

Unlocking the past: The Rockefeller Archive Center
The Rockefeller Archive Center (RAC) was established in 1974 to preserve the records of the Rockefeller family’s philanthropic work and to support research into how those efforts have shaped society in the United States and beyond.
Over the decades, the Archive Center has expanded significantly. Today, it houses the records of a growing number of philanthropic institutions, foundations, and civil society organisations, alongside the personal papers of individuals connected to their work.
Researchers from around the world use the RAC’s collections to explore subjects ranging from the history of medicine, science, and public health to the arts, agriculture, the social sciences, urban affairs, and public policy.
The challenge: finding meaning in 10,000+ unstructured documents
The RAC holds a vast collection of historical records documenting science funding and philanthropic decision-making. Within these materials lies rich detail about how ideas emerged, how relationships influenced outcomes, and how funding decisions were made.
The RAC team wanted to understand which decisions, interactions, and events had the greatest impact on grant outcomes. By analysing past grantmaking activity, the Center aimed to identify factors behind successful projects, trace paths to approvals, and uncover the individuals and organisations that played the most influential roles.
To do this, the RAC wanted to understand whether they could transform large volumes of unstructured historical documents into a format that could support systematic analysis. They focused on several key objectives:
- Demonstrating how diverse analogue historical records could be digitised and integrated into a single, searchable graph database.
- Using advanced machine learning pipelines to extract meaningful information from unstructured documents and represent it as a connected knowledge graph.
- Uncovering new insights into grantmaking by analysing intellectual networks and tracing the evolution of research fields over time.
- Enabling researchers from different disciplines to explore and interact with the archive using sophisticated analytical tools.
As a proof of concept, the RAC selected a focused but detailed subset of its archive: the Rockefeller Foundation’s board minute books and officer diaries from 1932 to 1941. Together, these records totalled around 12,000 pages of handwritten and typewritten material.
The minute books of the Foundation’s board of directors recorded the outcomes of the decisions, including who received grants, for what purpose, and in what amount. The officer diaries, by contrast, provided a much richer context. They recorded meetings, correspondence, and telephone conversations between Foundation officers and candidates, capturing what was discussed and the nature of the relationships involved.
While these documents contained a wealth of historical insight, their unstructured nature made it difficult to analyse relationships, patterns and trends over time. Extracting and connecting this information while preservingcontext, detail, and accuracy was the central challenge the RAC needed to address.
The Solution: building a curated knowledge graph from historical records
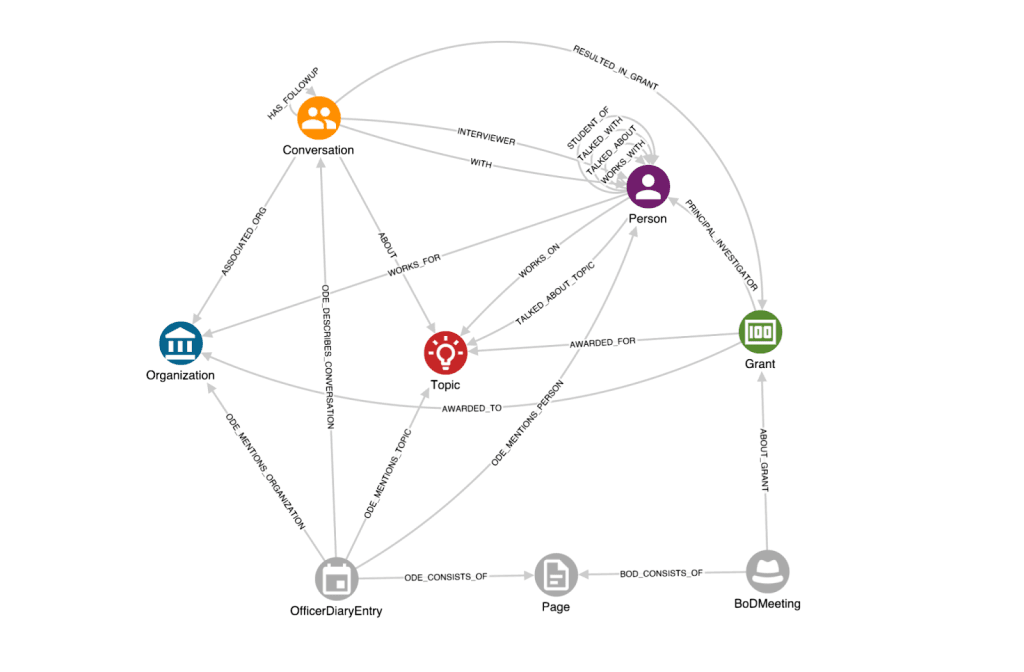
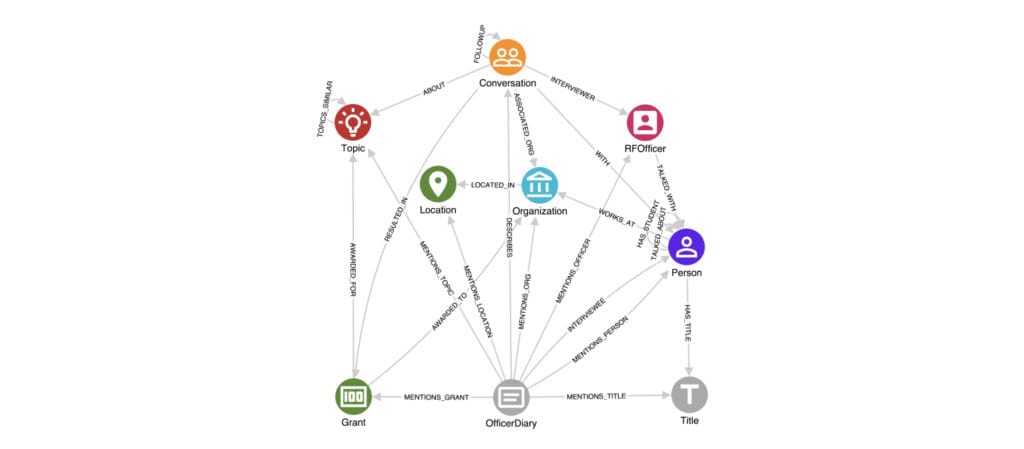
To meet this challenge, the RAC partnered with GraphAware to deploy GraphAware Hume, and build a curated knowledge graph connecting funding decisions with people, institutions, and historical context.
The resulting knowledge graph brought together information from board meeting minutes, officer diaries, and grant records. This allowed the team to trace how funding flowed, how ideas evolved, and which institutions and individuals held influence over scientific advancements at scale – something that had not been feasible using traditional approaches.
The knowledge graph allowed the RAC to track funding to institutions and individual researchers, while also highlighting smaller, often overlooked grants, such as those for equipment purchases. Together, these connections provided a more nuanced understanding of how support was distributed and where it ultimately had the greatest impact.
GraphAware supported the project by designing a schema tailored to RAC’s research objectives and deploying the solution through a structured process, which included:
- Digitising historical records using optical character recognition (OCR) to convert handwritten and typewritten documents into machine-readable text.
- Preserving contextual structure through customised document chunking, ensuring individual diary entries and meeting records could be analysed while retaining their original meaning.
- Extracting entities and relationships using named entity recognition, relation extraction, and entity resolution to identify people, organisations, grants, and their interconnections across documents.
- Structuring knowledge as a graph to explicitly model complex relationships, such as influence, collaboration, and funding decisions.
- Applying graph analytics and temporal analysis to explore intellectual networks, identify influential actors, and track the evolution of research disciplines over time.
- Enabling intuitive interaction through Hume Actions, allowing researchers to ask domain-specific questions of the graph without needing to write Cypher queries.
A key enabler of this approach was Hume Orchestra, GraphAware Hume’s data workflow engine.
Orchestra enabled the ingestion, transformation, and manipulation of large volumes of unstructured data by integrating tools like OCR, natural language processing, and large language models into a cohesive pipeline. These workflows ensured extracted knowledge could be resolved and added to the knowledge graph with node and relationship context intact.
Curious to see how advanced analytics & LLMs can extract knowledge from unstructured data?
Explore the LLM technology we used to build this comprehensive knowledge graph.
After evaluating several alternatives, the RAC selected GraphAware Hume due to its graph-powered approach and ability to combine advanced analytics in an intuitive and highly customisable platform. This made it possible to build a knowledge graph from thousands of unstructured documents at scale, while remaining accessible to researchers without specialist technical expertise.

The results: revealing influence, patterns, and hidden histories
The RAC deployed GraphAware Hume as a proof of concept to evaluate the insights that could be extracted from existing archival materials, and how those insights could support research into historical grantmaking and scientific influence.
The project and the resulting curated knowledge graph demonstrated that large volumes of unstructured historical records could be transformed into a connected, analytical asset. Researchers were able to move beyond individual documents to explore how ideas, relationships, and decisions interacted over time.
Using the knowledge graph, RAC identified “super-influencers” – individuals with significant impact on shaping research directions and grant outcomes. Figures such as Niels Bohr emerged as highly influential nodes within the network.
The graph also enabled researchers to trace the evolution of grantmaking over time, revealing emerging scientific topics, shifts in funding focus, and patterns in how research fields developed.
A key outcome of the project was the ability for researchers to ask targeted questions directly of the data, without the need for manual examination of thousands of pages. Researchers explored questions such as:
- Are there identifiable patterns in the volume of meetings and interactions that typically precede a funding decision?
- What factors most consistently contribute to an idea’s success?
- Do successful projects tend to involve previously funded Rockefeller grantees, compared to new grantees?
- How much time was spent on ideas and relationships that did not succeed, compared to those that did?
- Is it possible to detect the early signals of an important idea taking shape?
The RAC team stated that the success of the project would not have been possible without the support and guidance of GraphAware’s Data Science Team.
GraphAware Hume has generated significant interest within the RAC and beyond, highlighting the potential for knowledge graphs to transform how information held in archive collections is analysed, interpreted, and made accessible.
The ability to query complex historical knowledge was recognised as a significant advancement, offering more researchers access to the insights contained in the archive.
Looking ahead, the work also suggested the possibility of deploying a graph-based retrieval-augmented generation (GraphRAG) approach to support the delivery of accurate answers alongside direct references to source documents.
GraphAware is not just a vendor, we gained an intellectual partner
— Director of Research & Education RAC