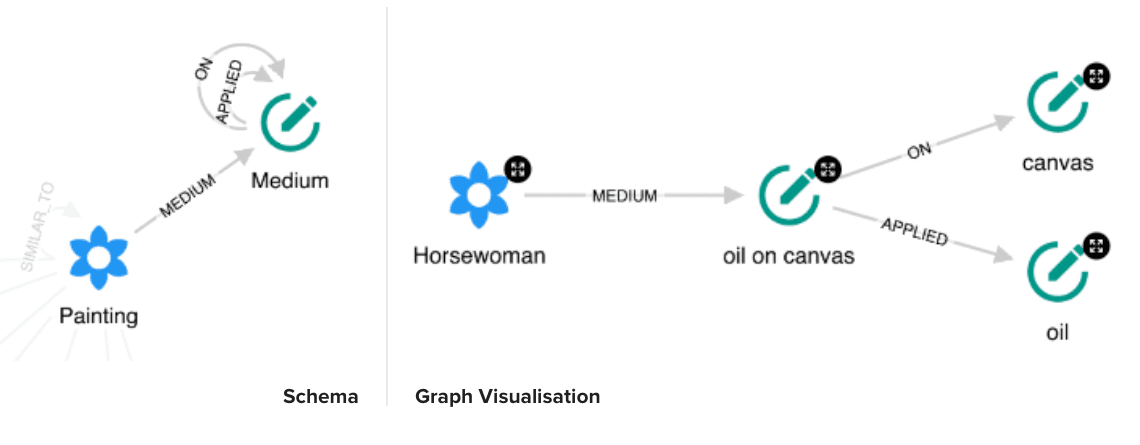
The Painting is connected to one or more Medium nodes. A composed Medium (oil on canvas) has relationships to its components. We distinguish between two relationship types: [APPLIED] (usually a type of paint that the artist works with, e.g. oil) and [ON] (usually the background material e.g. canvas, wood). This structure will help us later find similarities between paintings.
To process the medium strings into their graph representations, we do not need Natural Language Processing (NLP) capabilities. In this case simple textual analysis will suffice. In Orchestra we will use the Message Transformer component to run this python script. Simply said, it will split the text by semicolons, then separate the ON medium which is on the right side of the on keyword. After that split the words on the left side based on commas and add them into the APPLIED list.
For an example input Oil, gold, and white metal on wood; golden ground the script outputs:
"baseMediumList":[
{
"base":"Oil, gold, and white metal on wood",
"applied":[
"Oil",
"gold",
"white metal"
],
"on":["wood"]
},
{
"base":"golden ground",
"applied":[],
"on":[]
}
]For each of the items in the JSON, we will create appropriate nodes and relationships using the Cypher query component [link to the same query as in the beginning].
Who is the generous donor?
For each artwork we know how and when the Museum acquired it; a simple sentence in an attribute credit describes it, e.g. Gift of Harry G. Friedman, 1951. To enrich our knowledge graph with original owners and the organisations which donated the paintings, we will use some very basic NLP capabilities provided by Hume out of the box. Consider the following orchestra workflow:
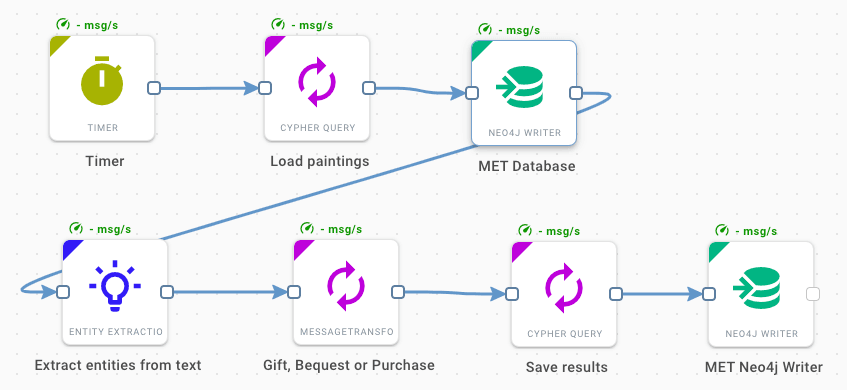
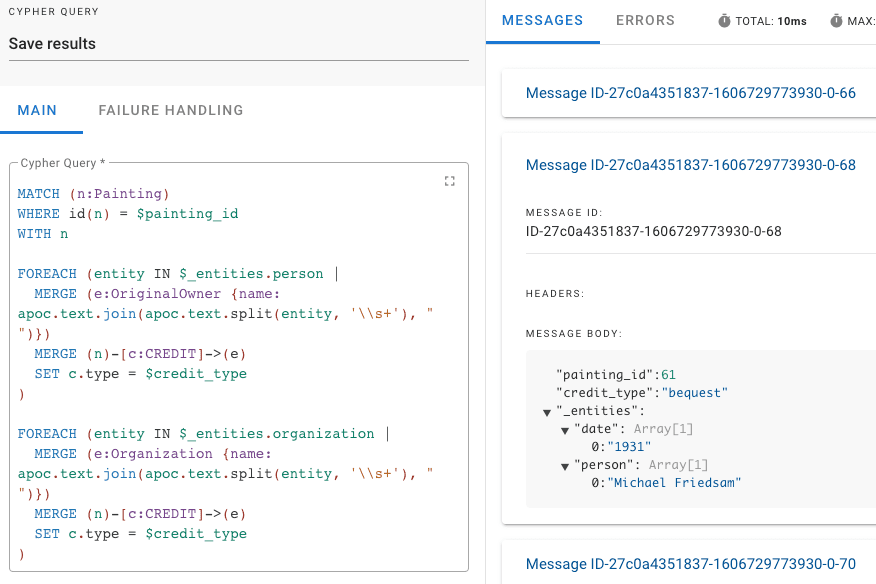
The Entity Extraction is a component using the Stanford NLP library. It recognizes people, organizations, and dates in the credits, which is exactly what we need. Moreover, we can access the annotation tokens and search them for keywords like gift, bequest or purchase. Finally, we persist the newly found donors to our graph and create links to them with type attributes to distinguish the gifts, bequests and purchases.
Édouard Manet? Impressive!
One aspect the dataset misses completely are the art movements. It would be useful to classify the artist, or ideally the paintings according to the art movement. We can do that by enriching our graph with data from a different dataset.
The artcyclopedia.com provides a decent list of art movements with related artists. This time, we can scrape the data easily, since they are well structured in tables. We will use an apoc procedure apoc.load.html() which allows us to load the html site and search for components in it directly.
In an Orchestra workflow, first we will load names and URL links of all the art movements. Then for each movement we run the following cypher to persist it and load the artists who relate to it:
MERGE (m:ArtMovement {name: $text})
WITH m, 'http://www.artcyclopedia.com/' + substring($link.href, 3) as cleanUrl
call apoc.load.html(cleanUrl, {artists:'tr'})
yield value
unwind value.artists as artist
return artistIn a subsequent Orchestra component, we search the database for already existing artists and create relationships connecting them to the Art Movements.
MATCH (a:Artist) WHERE a.name = $data.name
MATCH (s:ArtMovement {name: $data.style})
MERGE belongsTo = (a)-[:BELONGS_TO]->(s)
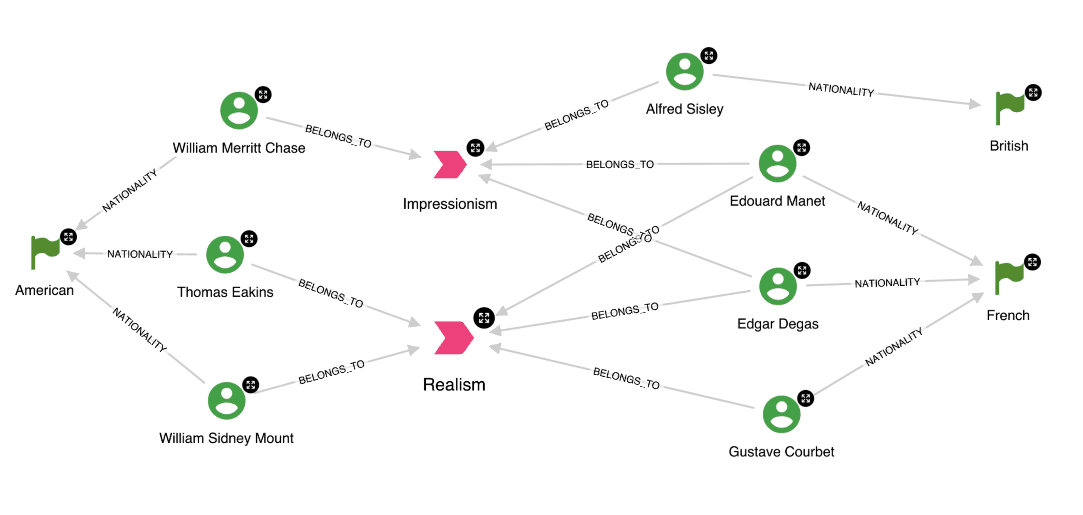
RETURN belongsToAfter the enrichment we are able to explore graphs like the one below. And discover which artists probably transitioned from realism to impressionism during their career. Although we managed to classify only about one fourth of the artists from the artcyclopedia dataset, this approach shows that enriching the graph from an external datasource is really easy. And we can continue with ingesting knowledge about artists from other sources e.g. from Wikipedia.
Conclusion
We have demonstrated how to ingest and process publicly available datasets and create an art knowledge graph using Hume. We have used Hume Orchestra to quickly load artworks from a CSV file and showed how to explore them through Visualisations. Hume’s NLP capabilities enabled us to recognise the donors and organisations in the credit sentences. And finally, we have enriched our graph with art movements from an external dataset.
E-mail us at info@graphaware.com, or call any of our offices to learn more about how Hume can help your organisation.
