
GraphTour Europe 2020 started in Amsterdam on February 4, right after the release of Neo4j 4.0, a key milestone in the graph technology landscape. At GraphAware we are very excited about the new features included in this release because they revolutionize the way we approach some common graph challenges. Our CEO, Michal Bachman spoke about this in Amsterdam in his talk “Practical Applications of Neo4j 4.0”, and he and other GraphAware experts continue to present in each of the six cities where we sponsor GraphTour.
GraphAware and Neo4j
At GraphAware we have been working with Neo4j for many years, some of us for more than 10, and we have never been so excited about a release. We feel this excitement from our customers as well. They were eager to see previews before the release date, and are now asking for upgrades and solutions. Let’s see why.
We will focus on three main new features in Neo4j 4.0: we will dive into fine-grained security, with law enforcement and intelligence as an example; we will see how multi-database helps in three different single-tenant use cases; and how the increased scalability enables stronger graph-based machine learning.
Nearly seven years ago, GraphAware started with the vision that many problems and challenges faced by enterprises, governments, and other organisations can be more efficiently solved, or solved entirely using graph-based solutions.
We wanted to help people “see the light” in the first place. The full rooms at each GraphTour clearly show that this part is done. Then we wanted to help people succeed with these graph technologies, so that they don’t become some sort of hype that is quickly over and fades away, but rather a long-term solution to many of the problems we face in today’s highly connected world. And that’s what we’re doing to this day: consulting and building tools and products that make it easier for people around the world to succeed with graphs for the long run.
We pretty much exclusively focus on Neo4j, because we genuinely believe it is the best graph database out there. Graphs are complex and challenging beasts, theoretically for scientists and mathematicians, as well as practically for engineers. Neo4j is tackling these challenges with incredible speed and solid design decisions, and high-quality engineering. There’s no better proof of that than the current release. So let’s jump right into it.
Fine-grained Security in Law Enforcement and Intelligence
We do a lot of work in the law enforcement, intelligence, and national security domain. It is an exciting field but of course our marketing department absolutely hates it, because you can’t talk about it too much or publish case studies. One thing that’s interesting about this domain is that data security is super important, potentially a matter of life and death. Think what happens to people who are part of covert operations, if their identities get revealed, for example.

So say we have a junior analyst investigating a crime and he would like to know whether these two individuals are in any way connected.
By the way, for those completely new to graph databases, this is a kind of problem that is very hard to solve with other technologies, because, in SQL for instance, you have to enumerate all the possible ways they could be connected. And that’s almost impossible, especially if the length of the potential path is completely unknown.
But in Neo4j you just run a shortest path algorithm and you find the answer very quickly.

But OOPS! We were not supposed to see that. This information should have been hidden from the junior analyst, because this officer in the middle is a secret officer who already investigated those individuals.
So what is it that we had to do before Neo4j 4.0 release? We had to apply some security on the application layer, typically filter out classified results, and ask the database for more results.

But there are no more results. Maybe there are some connections between those two people, but they aren’t shortest anymore, because all shortest paths have been discarded. So you see the challenge.
What was our next option? We had to modify our queries.
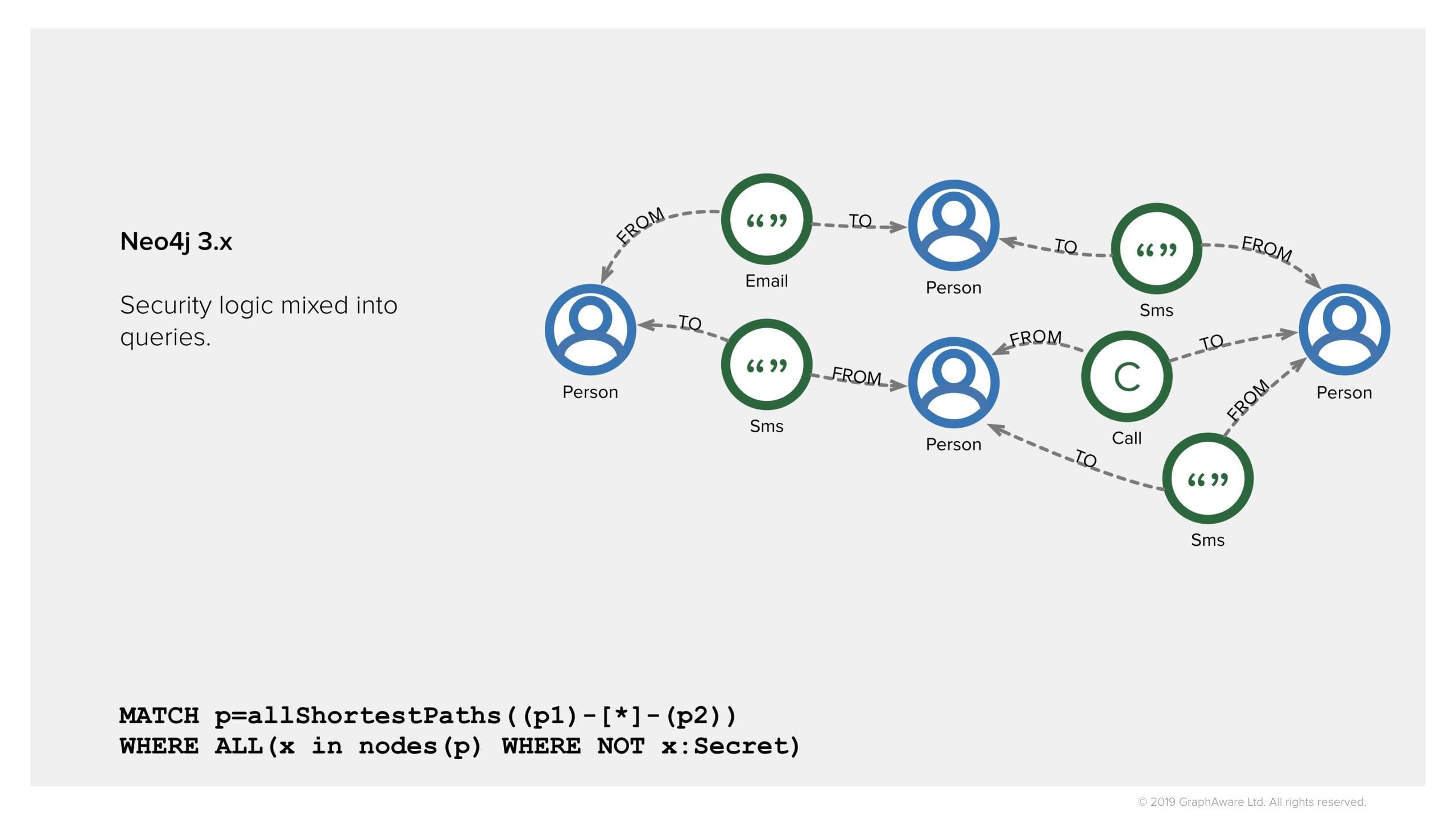
Here we go, new query with security, and in fact we see there are some paths between the two individuals. They reveal the fact that these individuals have been communicating, which may be interesting for the investigation of the junior analyst.
But now every single query will be polluted with security logic, that in the real world would be much more complicated than this. We have to deal with complex and changing rules, and team memberships, and ad hoc code which is error prone and needs solid testing.
Neo4j 4.0 completely changes all this. Neo4j 4.0 lets you apply security down to the node, relationship, and even property levels. In a declarative and transparent way.
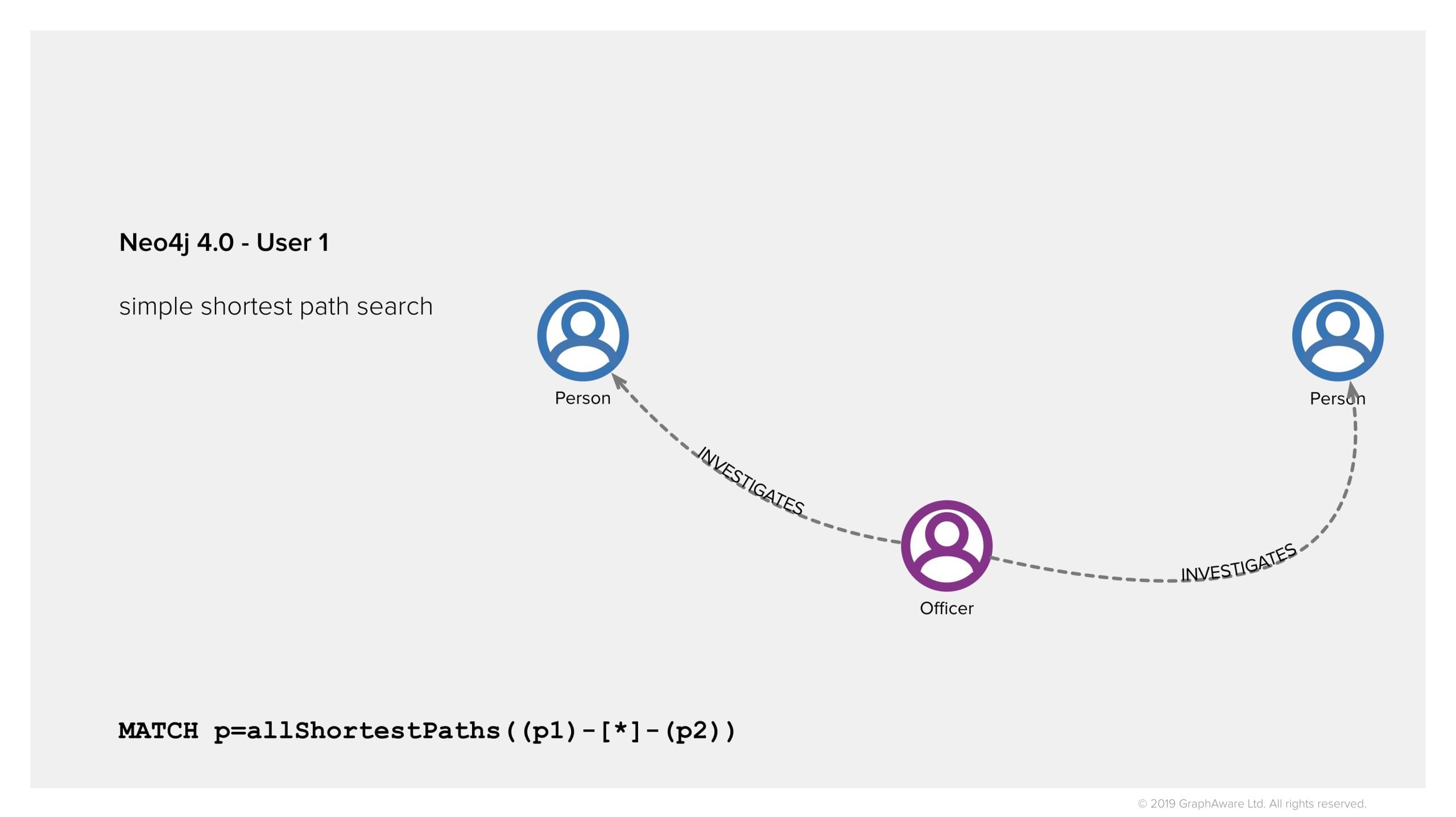
A user with high privileges or top secret clearance or whatever your organisation’s security model is based on, can now run a simple shortest path query and get the actual real shortest path. They would see the secret officer node, in our example.
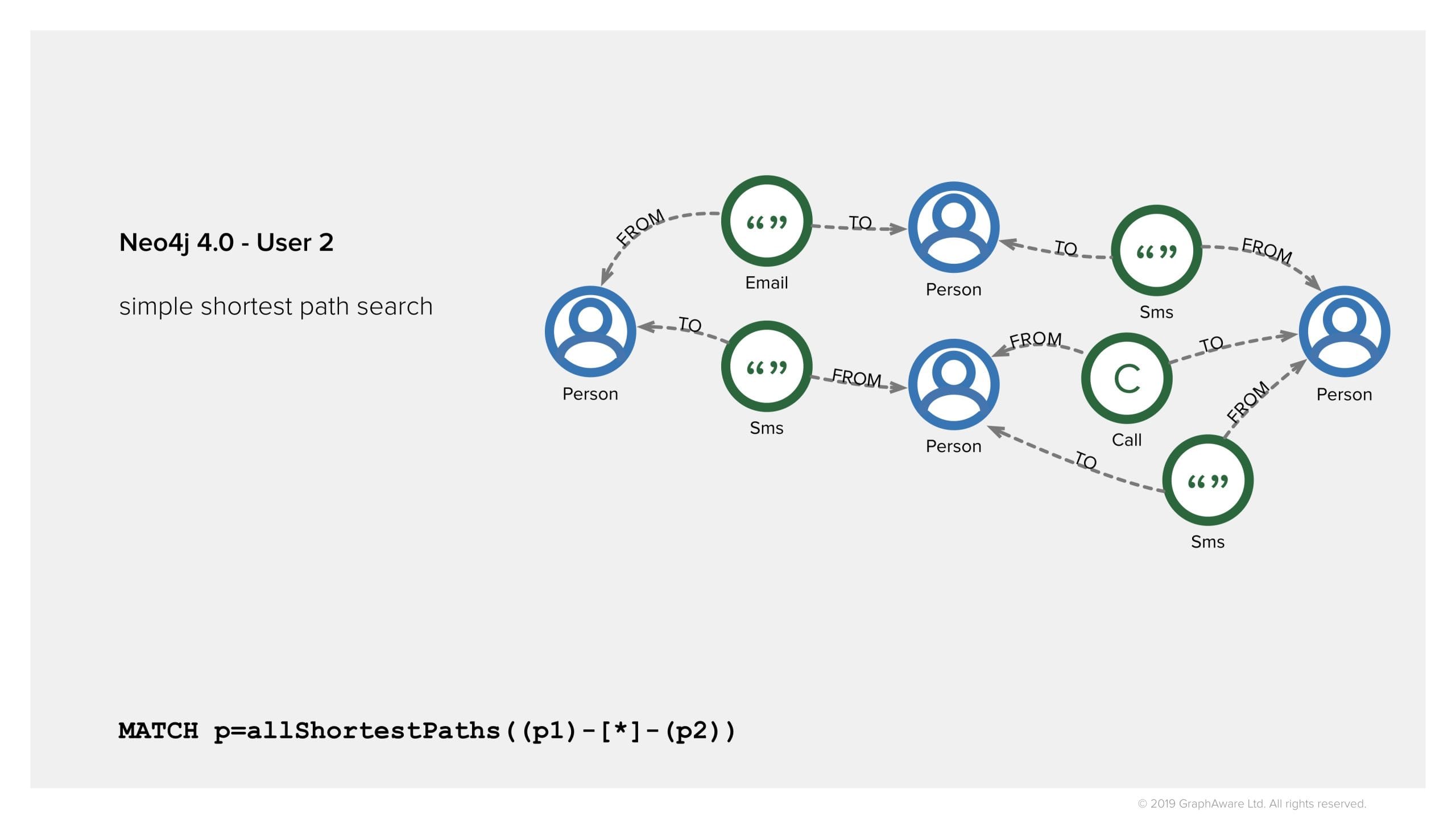
However, if another user who is a junior analyst runs the very same query, they will find completely different results, only consisting of the nodes and relationships they are allowed to see. No query changes!
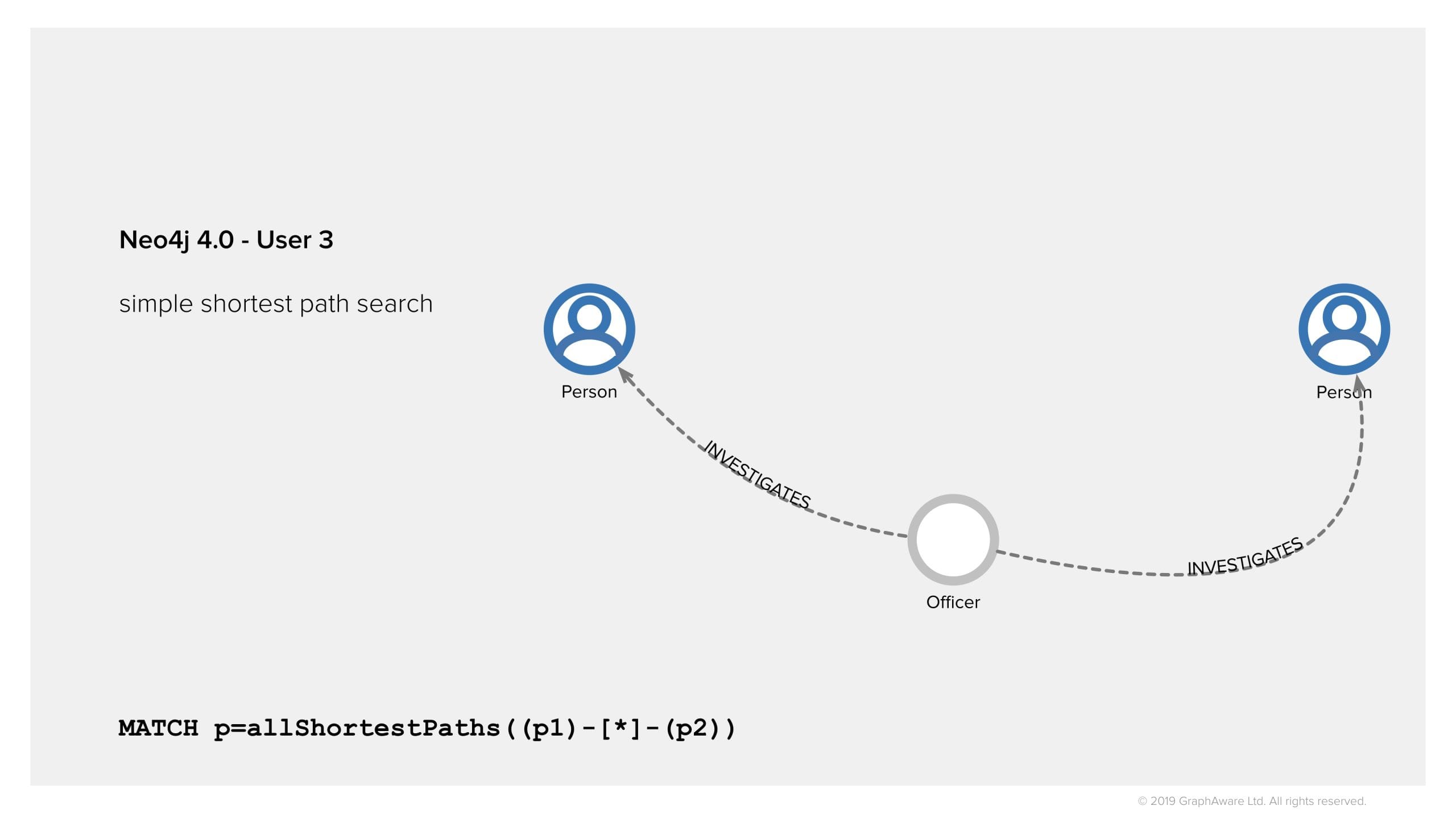
Finally, and this is a proof that Neo4j has tackled the issue of Security in Graphs in a proper way, there is a third option where a user, perhaps more senior analyst, has the right to see that there is a path, an officer who investigated these two individuals, but cannot see any details about it. All the properties of the node are hidden. It is like a ghost node. This is very, very useful.
To us, Neo4j 4.0 is worth it just for this – let your database handle the security for you, transparently and with a flexible configuration. This feature is very useful and practically applicable to any use case where not everybody can see everything.
Multi-database in single-tenant use cases
For the first time ever, Neo4j offers the ability to run multiple databases at the same time in one server instance or cluster. One clear practical application for this is multi-tenancy, where you want to completely separate data of your tenants. We covered this use-case in a recent blog post.
Here instead we will mention three practical applications of this feature to single-tenant scenarios. All of them have something in common with each other, and with the classic multi-tenancy case as well, which is the fact that people had to find a way to handle these cases prior to Neo4j 4.0. So we will try to contrast these approaches with what it looks like now.
In a number of applications you would like to have multiple logically disconnected graphs.
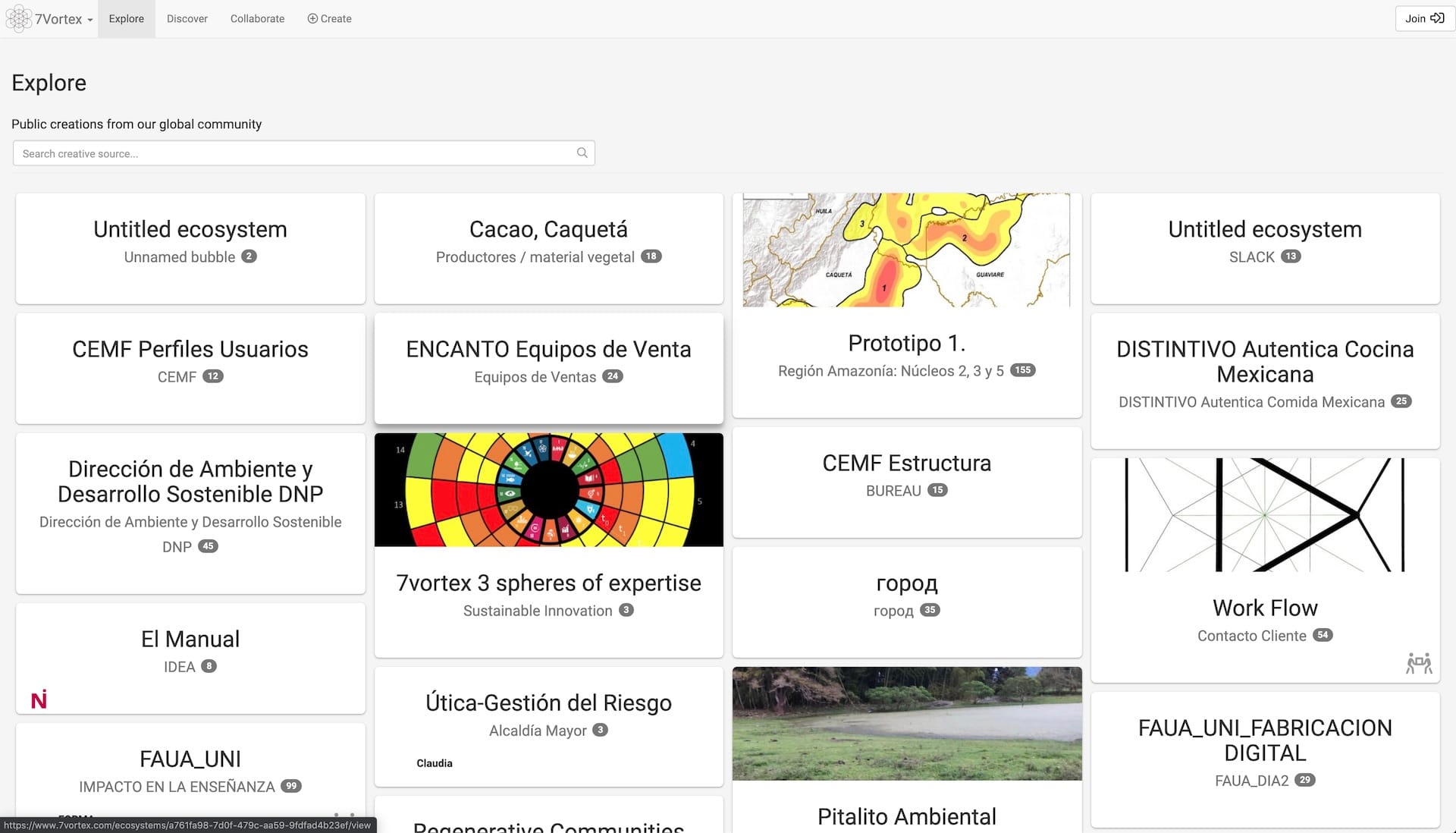
Take for example one of our clients, 7Vortex, which enables people to create their own knowledge ecosystems.
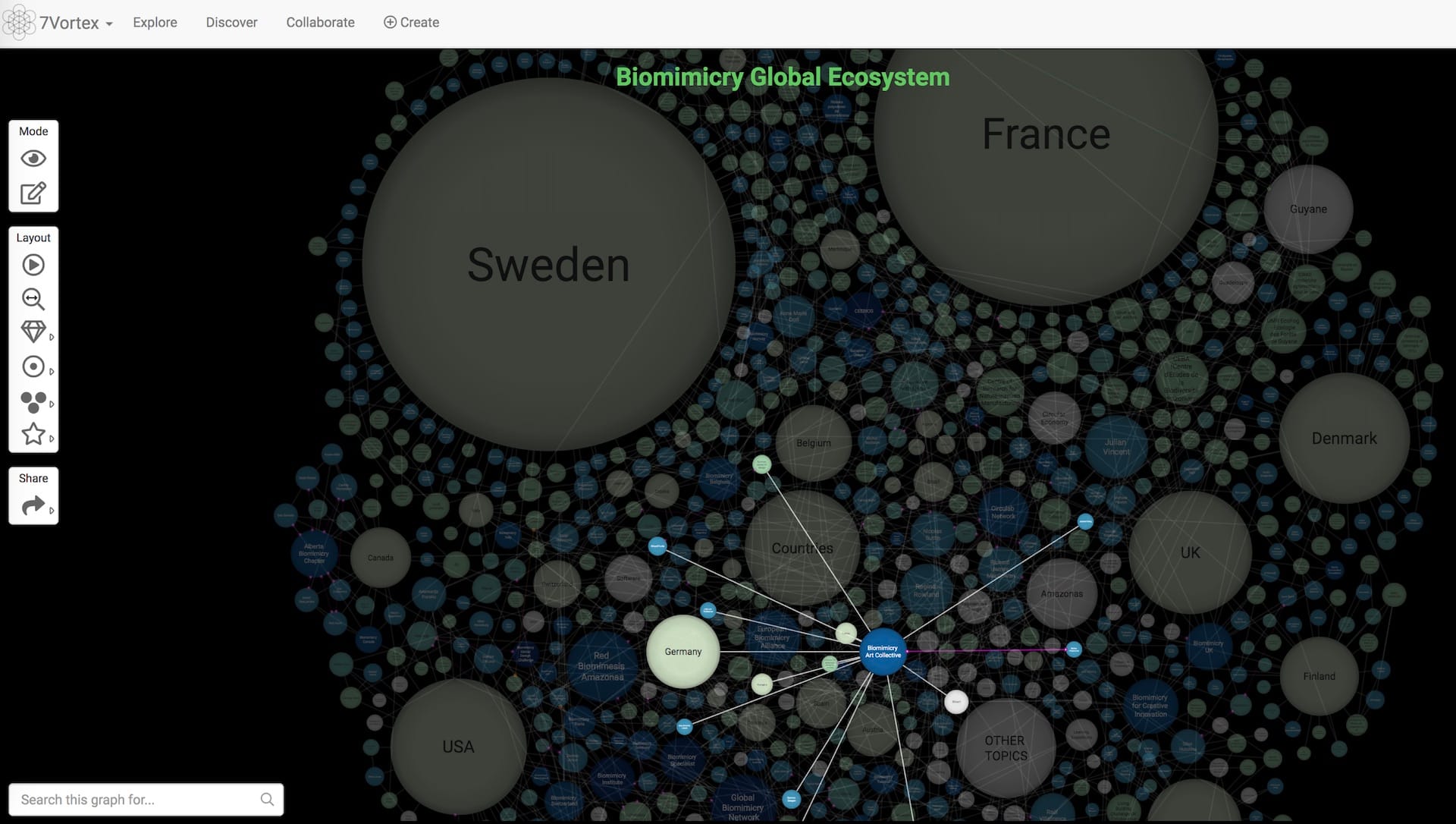
There are thousands of small graphs in the system and they currently live in a single Neo4j database. Neo4j 4.0 will allow them to be truly physically separated.
Or take Hume as another example. Hume is our own product, a graph-powered insights engine built on top of Neo4j. What it does is that it creates knowledge graphs from structured and unstructured data, such as natural language text.
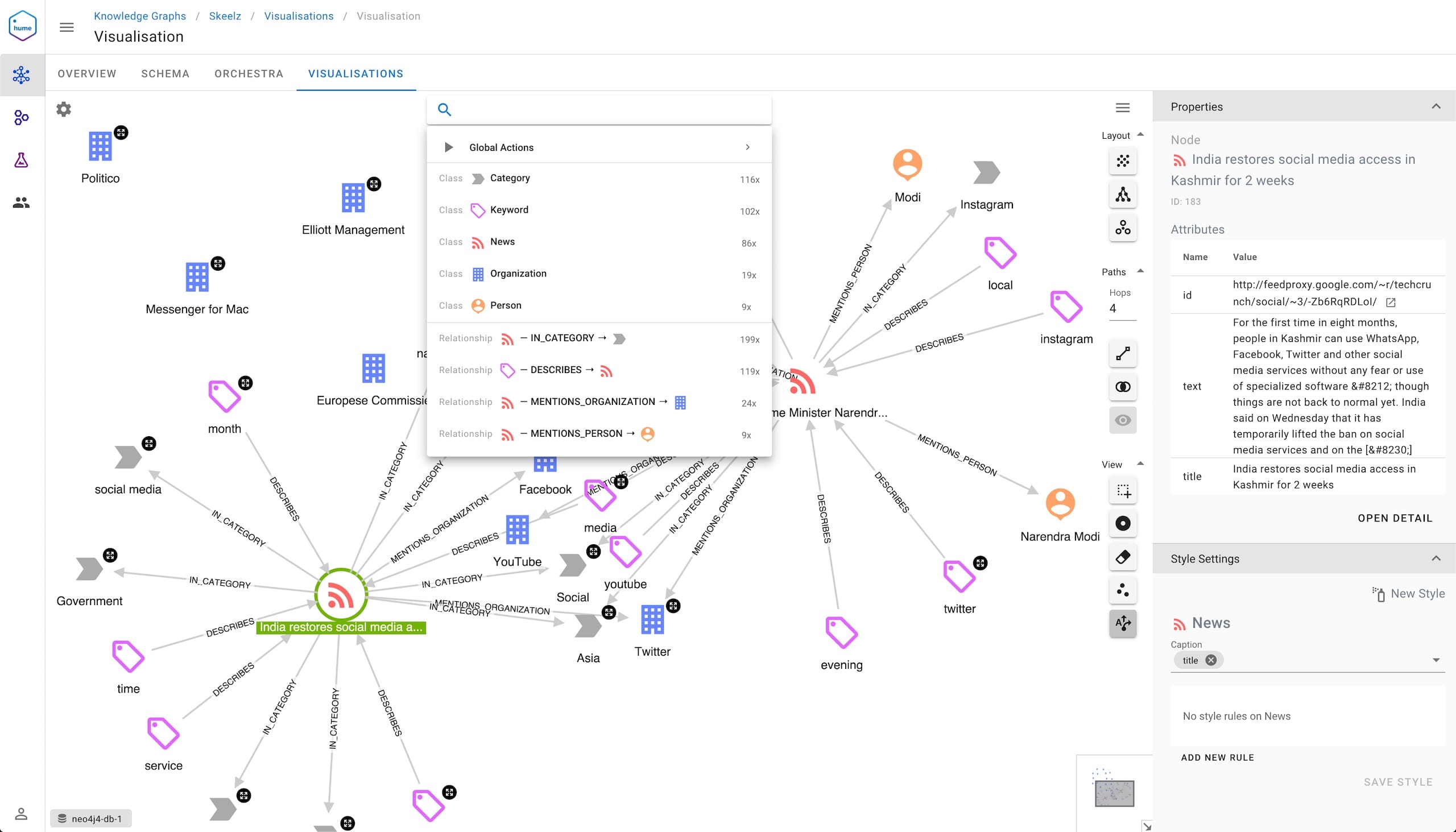
It creates knowledge graphs like the one above and our users, even if they are single tenant in the application, want to create logically disconnected knowledge graphs. Maybe because one knowledge graph is about a specific domain in the company, and another about a different domain, or maybe because it is a test of some kind, or for many other reasons.
So what did the separation of these knowledge graphs look like before Neo4j 4.0?
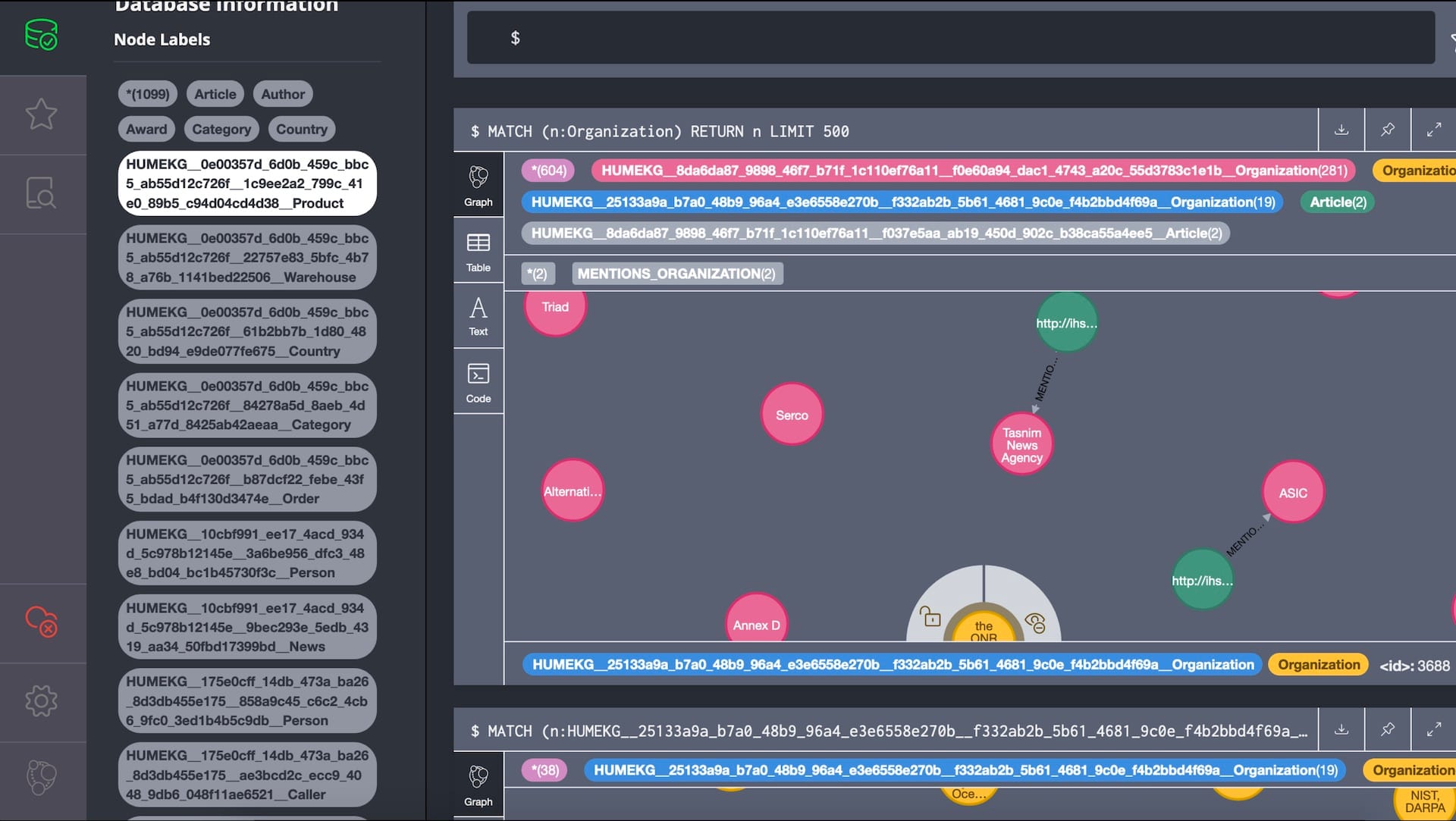
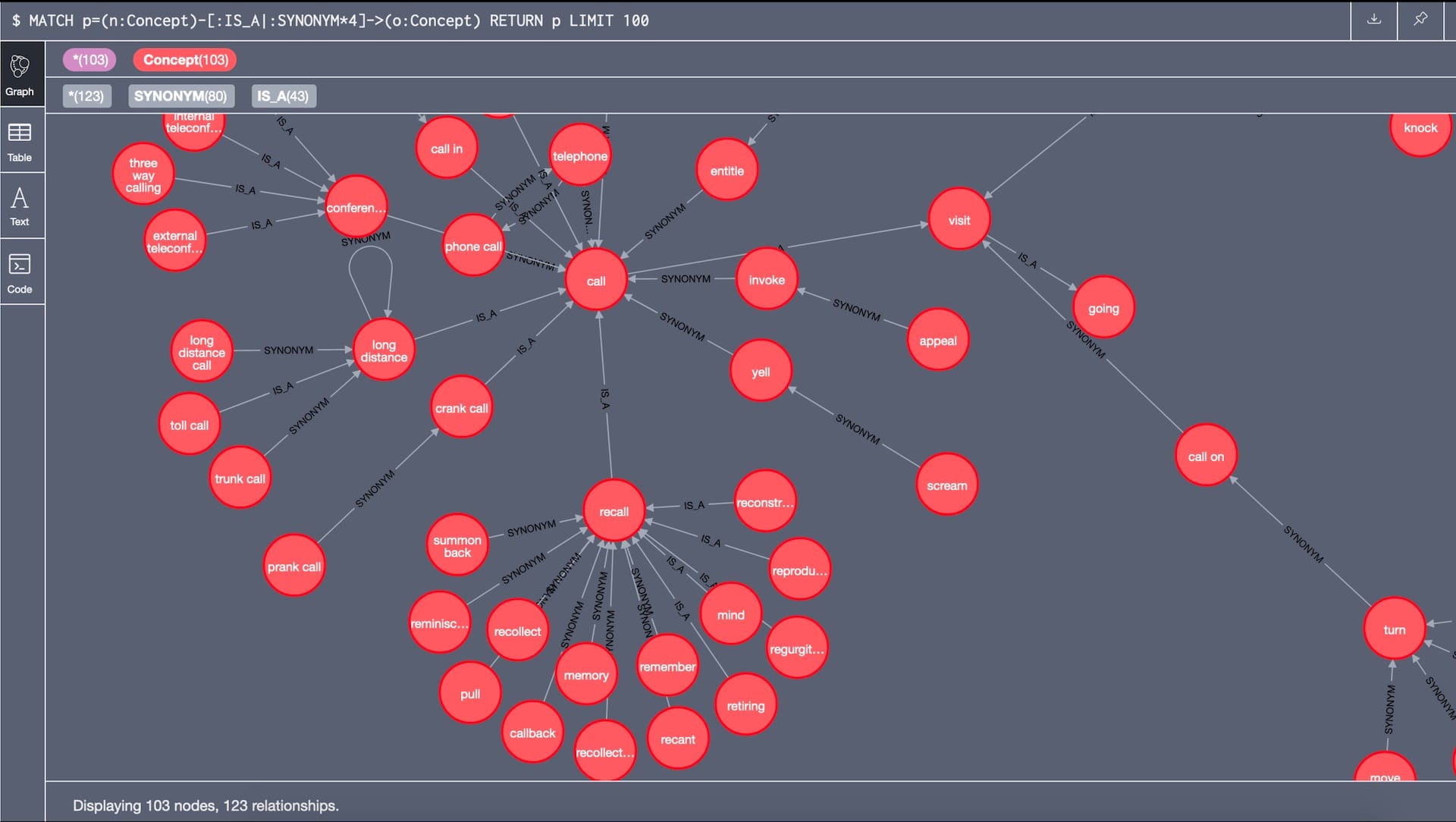
Well it looked something like this, where nodes had to have a special label representing which knowledge graph they belonged to. As you can see this makes the graph messy, unreadable. It’s not the nice clean graph people are used to from the demos.
Another case with single tenant application is where you have multiple graphs with different qualities. Yes, graphs are naturally multi-dimensional. If you model your data correctly and distinguish relationship types properly, you can store all sorts of different data sets in a single graph. But in some cases it is simply cleaner, safer, and more practical to separate the graphs completely.
Take for example a beautiful, curated, and clean ontology your team has worked so hard to build…
… and then the same machine-generated, thereby inherently somewhat messy, enriched data from the same domain or even the same data set. Quite possibly, you will want to separate those graphs, give different people different access, and use the insights that each of these graphs produces differently.
Finally, a third practical application of the multi-database feature, is auditing.
GraphAware has always offered an auditing module for Neo4j as part of our enterprise offering and what it looks like in the database is something like this:
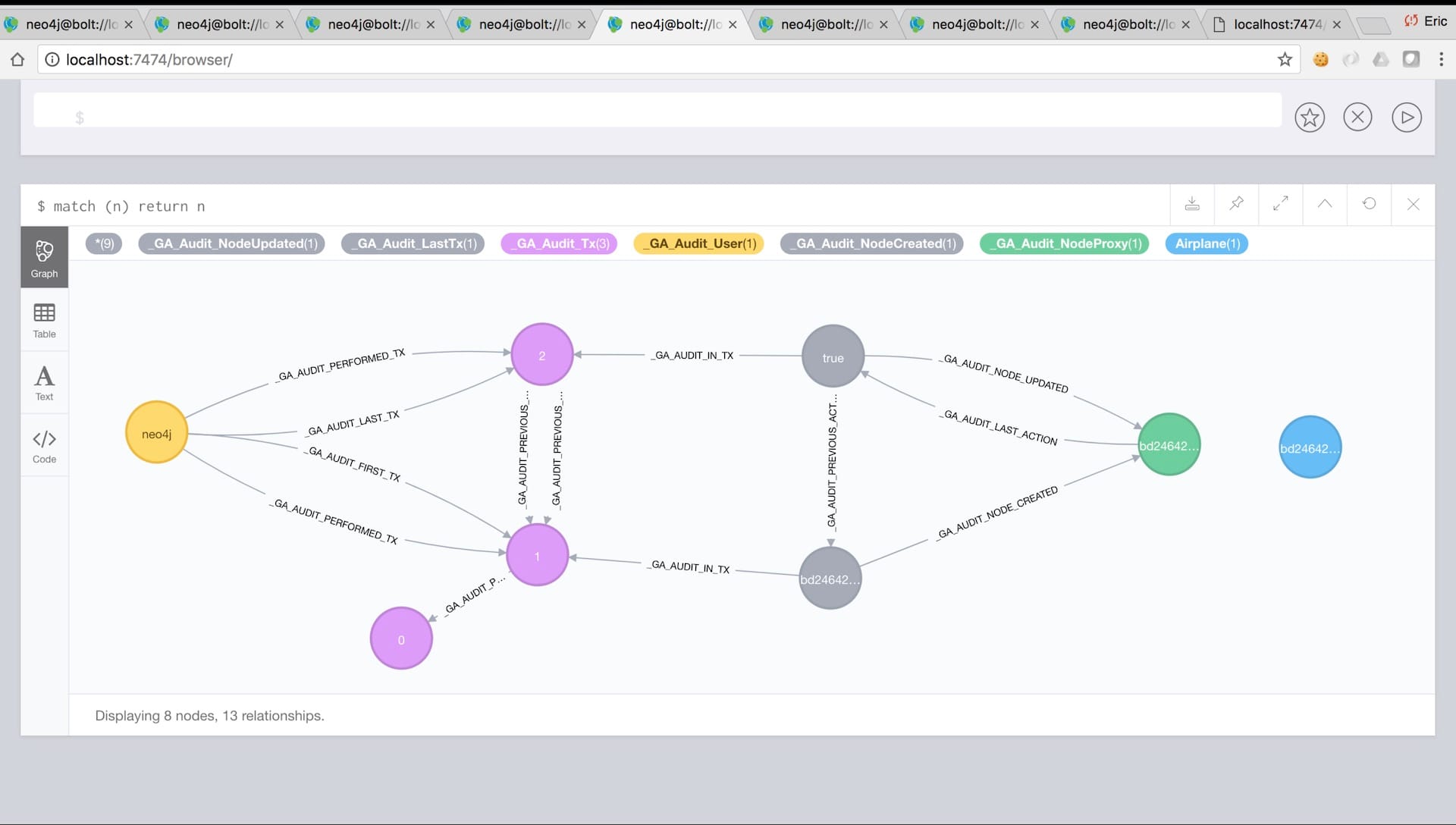
This is a very simple example. The blue node on the right is the only thing on the screen that’s actual business data. The node was created and then one of its properties was updated. Only two operations ever happened on this data. But what you see is that there are two fully disconnected graphs.
There is the blue node, and then there is a ton of other stuff which is the audit trail. There is the yellow user, the purple transactions, in grey the modifications in those transactions, and in green the proxy of the real node. But again it makes the actual graph messy. Yes you can easily write queries to avoid the audit graph altogether but it’s not pretty and error prone. With Neo4j 4.0 you can store these graphs in different separated databases.
Neo4j 4.0, with its multi-graph feature, makes all the three use cases we just mentioned and many more much easier. What’s more is that you can query the graphs at the same time if you need to by using Fabric, another addition to the Neo4j feature portfolio included in this release.
Increased scalability and graph-based machine learning
Finally, we’d like to write about another practical application of Neo4j 4.0 and probably 5 and 6 too, something a little more forward looking. That is the scalability Neo4j 4.0 offers.
For the last three or four years we’ve been relentlessly advocating that graphs will be the underpinning technology of good, modern, practical applications of machine learning.

“Graphs are the underpinning technology of all modern machine learning and AI applications. The results of machine learning are brought back into your central graph database – the brain for your organization.”
Alessandro Negro Chief Scientist, GraphAware
So much so that our Chief Scientist Alessandro Negro is writing a book about it. 8 chapters out of 11 are finished by the way and available in the early access program to download.

Graphs in ML is not a novel concept though. Take this book from 1997, Mitchell’s “Machine Learning” which was the first ML textbook used by our CEO when he was studying ML as part of his CS degree. There is a graph on the front page as well as on many pages inside the book. Graphs and ML are a natural fit.
More specifically, and let’s use a Hume image again to demonstrate this point, graphs are applicable in all phases of a typical machine learning pipeline.
First of all, they allow storing data from multiple, disconnected, oftentimes heterogenous and siloed data sources, in a single graph, single source of truth, thereby providing context to the machine learning tasks.
Secondly, machine learning itself can use theoretical graph algorithms, of which many are applicable. Take for example Random Walk, Shortest Path, Depth- and Breadth-first searching, Minimum Spanning Tree, Node2Vec which is already at the intersection of ML and graphs, but also the famous Page Rank which we use to extract keywords automatically from free text, and we found that despite the fact it is completely unsupervised, it is comparable with supervised algorithms in terms of speed but more importantly accuracy.
Another important aspect of graphs and ML is that one can extract features from the graph itself, such as connectedness, degree, betweenness and other centralities, etc. Take your standard ML features you extract from data, add the network features and you will get a richer feature set producing better predictions than one would normally have by inspecting the nodes or “objects” only.
If you are interested more in this topic, Amy Hodler and Mark Needham wrote a great book which is already out, called Graph Algorithms: Practical Examples in Apache Spark & Neo4j, and they have a great series of webinars and talks about this topic, including extracting features from graphs.
When our machine learning process or training is finished, we end up with a ML model. Many ML models are actually graphs themselves, so they can naturally be stored in a graph database. Take for instance Markov Chains, Decision Trees, Clusters, or kNN similarities.
Finally, delivering the insights using the results of our training process can often be easily achieved by querying the graph itself, more often than not in real time.
So these are all places where graphs fit the ML pipeline.
Now, as many readers will appreciate, machine learning can be very demanding on computational resources and this is why the increased scalability of Neo4j 4.0, with logical graph partitioning and so called Fabric, will even further enable and accelerate this graph-powered machine learning trend for the next years and decades. It is the space to watch in the coming couple of years.
Neo4j 4.0 at GraphAware
In this post we have seen how Neo4j 4.0 features can practically be applied to different domains and use cases, from Intelligence and Law Enforcement to Machine Learning Powered By Graphs.
At GraphAware we believe this Neo4j version is going to change many practices and enable more advanced use-cases. We started using it already, and you can find some interesting articles about it in our blog.
Moreover, our latest version on Hume, to be released by the end of this month, has full support for Neo4j 4.0. A completely new space called the Ecosystem was introduced to help administrators managing resources, including Neo4j 4.0 databases. This makes the whole task of securing knowledge graphs as easy as possible. This Hume release also includes another great new feature called Orchestra, a powerful intuitive way to visually manage the complex data workflows that are needed to create and maintain knowledge graphs.
If you are interested in what Hume can do for your use case, stay tuned or drop us an email. If you want to get the most out of the new Neo4j graph power, we are here to help you with the migration, and more than ever to unveil your graph potential. Get in touch and tell us about your use case.

