
There is one common performance issue our clients run into when trying their first Cypher queries on a dataset in Neo4j. When writing a query, be sure that it doesn’t match any cycles, or you can experience unpleasant surprises.
Assume the following sample graph and simple query:
CREATE
(a:Node {name: "A"}),
(b:Node {name: "B"}),
(c:Node {name: "C"}),
(a)-[:TO {name: "1"}]->(b),
(a)-[:TO {name: "2"}]->(b),
(a)-[:TO {name: "3"}]->(b),
(b)-[:TO {name: "4"}]->(c)

MATCH p=({name: "A"})-[*..10]-({name: "C"}) RETURN p
The query returns 9 paths, instead of 3, as you might have guessed! The additional 6 paths have length 4 with node pattern A-B-A-B-C. Note the repeated nodes A and B, forming an unnecessary cycle A-B-A.
The reason is that when Neo4j traverses the graph with your Cypher query, it uses every edge only once (to prevent endless loops), but there is no similar constraint on nodes. Neo4j documentation states just that a series of connected nodes and relationships is called a “path”, without any limitations. Although graph theory definitions of “path” usually require the path to have distinct edges and nodes, other definitions are more relaxed about it, and the same applies to Neo4j.
There are a few implications to this fact, most significant is that if you have a large graph, you can experience a noticeable performance drop, because Neo4j searches across a much larger graph space than expected. Also, there is another possible issue if you expect your query to match nodes in exact distance, the query above can also match nodes in a shorter distance.
Performance benchmark
The performance impact of cycles in your graph model can be easily measured even on a small random graph:
CALL apoc.generate.ba(10, 3, 'Node', 'TO')
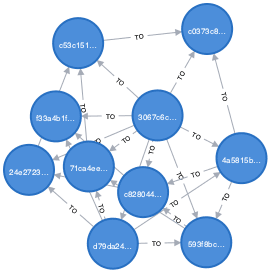
For additional bad impact, let’s duplicate all edges:
MATCH (n:Node)-[:TO]->(m:Node) CREATE (n)-[:TO]->(m), (n)-[:TO]->(m)
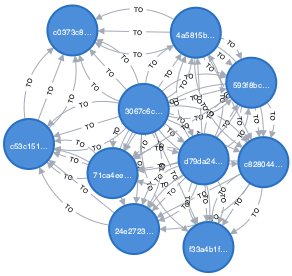
With this generated graph, I run a query allowing cycles between two nodes with max path length (N) ranging from 1 to 7, and record the number of returned paths and total time:
MATCH p=(n)-[*..N]-(m) WHERE ID(n) = 1 AND ID(m) = 2 RETURN count(p)
Results are growing exponentially:
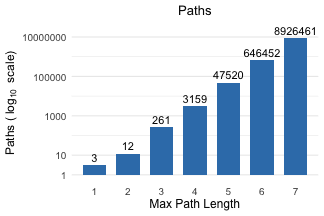
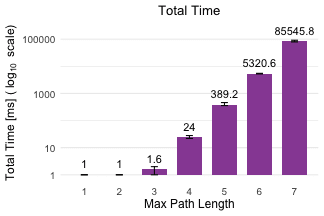
Compare it to a query that returns shortest paths only:
MATCH p=allShortestPaths((n)-[*..10]-(m)) WHERE ID(n) = 1 AND ID(m) = 2 RETURN count(p)
This query returns 3 paths immediately, regardless of the max path length.
Note: Queries were run in cypher-shell instead of Neo4j browser to eliminate possible UI bottlenecks, with a 4 GB Java heap size and warmed-up cache. Total time recorded is a sum of resultAvailableAfter and resultConsumedAfter times reported by Neo4j, averaged from 5 measurements, with min/max error bars.
Possible solutions
There is no simple recommendation; you should just be aware of this feature. Possible solutions to avoid this issue really depend on your use case; they include:
- Model your graph without parallel edges or other possible cycles
- search by patterns that don’t match existing cycles in your graph
- search with explicit edge direction
MATCH p=({name: "A"})-[*..10]->({name: "C"}) RETURN p - search for the shortest paths instead of any path
MATCH p=allShortestPaths(({name: "A"})-[*..10]->({name: "C"})) RETURN p
- search with explicit edge direction
- filter out paths with repeated nodes (no performance gain, but helps with the usecase of matching nodes in exact distance)
MATCH p=({name: "A"})-[*3]-({name: "C"}) WHERE length(nodes(p)) = length(apoc.coll.toSet(nodes(p))) RETURN p - build a custom procedure
Or get in touch with GraphAware to see how we can help you to performance-optimise your queries!