
The two-phase approach, described in the previous article, provides the conceptual foundation. Implementing this system requires precise technical decisions about criminal network analysis algorithms, data processing methods, and analytical frameworks.
Building on the first blog in the series, this second part explores the technical details of phase 1: knowledge graph-powered criminal analysis. It provides useful information to practitioners who want to approach criminal network investigation using graph data science techniques. If the first article described the vision and the results, this article describes how we achieved the network analysis foundation to make it reproducible.
What you’ll find here: criminal network analysis algorithms and more
We cover the specific technical choices that determine criminal network analysis performance. We detail why Louvain and Label Propagation algorithms work best for identifying criminal groups from co-offending data, and how PageRank and Betweenness Centrality reveal different types of key players within those groups. We explain the process of transforming raw crime and arrest data into meaningful network structures, and the graph analytics that extract actionable intelligence about criminal organisations.
We also cover critical implementation decisions: how to construct co-offending networks from bi-partite crime-offender relationships, why certain centrality measures outperform others for identifying criminal leaders, and how to validate network analysis results against ground truth data.
The technical decisions covered here directly impact the quality of network intelligence your system will produce. Understanding these choices helps ensure your implementation generates accurate criminal network analysis rather than misleading relationship maps. This foundation enables the AI-powered report generation covered in the next article.
Phase 1: KG-powered criminal analysis
Creating the co-offending network
Our analysis focuses on a specific subset of the knowledge graph: crimes and offenders. The Chicago dataset provides this information by combining arrest records with crime incident data, giving us sufficient detail to construct co-offending networks that form the foundation of our analysis.
The co-offending network is a standard approach in criminal network analysis that enables social network analysis techniques on criminal relationships. This network type provides critical information for risk assessment and organised crime investigations. We create it by projecting crimes over offenders—transforming a bi-partite network of crimes and offenders into a mono-partite network containing only offenders, where two individuals are connected if they committed crimes together.
Calculating relationship strength
The weight assigned to relationships between offenders represents one of the most critical decisions in constructing meaningful co-offending networks. Simple co-occurrence counting—merely recording that two offenders committed crimes together—fails to distinguish between meaningful criminal partnerships and coincidental associations. Without proper normalisation, highly active offenders appear strongly connected to everyone, while the true collaborative relationships become obscured by statistical noise.
The challenge mirrors problems encountered in other domains where co-occurrence analysis is essential. In academic research, for example, prolific authors who publish hundreds of papers will naturally co-author with many colleagues, but this doesn’t necessarily indicate strong research collaboration. The same principle applies to criminal networks: prolific offenders who commit many crimes will inevitably appear in incidents with various associates, but only some of these represent genuine operational partnerships.
Association strength: from academic collaboration to criminal partnership
We address this challenge using the association strength measure, originally developed for analysing co-authorship patterns in scientific publications. This measure is “proportional to the ratio between on the one hand the observed number of co-occurrences of objects i and j and on the other hand the expected number of co-occurrences of objects i and j under the assumption that occurrences of i and j are statistically independent” (van Eck & Waltman, 2009).
The formula naturally transfers from academic to criminal contexts because both domains involve analysing collaborative relationships within larger populations. Just as researchers choose specific collaborators from the broader academic community, criminals select particular partners from their available criminal networks. The association strength formula captures this selectivity by measuring how much more frequently two individuals collaborate than would be expected by chance.
The association strength between offenders i and j is calculated as:

Where:
- Cij: Number of crimes committed together by offenders i and j
- Si: Total number of crimes committed by offender i
- Sj: Total number of crimes committed by offender j
This normalisation reveals the true strength of criminal partnerships by controlling for individual activity levels. If an offender committed 3 total crimes, all with the same partner, that relationship yields an association strength of 1/3 ≈ 0.33. In contrast, if two prolific offenders each committed 100 crimes but only 3 together, their association strength would be 3/(100×100) = 0.00003—revealing that despite multiple joint crimes, this represents a weak partnership relative to their overall criminal activity.
Identifying meaningful criminal partnerships
This weighting scheme enables the network to distinguish between different types of criminal relationships: strong partnerships indicate offenders who specifically choose to work together, while weak associations suggest coincidental or opportunistic collaborations. High association strength values identify criminal partnerships that warrant investigative attention, as they represent deliberate operational choices rather than statistical artefacts of high criminal activity.
The measure’s effectiveness in academic collaboration analysis—where it successfully identifies research partnerships from massive publication databases—demonstrates its suitability for criminal network analysis, where similar principles of selective collaboration apply within criminal ecosystems.
Community detection algorithms
After constructing the co-offending network, we apply community detection algorithms like Louvain or Label Propagation to identify criminal groups. Louvain typically delivers superior results for finding cohesive communities where members connect more frequently with each other than with outsiders, and it processes large networks efficiently. Label Propagation proves more useful when we have prior knowledge about existing criminal associations—for example, known gang affiliations or criminal family structures that can serve as initial community seeds.
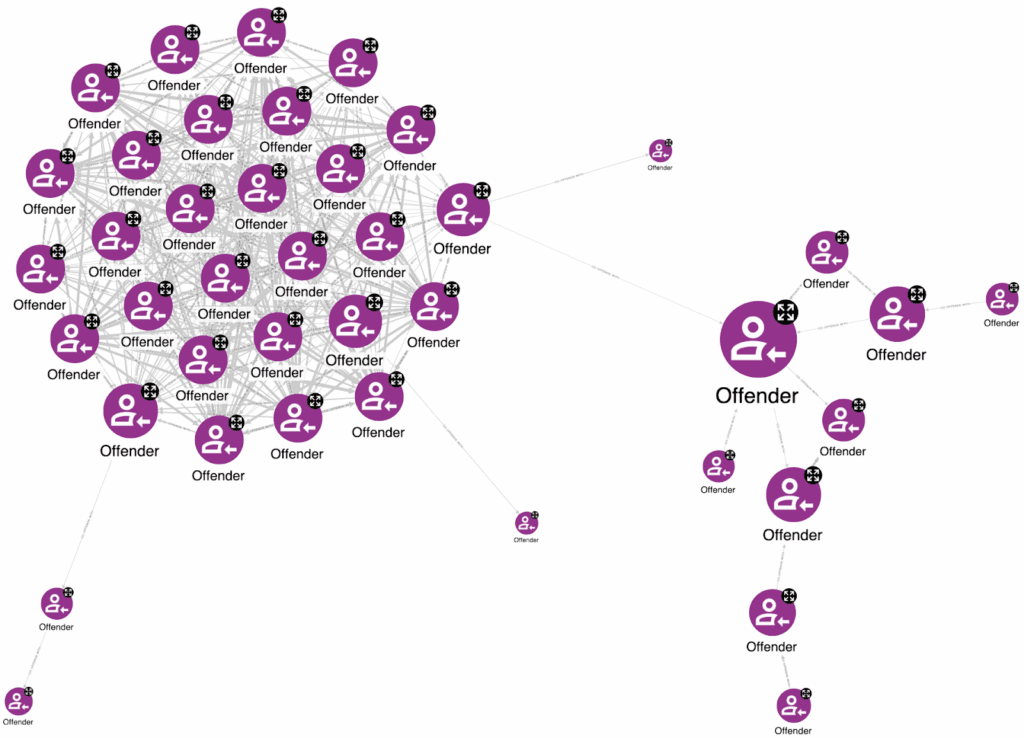
Identifying key players within groups
Once we extract communities, we analyse each as an isolated subgraph to reveal individual roles within the criminal organisation. PageRank identifies influential members who maintain strong connections with other important figures in the network—typically revealing operational leaders or coordinators. Betweenness centrality highlights individuals who bridge otherwise disconnected subgroups, often indicating brokers, messengers, or members who facilitate coordination between different operational cells.
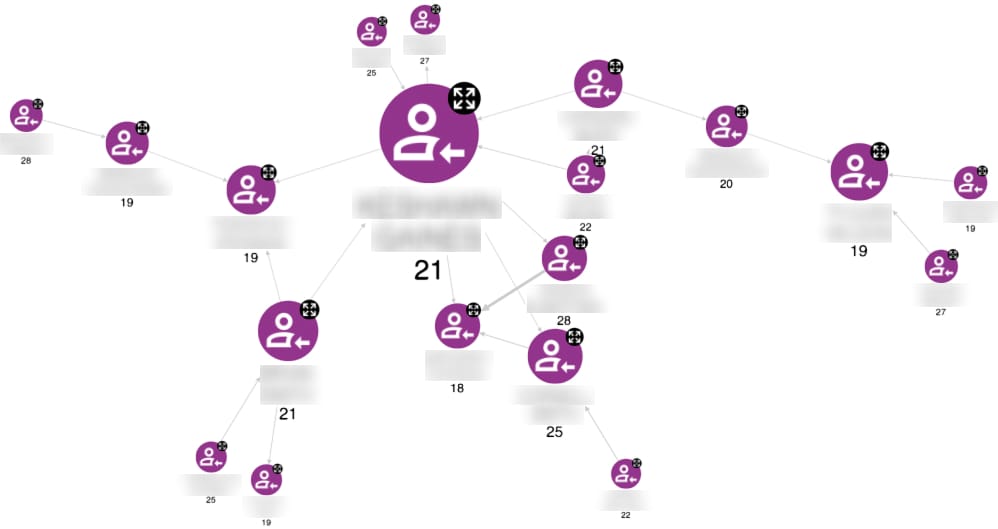
Information extraction for LLM processing
Additional network analysis techniques exist, but these algorithms already provide substantial intelligence about group structure and member roles. The final step extracts comprehensive information about each identified group from the broader knowledge graph—crime details, member demographics, temporal patterns, and other relevant data. By restricting analysis to specific, manageable groups rather than the entire dataset, we create focused data packages that LLMs can effectively process. This approach ensures that language models receive concentrated, relevant information about particular criminal organisations rather than being overwhelmed by the complete dataset, which would dilute their analytical focus and exceed practical token limits.
[
{
"Information": "Group Identification",
"Value": 410772,
"Attribute Description": "It contains the identifier of the group of cooffenders"
},
{
"Information": "Offenders in the group",
"Value": 36,
"Attribute Description": "It contains how many people belongs to the group of cooffenders"
},
{
"Information": "Crime Type",
"Value": ["NARCOTICS", "OTHER OFFENSE", "BATTERY", "CRIMINAL TRESPASS"],
"Attribute Description": "It contains a list of top 5 principal types of crimes committed by the members of the group"
},
{
"Information": "Offenders information",
"Value": [
{
"full_name": "*** *** ***",
"race": "***",
"sex": "MALE",
"betweenness": 134.0,
"id": "***_***_***_25_MALE",
"pagerank": 1.39,
"age": 25
},
{
"full_name": "*** *** ***",
"race": "***",
"sex": "MALE",
"betweenness": 68.0,
"id": "***_***_***_26_MALE",
"pagerank": 1.24,
"age": 26
}
],
"Attribute Description": "It contains all the information regarding the offenders including pagerank and betweenness"
},
{
"Information": "Crimes Information",
"Value": [
{
"date": "10/02/2014 06:23:00 PM",
"description": "POSS: CANNABIS 30GMS OR LESS",
"location": {"lat": -87.72, "long": 41.86},
"offenders": ["***_***_***_25_MALE", "***_***_***_25_MALE"],
"type": "NARCOTICS"
}
],
"Attribute Description": "This json contains crime information committed by group members"
}
]This systematic approach transforms raw criminal records into structured intelligence about organised criminal groups, their internal hierarchies, and operational patterns, providing the foundation for AI-powered analysis in Phase 2.
Combining knowledge graphs and LLMs can speed up criminal network analysis series
This article is part of a series exploring how combining knowledge graphs and LLMs can speed up criminal network analysis:
- Article 1: Extracting meaningful relationships from raw data through knowledge graph construction
- Article 2: Applying graph data science algorithms to reveal criminal group structures and hierarchies
- Article 3: Deploying specialised AI agents to synthesise network insights into professional intelligence products
- Article 4: Lessons learned and next steps for advancing this approach
Knowledge Graphs and LLMs in Action
If you would like to read more about techniques that combine knowledge graphs and LLMs, read our book from Manning.
Book Preview
To know more about GraphAware Hume, the graph-powered intelligence platform we used for our study, visit our product pages.
