
Before I started at GraphAware, I spent many years in research, both academia and industry, focusing my attention on machine learning and image processing.
So when I knew that my first project was meant to be integrating image recognition in GraphAware Hume, I was excited.
Everything started during my first day at GraphAware. I was talking with Alessandro, the Chief Scientist, who was in charge of my onboarding. He asked me, with my past experience in image analysis, if I would be able to draw out a system for face recognition applied to an eventually growing set of pictures.
I knew it was not a trivial task, but I had some experience and, researching around it, I knew that the current state of the art technology was quite astonishing… So I just said: “Yes, sure. I can do it.” I saw he was quite excited by my answer and immediately started to describe his perspective from the graph point of view, making my understanding of the task much clearer. Furthermore, we discussed the possibility of including object detection, and we decided to include such features in the final goal.
The project went through two key steps: the identification of faces in a picture and then the extraction of a fingerprint from within the identified face rectangles: a numerical vector describing each face in a multidimensional space. I knew that in recent years, academic researchers had proposed some amazing approaches based on Convolutional Neural Network (CNN) capable of providing good results even in real-world applications. So I went through some literature, and once I identified the most promising methods, I started implementing and exploiting some publicly available models trained on massive datasets that, luckily, exhibited the desired level of accuracy.
The code was growing, and I was also acquiring a good deal of experience, following my colleagues’ guidelines, in structuring it in a proper way. This approach, together with the freedom to explore possible solutions, in a short time led to a robust back-end service capable of analysing the provided pictures and producing an accurate clustering of the people in the photos.
In the prototype, all the data collected from the pictures – objects recognised, bounding boxes, fingerprints, etc. were stored nowhere and, hence, it didn’t provide any valuable knowledge.
This knowledge was exactly the one Alessandro described in his “knowledge graph” schema, but anyway, a concern was growing in my mind: I did not have any experience with graphs, as well as with GraphAware Hume, so how would I manage all the “knowledge graph” aspects? The answer came when, after sharing such perplexity with my colleagues Fabio and Vlasta, I experienced their excellent support. Their propensity to invest time in making me aware of what the working processes were in the company helped me to start working with Hume and to integrate my image processing service.
So day by day, things were improving. My colleagues were driving me to develop the process in the right direction through suggestions, wonderful discussions, and assessments.
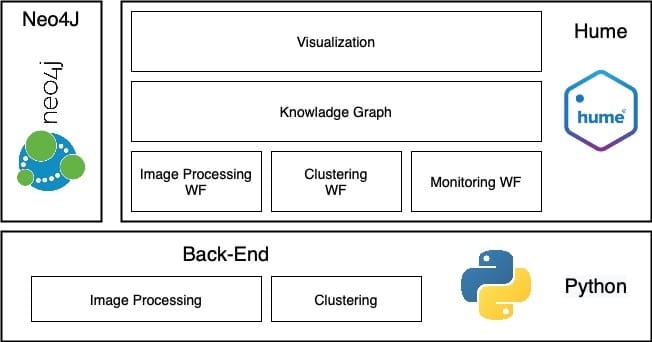
In the end, the resulting prototype was surprising: a core knowledge graph as a backbone of a system made up of three intuitive Hume orchestra workflows and the image processing and clustering back-end services, all serving the visualisation level, providing a useful view of subjects’ co-occurrences, pictures and subject visualisation and maps, and time perspectives. Integrating new machine learning components in Hume was straightforward, with no need to change any “core component” (that they would never allow me to do in the early days).
The resulting high-level architecture is depicted in the next figure.
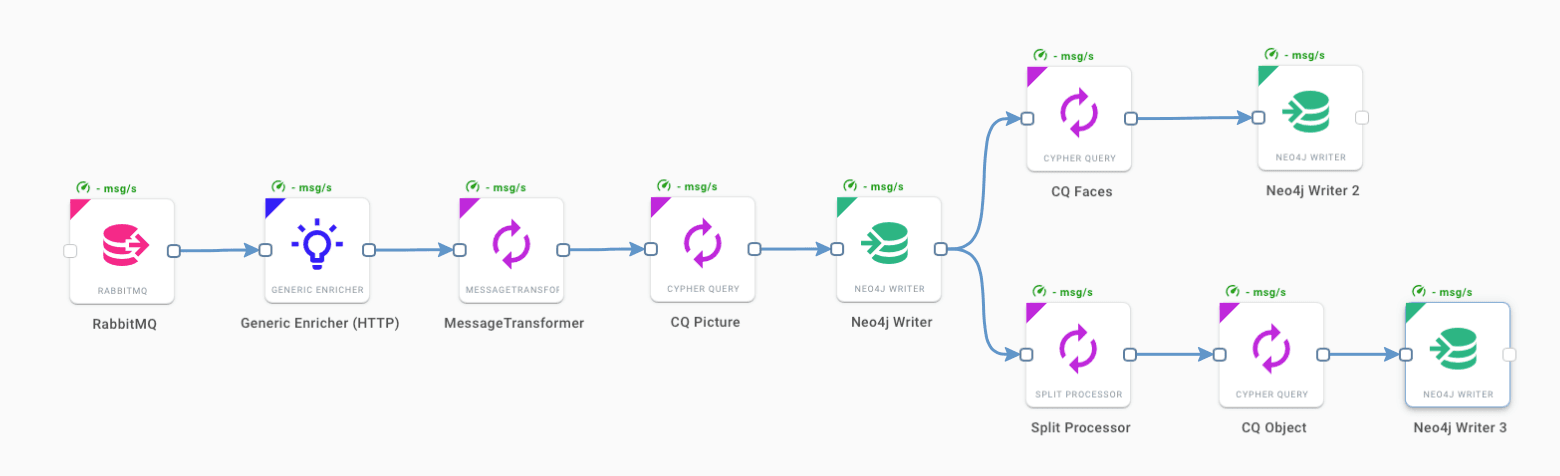
The first workflow, represented in the figure below, takes care of the processing of batches of pictures or even a single picture. It sends them to an Image Processing service and stores them in the first level of graph processing. This graph describes faces and objects appearing in their own pictures, opportunely enriched with timing and geographical metadata. The workflow simply starts from a rabbit queue, getting the URL of the uploaded picture that is sent to the Image Processing services written in Python and equipped with the machine learning algorithms discussed above. Once the processing is completed, the response is split into different branches that process, via multiple Cypher queries, the data and store it in a Neo4j instance.
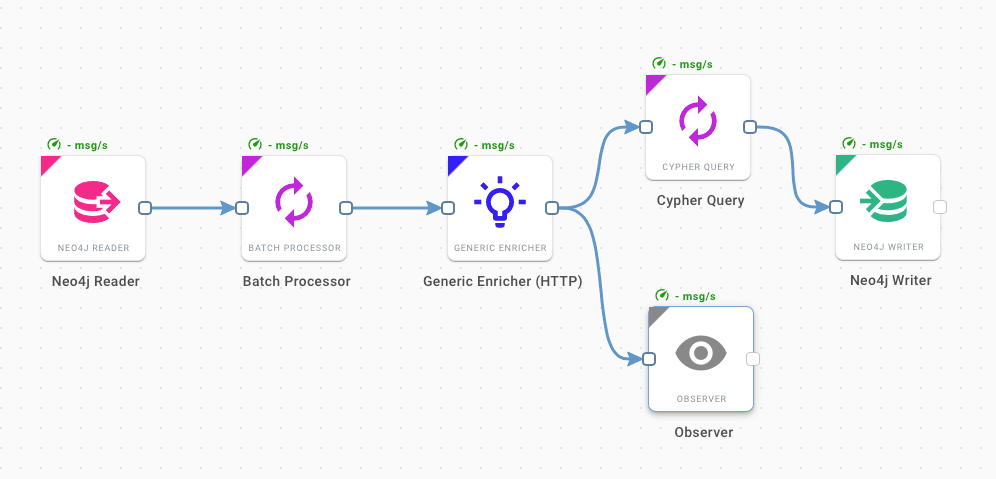
The second workflow (next figure) works on a batch of face nodes. It retrieves all the fingerprints and sends them to the Clustering back-end service that produces the clustering labels. Such labels are then exploited by a Cypher query that creates the subjects (nodes representing the collection of faces referring to the same subject), as well as the core concept, for representing the co-occurrences of people in a complex network of images.
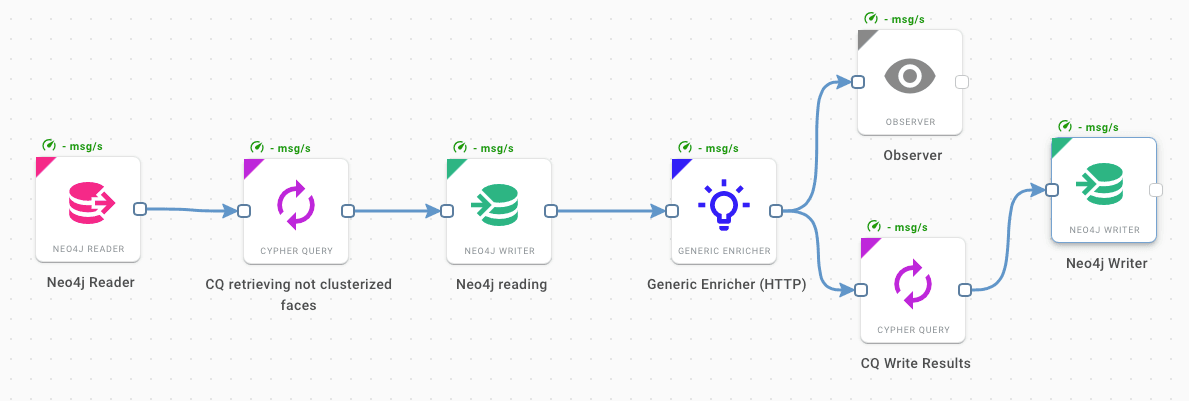
The last workflow (figure below) makes all the analyses useful in terms of exploring their purposes. It looks for face nodes marked as unclusterised (i.e. coming from a picture processed after the clustering step) and then provides their fingerprint to a specific service that returns the label of the subject, allowing the creation of relations between the new faces and a known subject.
It is indeed sort of a back-end providing data to the graph demanded by the “real” analysis. Hume turned out to be the key element for enhancing the graph analysis by means of its capabilities of handling the graph as a knowledge graph. The information about who the people are in a picture creates a relationship between the people nodes themselves. Such information enables, among others, the co-occurrence graph represented below. Note that in a single image, we can get a lot of information. The node size, for example, represents how often people appear in pictures.
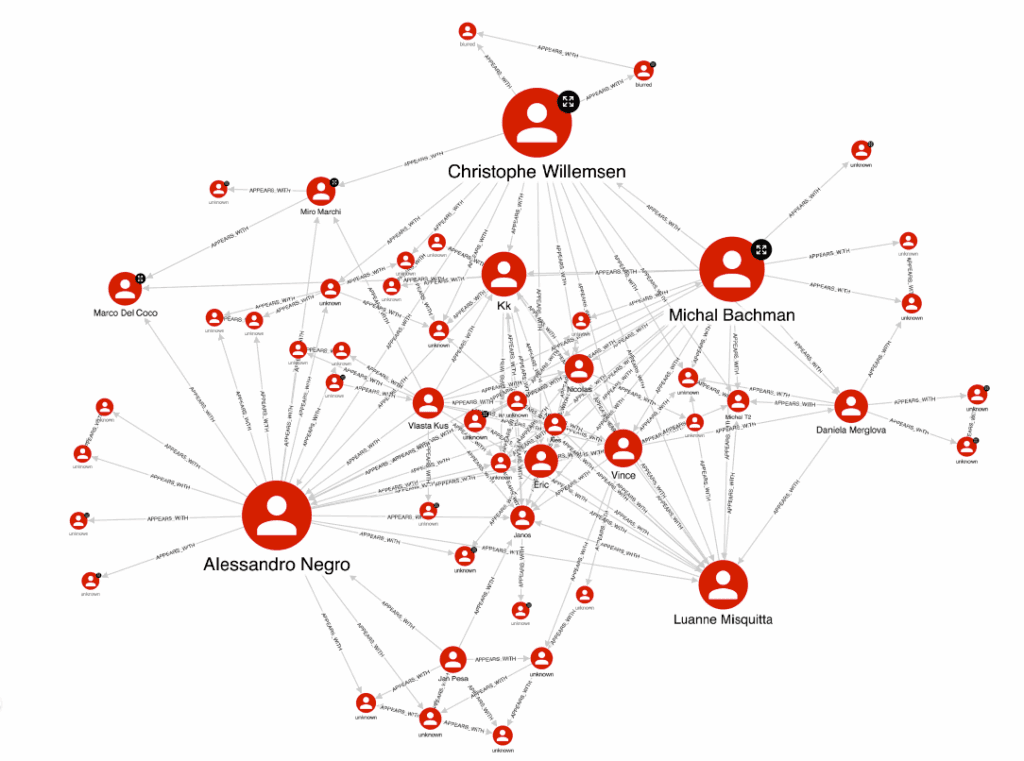
Moreover, the possibility to query the graph directly from the visualisation interface allowed the creation of smart functionalities for picture retrieving and linking with the involved subjects. We walked through many useful functionalities, such as the one shown below, that enable the user to select two subjects and have a look at the picture where they appear together.
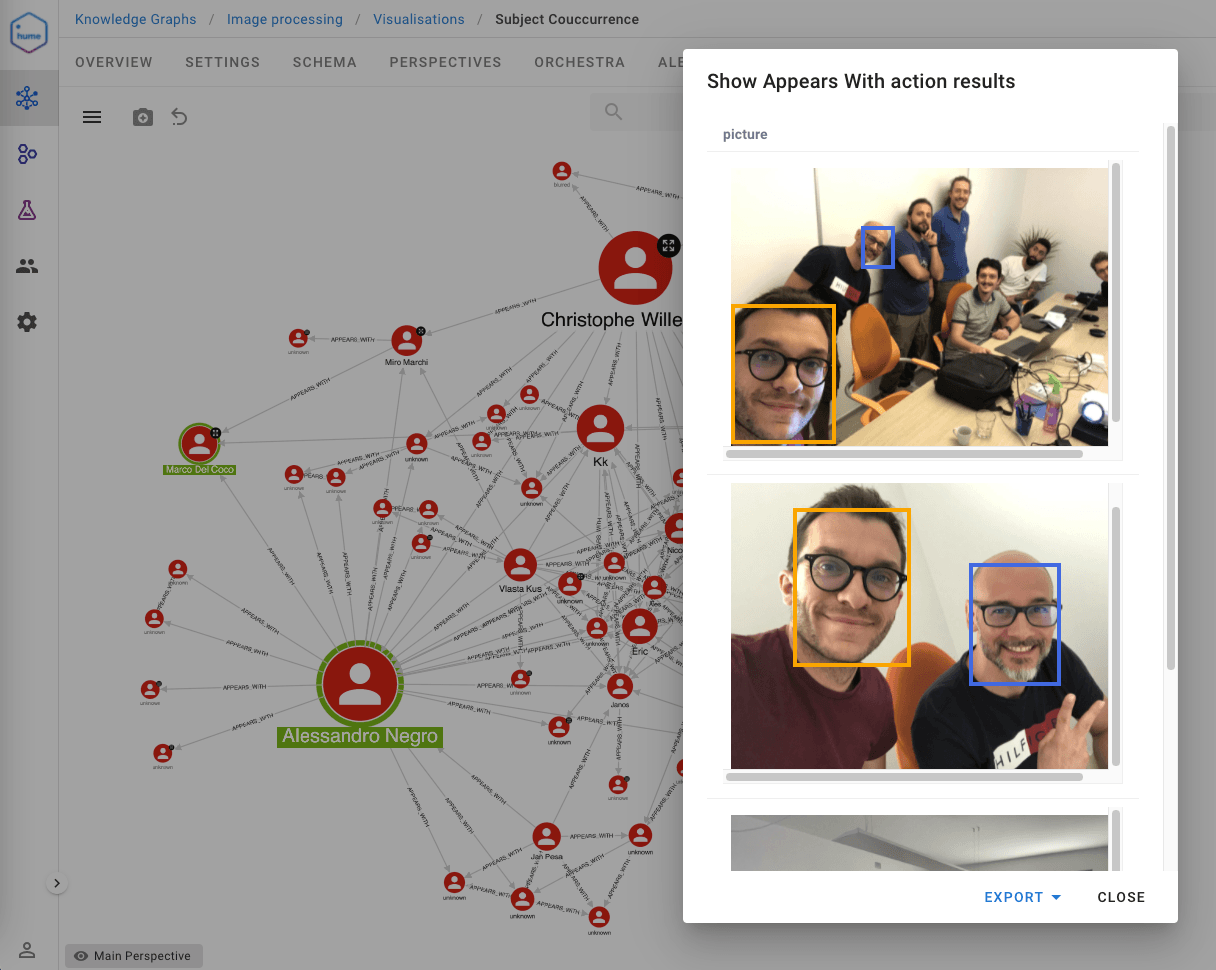
Having done that, I now look forward to improving the prototype capabilities, including real-time processing of videos, automating the clustering procedure over time, and exploring possible applications and opportunities.
When I started working in GraphAware, I was caught by one of the core values: “Believe in the value of graphs.” It sounded like a rigid constraint. After one month, I can say that it is not important to “Believe in the value of graphs,” because after my experience in using the graph approach, I personally experienced how graphs can completely change and improve your way of analysing data, creating amazing perspectives and mining new insights; so, in case you do not believe, just go and try it.
