
The release of Neo4j 4.0 brought many improvements, one of them being a reactive architecture across the stack, from query execution to client drivers. But how does that compare to other approaches? As stated in the reactive manifesto, a reactive system is more scalable and responsive, with more efficient resource usage.
I was curious to see this in action and check the benefit. In this article, we will take a simple example of copying data from one database to another and compare the reactive approach to traditional ones regarding execution speed and resource usage.
We’ll use Java to copy data between 2 separate Neo4j instances; all the source code is available in this repository.
Getting started
First, we’ll just generate some random nodes into a source database and copy the data over to the second database with a simple single thread :

The source code for this can be found here. Note that for performance reasons, we batch the updates to avoid too much transactional overhead.
Having a look at the execution output, we can see that reads and writes alternate, and it takes about 70 seconds to copy the 1 000 000 nodes.
The video below shows the live progress of the copy, each ‘r’ and ‘W’ characters representing a read or write of a batch of data.
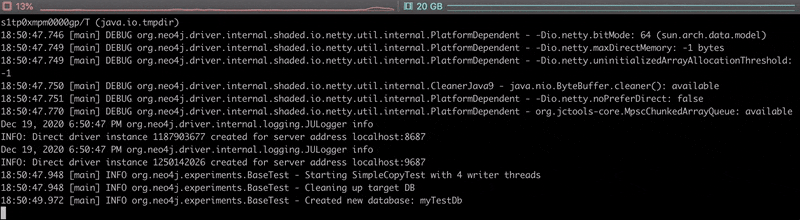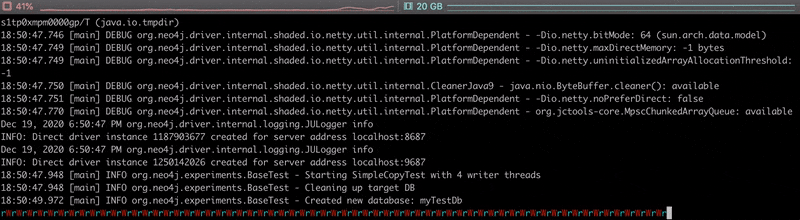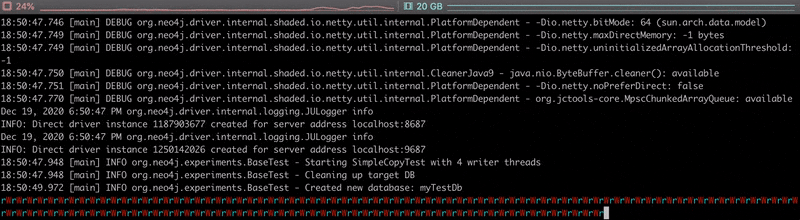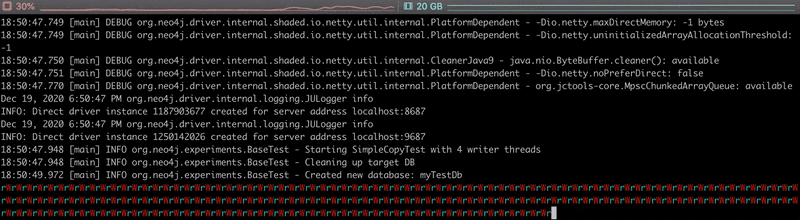
Nothing fancy here, as that’s not really optimised. This is just a teaser and definitely not something we would do in a real-life project. As reading in Neo4j is usually much faster than writing, we’d rather parallelise the writes. Let’s continue with this.
Going parallel
We can use, for example, a queue, acting as a data buffer between a reader thread and multiple writer threads, like this (source code here):

The data streams between our readers and writers, and the queue limits the number of in-flight nodes to avoid memory issues (remember, reading is usually much faster; we would quickly fill up the memory if we don’t limit incoming data).
Here is the output of the copy:
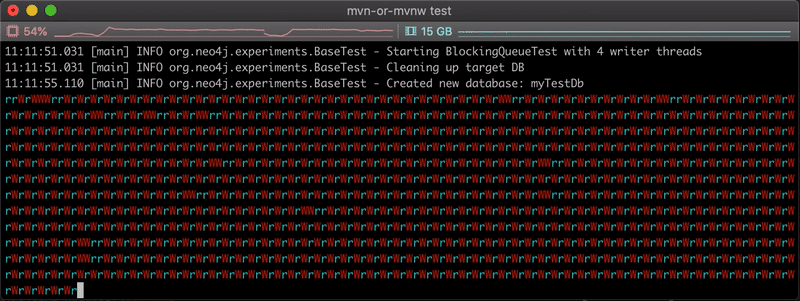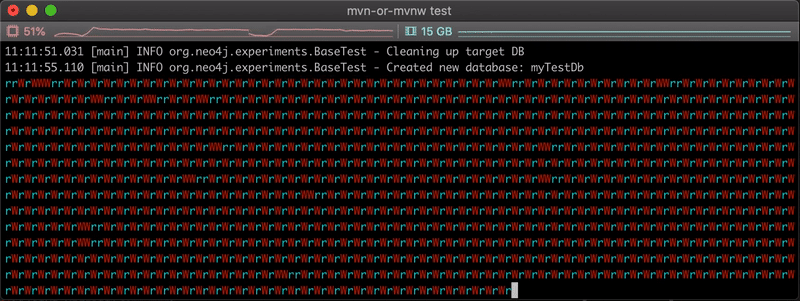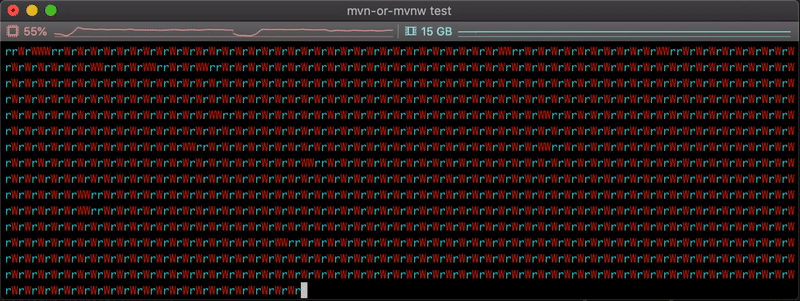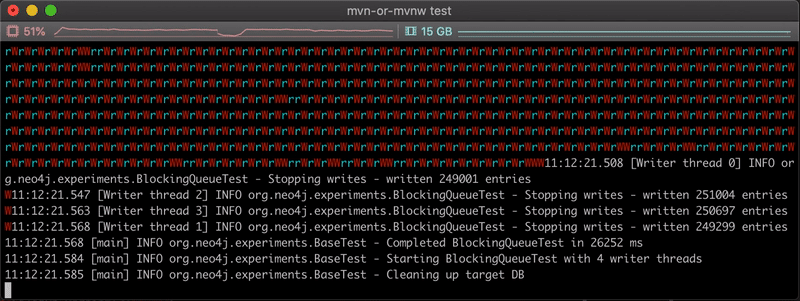
As expected, we can see that the time to copy the nodes is much faster in this case: ~ 28 seconds. We can see mostly alternative r/W combinations, indicating our reader thread is probably always waiting for some space to be free in the queue to fill it.
Reactive copy
Coming to our main subject of interest today, let’s see what a reactive copy looks like. This example uses Java and Project Reactor, a reactive library from VMWare based on the Reactive Streams specification. I picked this library as it is the one used by the Spring framework, which we use a lot in our projects. The copy code comes down to this :
void copyAllNodes() {
Integer createdCount = readNodes()
.buffer(BATCH_SIZE)
.doOnEach(it -> logBatchRead())
.flatMap(this::writeNodes, WRITER_CONCURRENCY)
.reduce(0, (count, result) -> count + result.counters().nodesCreated())
.block();
assertEquals(sourceNodesCount, createdCount);
}
private Flux readNodes() {
...
}
private Mono writeNodes(List parameters) {
...
}
This code gets a stream of nodes and buffers them into a list. The batches are sent and executed concurrently by the writers through the flatmap operator (it transparently pushes data to “sub-publishers”). Then the created node count is computed and compared to the count in the source database.
It is pretty compact compared to the previous blocking queue, as reactive is concurrency-agnostic and allows parallelisation in a declarative way without having to deal with thread pools.
When it gets executed, we can see that it completes in roughly the same time as the previous example but behaves differently:
Notice how the read/write pattern is quite different from the one in the multithreaded example. We see more variations in the I/O patterns, as each batch of data flows directly from the reader to the writer.
Which one is the most efficient?
But wait… a reactive implementation is supposed to have more efficient resource usage. How can we verify that? Let’s check by limiting the memory and running the same tests with different configurations (it’s not a front-end application after all 🙂 ).
Have a look at the memory configuration at the end of the pom.xml if you want to play a bit by yourself.
| Max heap size | Blocking queue exec. time | Reactive exec. time |
|---|---|---|
| 64 MB | ~ 28 seconds | ~ 28 seconds |
| 32 MB | ~ 33 seconds | ~ 30 seconds |
| 20 MB | ~ 44 seconds | ~ 38 seconds |
| 15 MB | Fails | ~ 66 seconds |
It looks like the performance is equivalent with enough memory, but when the memory gets scarce, the reactive code takes over. Even better, it allows to do the copy with as low as 15 MB of heap, whereas the queue approach is failing with an out of memory error (although it could probably be tuned a bit to be more performant).
What about back-pressure?
Now I can hear some of you think: the reactive way could also benefit the source database, no? If the writes cannot keep up with the reads, the back-pressure mechanism should bubble up that info to the source database. The source would then gracefully adapt and delay its work until it’s really needed.
Here’s what we get if we reduce the memory allocated to 96 MB on the source DB and monitor it while the tests are running:
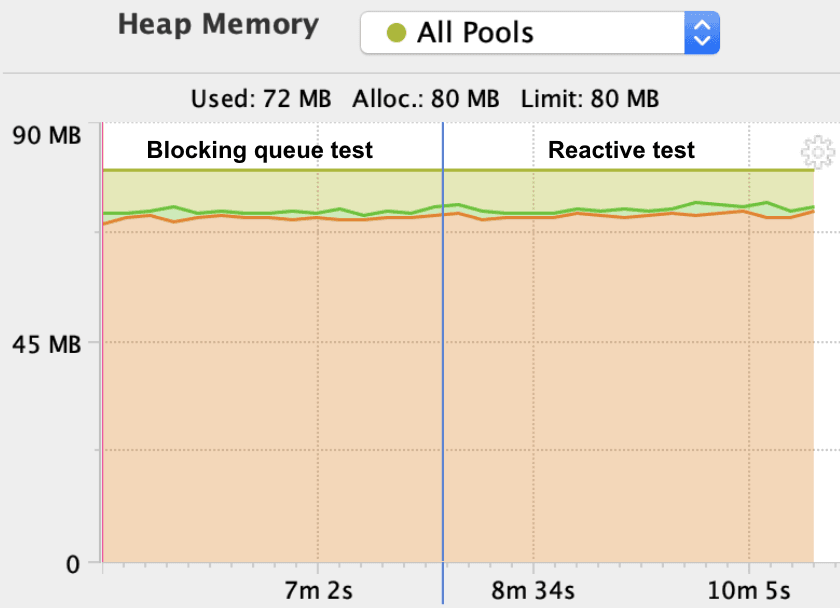
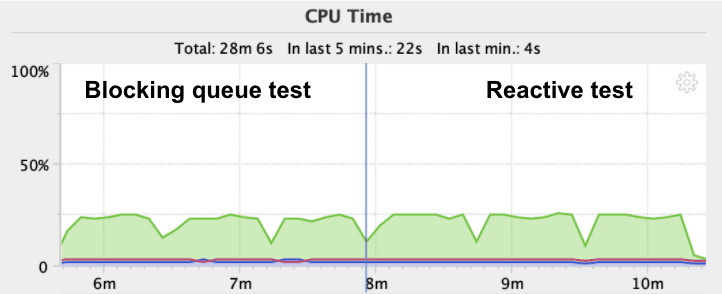
As you can see, there is not much difference between the two here. Memory usage, impact on garbage collection and CPU look similar, but it is hard to conclude as our example is probably too basic. Maybe we’ll investigate it in a later blog post.
Conclusion
Using reactive programming and Project Reactor in this simple data streaming use case provides better elasticity and resource usage. In some ways, it is more efficient than traditional blocking I/O.
Declarative concurrency is also a nice aspect. We end up with more compact code, as we don’t have to manage threads and synchronise them.
But keep in mind that it comes at a cost. Learning reactive programming is not so easy. There are plenty of operators, and it’s like learning a new language. Unless you have strong latency or concurrency constraints, think twice before jumping right on it for your next project, and make sure to consider future alternatives such as Project Loom.
Thanks to Michael Simons for the review and nice suggestions on this blog post.
Notes on the test setup:
As this is not intended to be a benchmark, the test setup used is basic, running on a local laptop, using Java 15 and 2 separate Neo4j 4.1.3 instances.
A Docker Compose file is provided with the source code for convenience, but as the tests were run on MacOS, I avoided Docker (because… well… notthatgreat in terms of performance)