
The Cypher query planner is quite advanced and mature, and you can mostly rely on it to pick the best plan for your query. However, there are rare cases, or bugs, that might prompt you to look for ways to influence that plan. This article demonstrates the practical usage of an index hint.
Note that all queries were tested against Neo4j Enterprise 3.5.8
The graph model
This is the relevant portion of the graph model that is sufficient to demonstrate the issue.

Simple enough- we have many tweets, and tweets have keywords. Our graph has two indices, one on the value of the Keyword, and the other on created_date of the Tweet.
Vlasta, my colleague, noticed that a simple query started to perform more slowly over time, as the number of tweets in the graph grew. The innocuous query looked like
MATCH (k:Keyword)<-[r:CONTAINS_KEYWORD]-(t:Tweet)
WHERE k.value IN ['c4160609-ebf9-4197-9dc3-86839e3bd278'] AND t.created_date > 1566123035893
return t,k
He assured us that only one Keyword The node in the graph had this particular value, and it had a handful of tweets related to it. This sounded quite odd since we’d expect that the starting point for traversing the graph would be this lone Keyword, and from there on, it would traverse a few relationships, retrieve the tweets which satisfied the created_date condition, and return.
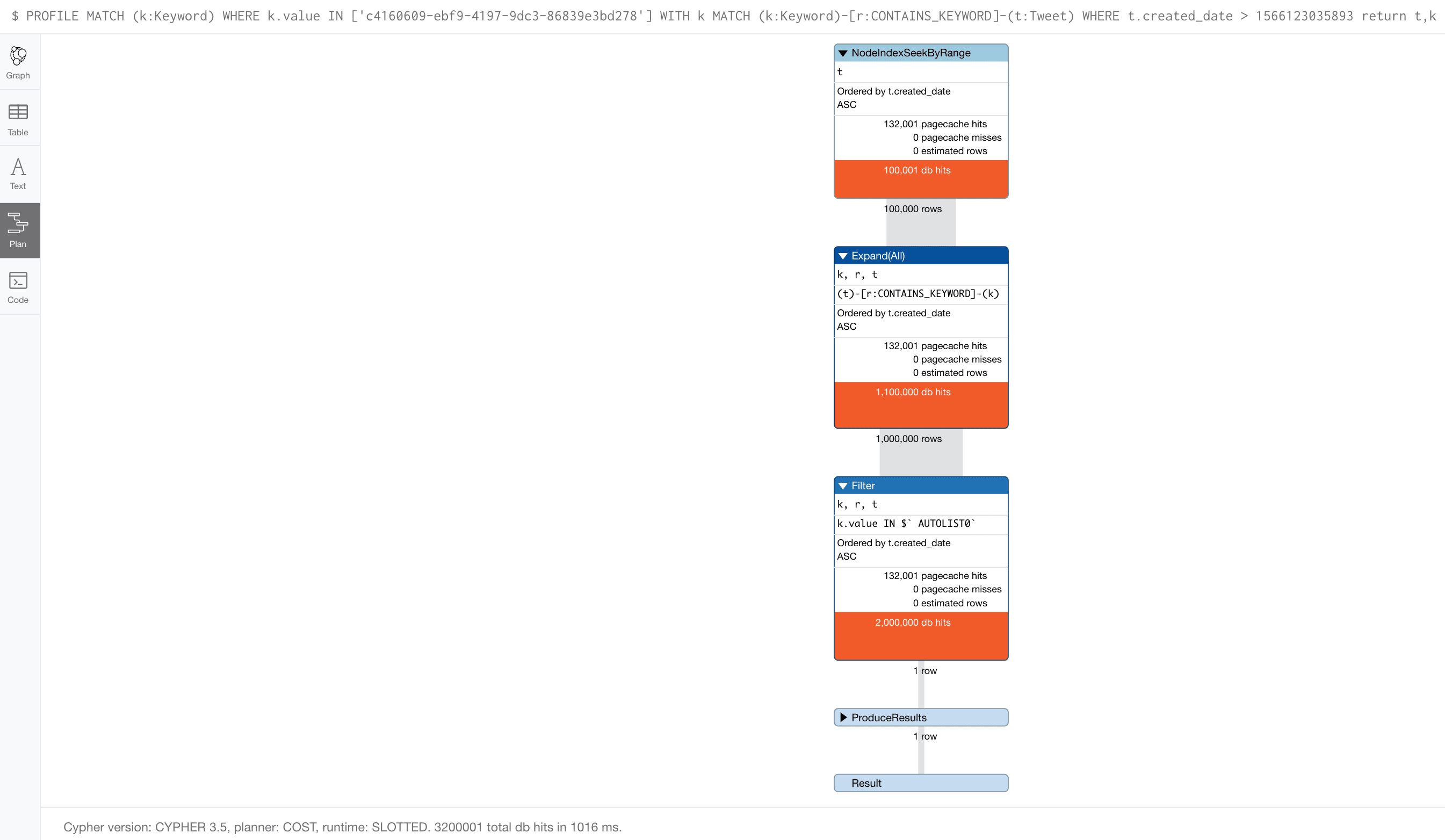
So we asked him for the query plan, and to our surprise, it looked like this (note that the query plan shown here is from a generated graph that represents the issue):

Approximately 100,000 tweets in the graph are found via the Tweet index on created_date, and subsequently, expanded to their keywords via the CONTAINS_KEYWORDS relationship, and then filtered down to the single row that matches the keyword in our query!
We tried a variety of query rewrites, such as
MATCH (k:Keyword)
WHERE k.value IN ['c4160609-ebf9-4197-9dc3-86839e3bd278']
WITH k
MATCH (k:Keyword)-[r:CONTAINS_KEYWORD]-(t:Tweet)
WHERE t.created_date > 1566123035893
return t,k
and it produced the same plan
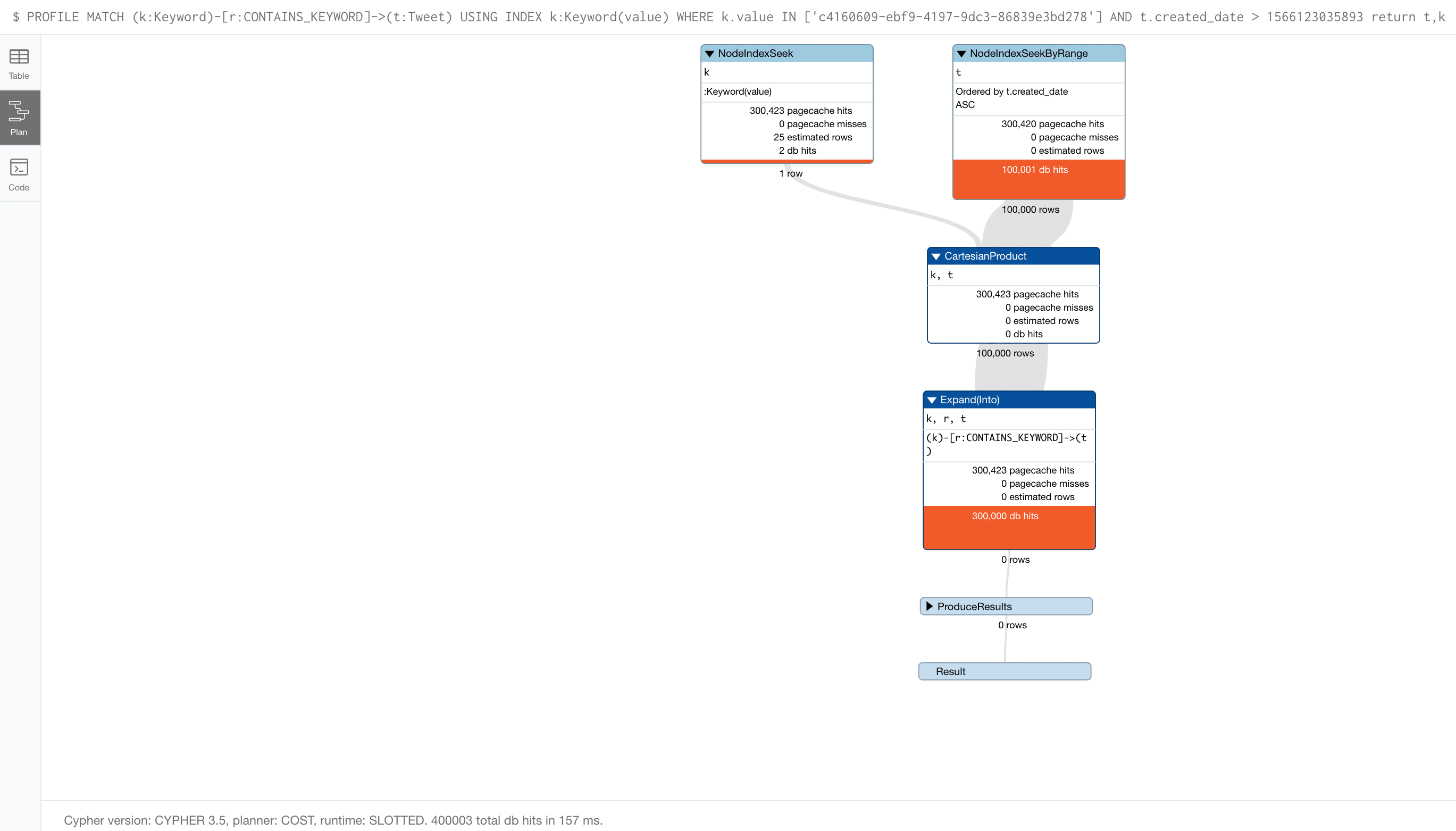
Only at this stage did we resort to an index hint, to tell the planner that we think it should use the Keyword index, knowing that we have fewer keywords as compared to tweets, and the keywords have unique values.
We provide the hint as follows, and the number of db hits now drops to 400005 from 2200002, and we see the NodeIndexSeek being employed with the Keyword index as we initially expected.
MATCH (k:Keyword)<-[r:CONTAINS_KEYWORD]-(t:Tweet)
USING INDEX k:Keyword(value)
WHERE k.value IN ['c4160609-ebf9-4197-9dc3-86839e3bd278'] AND t.created_date > 1566123035893
return t,k

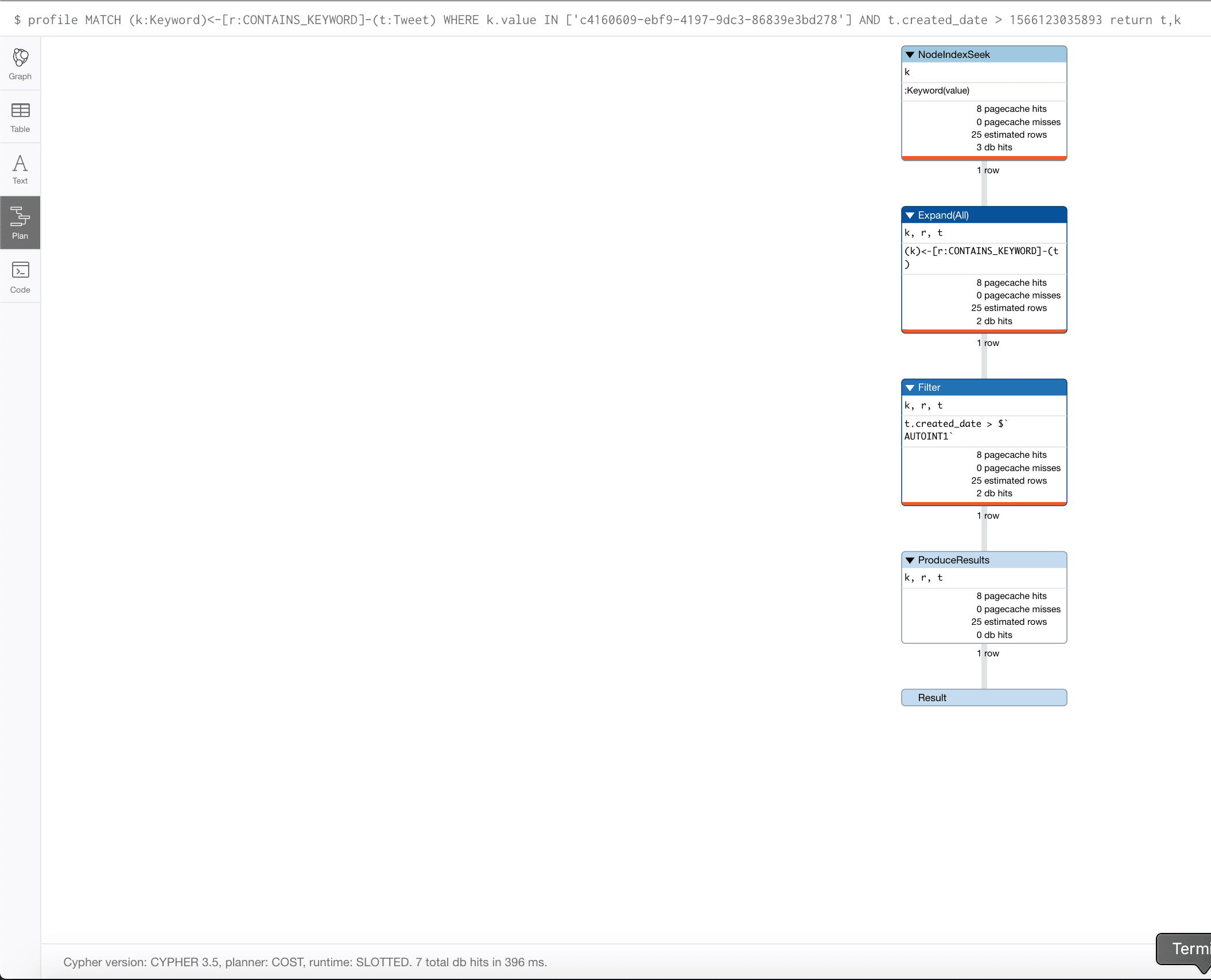
Note that had we not created the index on Tweet, our original query
MATCH (k:Keyword)<-[r:CONTAINS_KEYWORD]-(t:Tweet)
WHERE k.value IN ['c4160609-ebf9-4197-9dc3-86839e3bd278'] AND t.created_date > 1566123035893
return t,k
would have worked just fine as shown below

We did, however, need this index for other use cases, and hence the query hint was the best solution at that point.
The fix is coming!
Thanks to the good engineers at Neo4j, this issue will be fixed in 3.5.9
Update: As promised, the issue has been fixed in 3.5.9, producing the expected query plan
Summary
This was indeed a rare case which resulted in the usage of query hints.
As stated in the manual (and also, premature optimisation is the root cause of all evil), this should be used with caution, and after you’ve tried everything else, making sure that you clearly understand the characteristics and shape of your graph and are confident enough to instruct the Cypher planner.
