“Lateral thinking” was a big topic back in 2004, when I was in the Network Operations Centre (NOC) business; one definition is:
“(lateral thinking) is the solving of problems by an indirect and creative approach, typically through viewing the issue in a new and unusual light.”

If it works, don’t touch it
But the world of NOC operations, and generally IT Operations was anything but creative, not because we didn’t appreciate innovation per se, but because we valued reliability, consistency an uptime above all things, and those outcomes are the result of a long tradition in IT of approaching change, the natural by-product of innovation, as something that “must be managed”.
And managing change is indeed an effective way to prevent disruption of services because if something is working, and we avoid or slow down changes from happening around, the service will most likely continue to work.
This philosophy is one of the core tenets of ITIL, the best-known IT service management (ITSM) framework and supreme ruler of the IT Operations world, an important and necessary development to bring order to the apparent chaos of IT in the early ’80s, which, to the much surprise of its critics, has a very noble purpose:
“(ITIL) … looking at a means of ‘standardizing’ good practices in IT that would essentially provide a common language for IT operations and reduce (the) cost of IT (because people would be more efficient)…”
A new force awakens
And thus the cycle of life continues. When we have too many changes going on, we strive for order and consistency, but too much of that, and we look back for speed and agility, hence the emergence of DevOps as the name of the force pushing for means to move the IT engine faster and deliver services quickly.
DevOps is also a good thing; it strives for cross-disciplinary collaboration and straight lines of communication, as opposed to ITIL, which, although a corruption of the original purpose, effectively created a bureaucratic culture to the point of business-halting rigidity and “not my problem” mentality.
However, DevOps missed the point initially by failing to realise that there is so much more to providing services than only Dev and Ops, a situation that has created afterthoughts like “DevSecOps” or “BizDevQASecOps”. Many DevOps practitioners have no experience with or choose to ignore vital concepts like budgets, profit & loss, security, SLA breach billing, regulatory compliance, business continuity planning, etc.
Technology changed as well; IT became central to most businesses’ operations, whereas it played a supporting role during the time ITIL came to life. And here we are today, expecting the best of both worlds:
- We want new features faster, and we want services that scale globally. We demand that traditional companies move as quickly as startups that have no financial obligations
- However, we are not willing to withstand downtime; we want these infinitely scalable, fast-delivered services to be reliable, rock-solid, like the phone service, which is a (successful) product of big, slow-moving telco corporations using ITIL principles for decades.
Carpe diem
Whenever two cultures collide, there is an opportunity to evaluate existing practices and to replace some of them with better ones, and one of the most powerful ways to apply “lateral thinking” in the IT world is to augment ITSM practices with graph theory to quickly integrate (good) DevOps practices. Here is an example:
In late 2017, we had a client in the high-frequency online-betting industry, who had two datacenters running IT services on top of “traditional” stacks (physical or virtual servers hosting “monolithic” applications with a database, business and application layers).
For this “standard” approach, they already had in place one of the myriads of ITIL/ITSM tools that can control the lifecycle of assets and services, and it was feeding a change-management database (CMDB), the fundamental data-warehouse component.
Our client had spent close to two years building a new hybrid cloud-physical datacenter and had fully embraced a DevOps culture; all services were scalable and made with new micro-services paradigms in mind; therefore, they were all loosely coupled and designed to adapt and grow automatically.
Network connections, firewall rules, hostnames, DNS records, everything was temporary and constantly changing.
And now they were facing one of the biggest, often swept-under-the-rug conundrums of going all-in DevOps: How do you link measurements of reliability and uptime from constantly-changing infrastructure and not-always-running back-end systems (a.k.a. “Chaos engineering”) to business services?
And, also, how do we know we have built and deployed all the services that currently exist in our “production” datacenters into this new, “modern” one?
These are difficult questions because at any given time a single “business service” (e.g. the online store) depends on a handful of other “IT services” (e.g. the bank’s “credit card payments gateway”, the “client authentication/SSO system”, and, of course, the “inventory system”). And each of these cascades into hundreds, likely thousands of infrastructure components they depend on:
API endpoints, web servers, web balancers, content-distribution networks, servers, container orchestration tools, IP addressing, firewalls, DNS, LDAP, cloud providers, physical infrastructure components, cables, racks, etc.
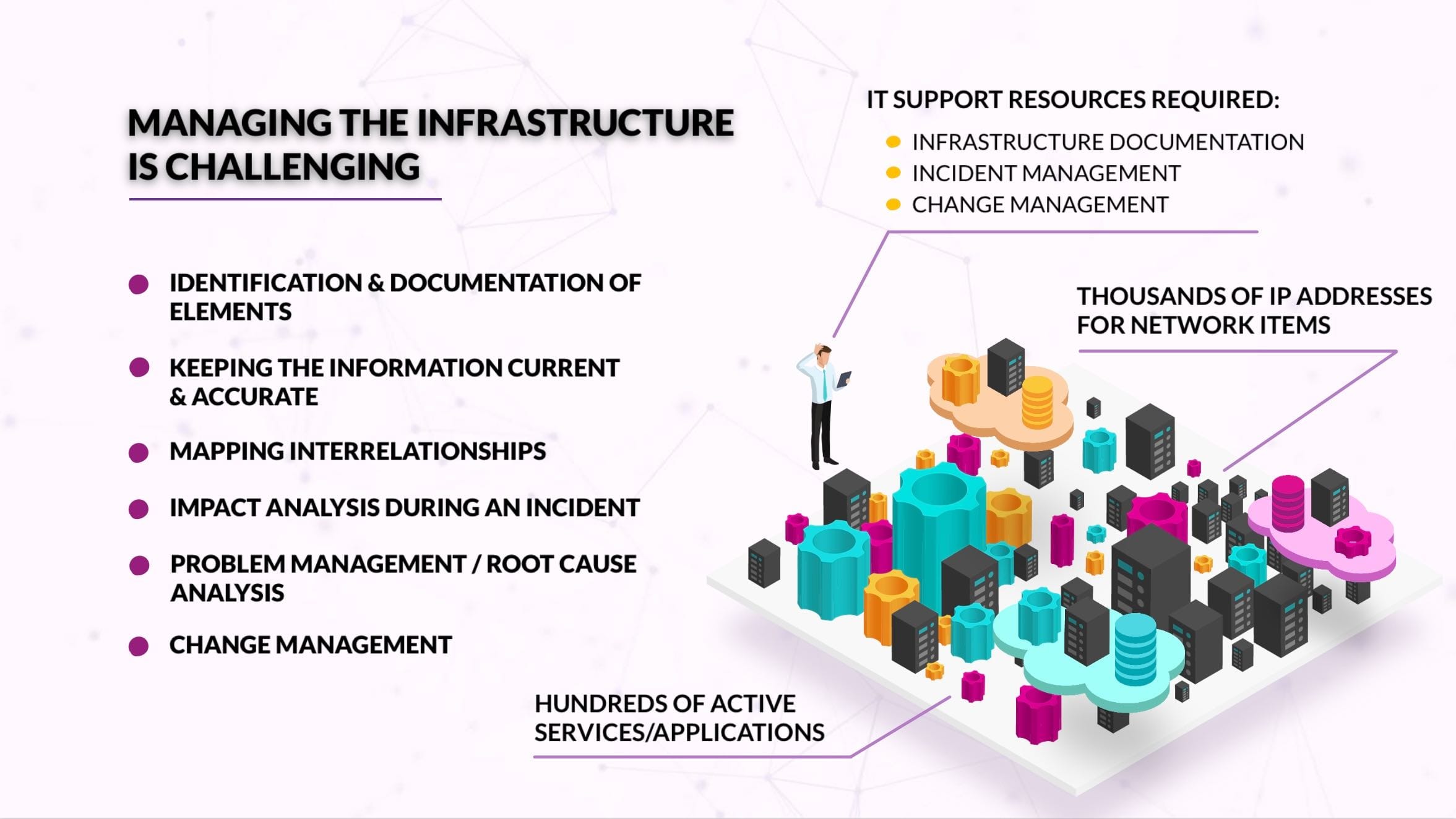
In a pre-DevOps, pre-micro-services world, the answer would be not-sexy, but extremely simple: Send an army of engineers to the data centre for a couple of weeks to inventory, document and seal everything; create a handful of network and business diagrams and turn them into Configuration Items (CIs) in the CMDB. But that is outright impossible to do with a DevOps-inspired, micro-services, hybrid architecture.
Our client invested about two months trying “to plug” the new data centre into the existing CMDB, but it quickly became evident that this would be the wrong approach:
- Most DevOps tools and workflows lack the concept of “business service”, let alone the facilities to integrate with existing ITSM tools
- A custom integration would incur a very high cost, as most ITIL vendors license their software by the unique number of components managed and are not yet ready to support “ephemeral” elements
- It would be too slow, “convergence” of information through ITSM tools would take hours, and in some cases, the next day was the only option.
IT is a graph
We spent a week helping our client to get the best out of both worlds using a graph database and graph theory:
- We built an always-accurate, always up-to-date graph representing all components and their relationships across all physical and virtual layers on both the old and new data centres running “ETL pipelines” directly from the data sources: Infrastructure vendor’s APIs (e.g. VMWare’s vCenter, AWS EC2 or Docker’s engine) AND the network services (e.g. IPAM, DHCP, DNS) AND authentication systems (e.g. Active Directory and SSO) AND architecture/datacenter diagrams

- Using our trigger and audit modules, we could detect and react to change within milliseconds, anywhere across all of the OSI model layers.
- Looking at IT data as a knowledge graph, and each vendor’s data as different ontologies linked by network services (DNS, and established connections), we could abstract IT services and provide means to reason about the relationships from different angles (e.g. database administrators, architects, business stakeholders or NOC engineers)

- Taking advantage of our platform’s natural-language processing capabilities (NLP), we could link all knowledge documents (wikis, operation manuals, tickets) to “services”
- And finally, using cluster-detection algorithms, we created a one-to-one equivalence between both the traditional and the new IT stacks and their supported business services and identified the missing elements:
- Authentication systems for customer service representatives
- Batch processes and other services are needed only during specific dates or exceptional circumstances
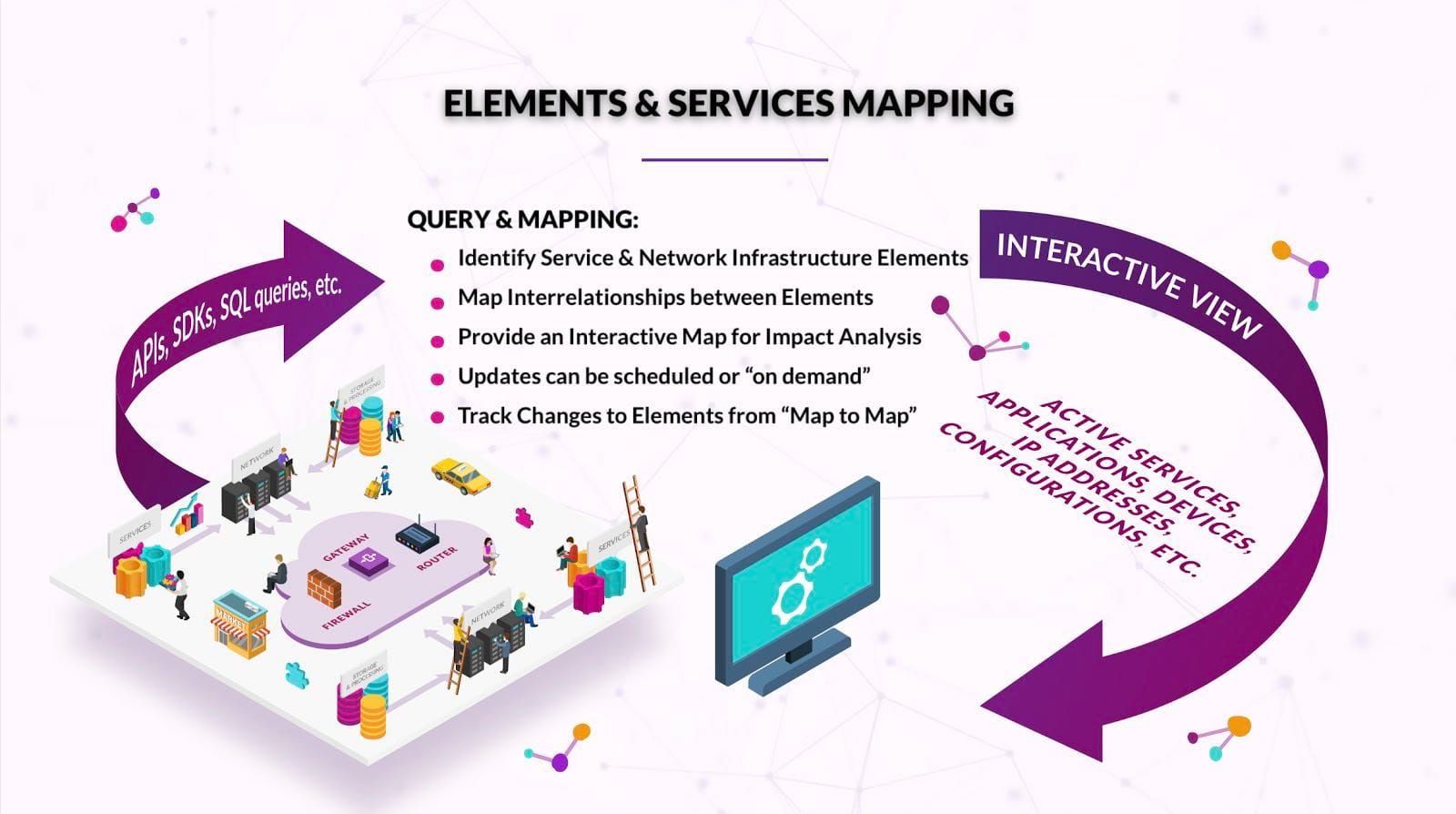
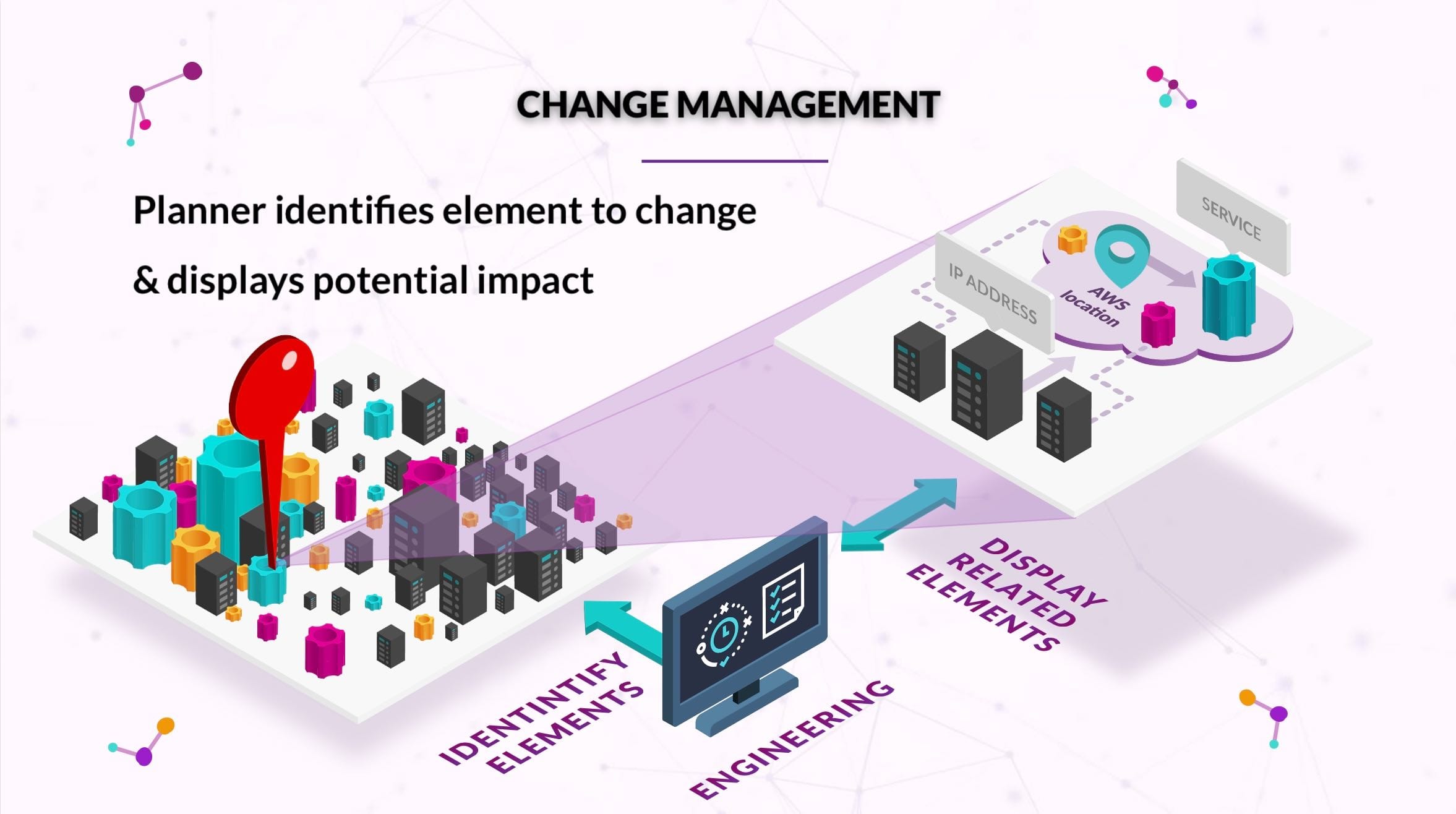
Using graphs is a very straight-forward and fast way to get the best out of both the DevOps and ITIL worlds in the modern enterprise.