
We are proud to announce the release of Hume version 2.23.
GraphAware Hume is an intelligence analysis solution. It represents your world as a network of interconnected entities, builds a single view of your siloed intelligence holdings, and brings powerful, user-friendly, machine-assisted link analysis capabilities to end users.
Improved usability of Advanced Expand
Advanced Expands let any user create complex queries without writing a single line of code.
Hume 2.23 introduces new features that greatly simplify the user experience when writing queries, by surfacing more information about the underlying data and schema.
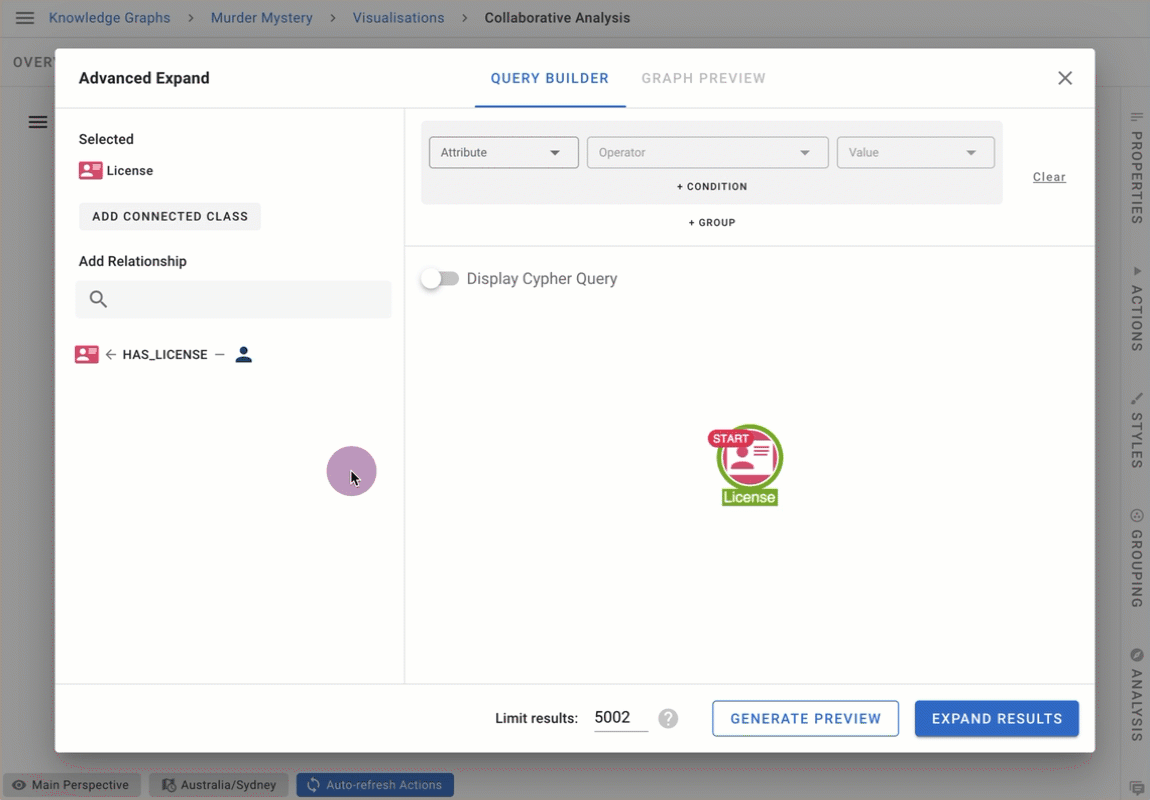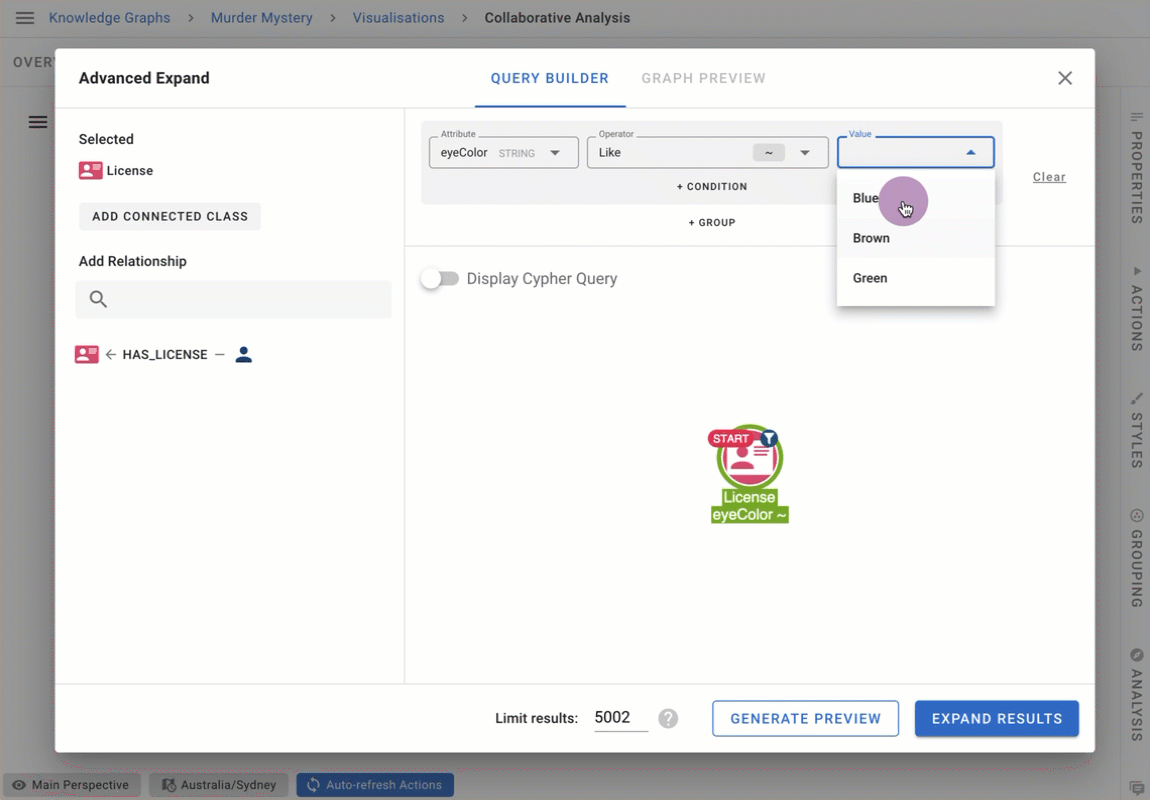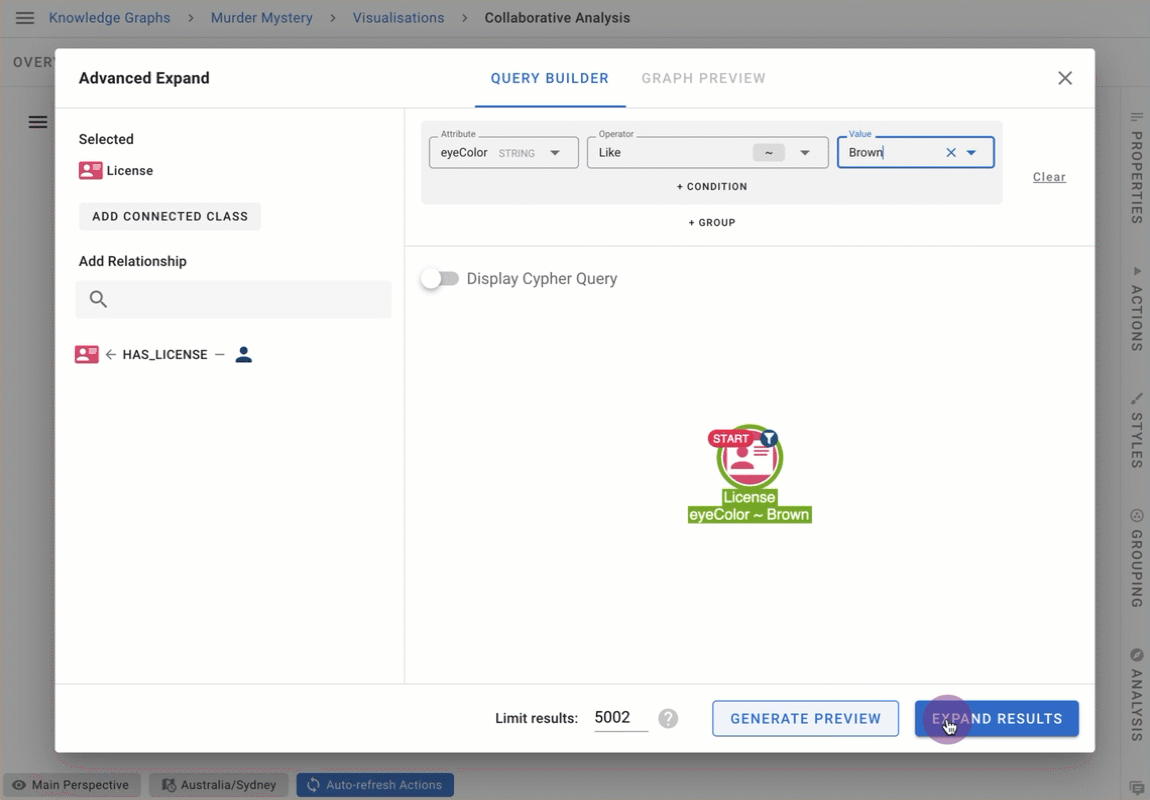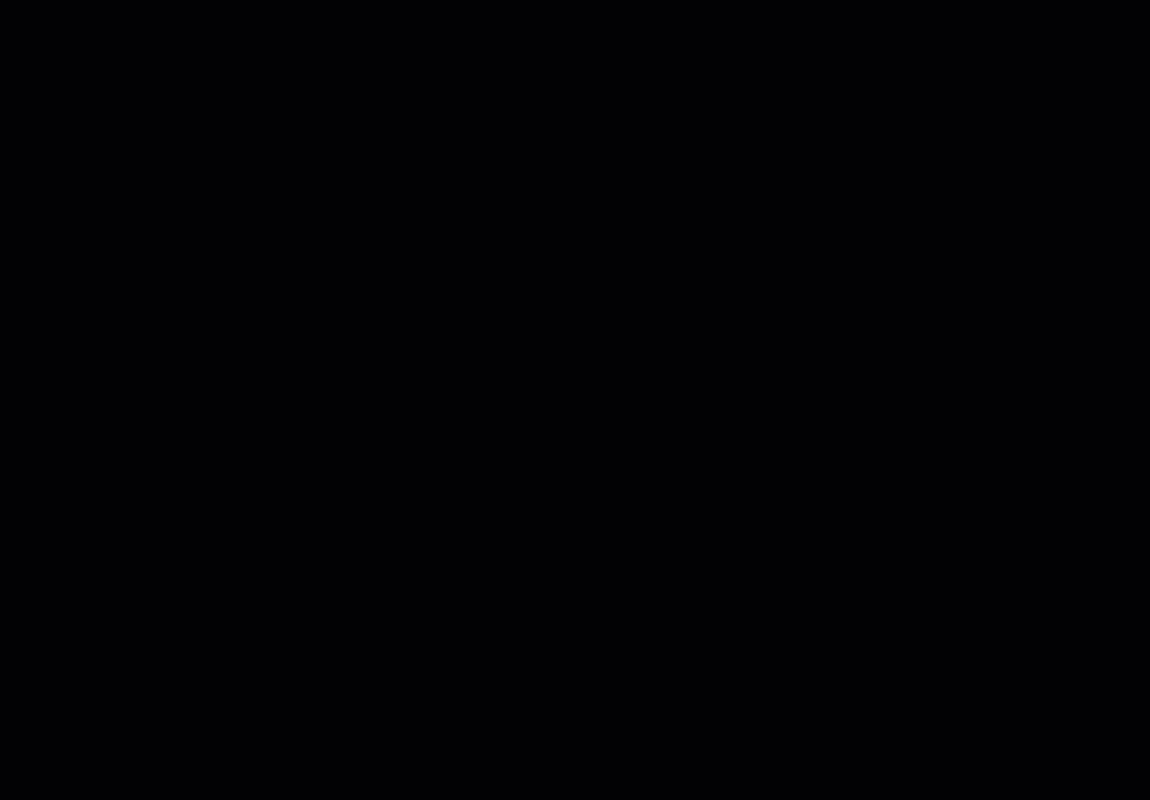
Value lists for categorical attribute suggestion in Advanced Expand
This release introduces value lists for Advanced Expand filter queries. When configured, value lists allow users to choose possible values from a dropdown menu, and allows them to see value suggestions as they type.
Value lists remove the need to remember the exact data format in the database when searching, and are best suited for attributes with a low frequency of change (e.g. eye colour, country, car brands, etc).
Descriptions for schema items and attributes
Schema descriptions help end users make sense of their data. Managers can now add descriptions for schema items and attributes which are customised for their data. Descriptions have numerous use cases, such as adding information on specific value formats (e.g. the format of phone numbers for a Phone Number attribute) or describing the meanings of node classes and attributes.
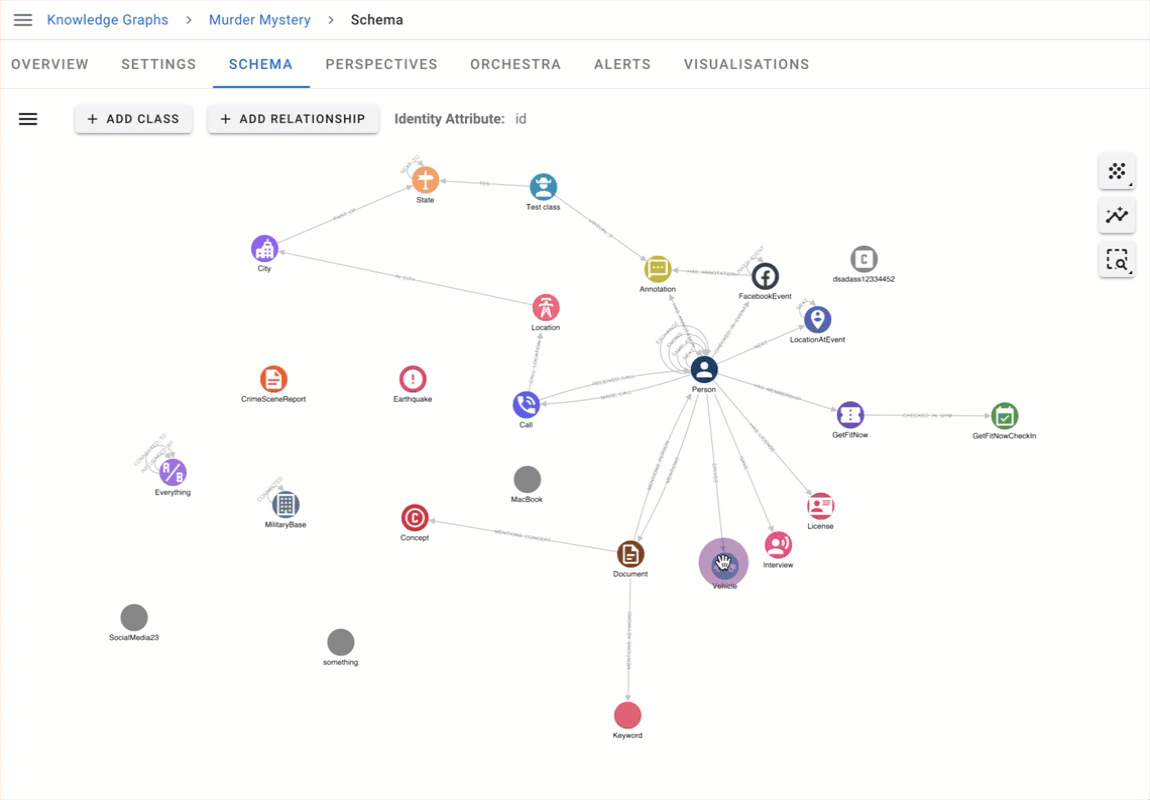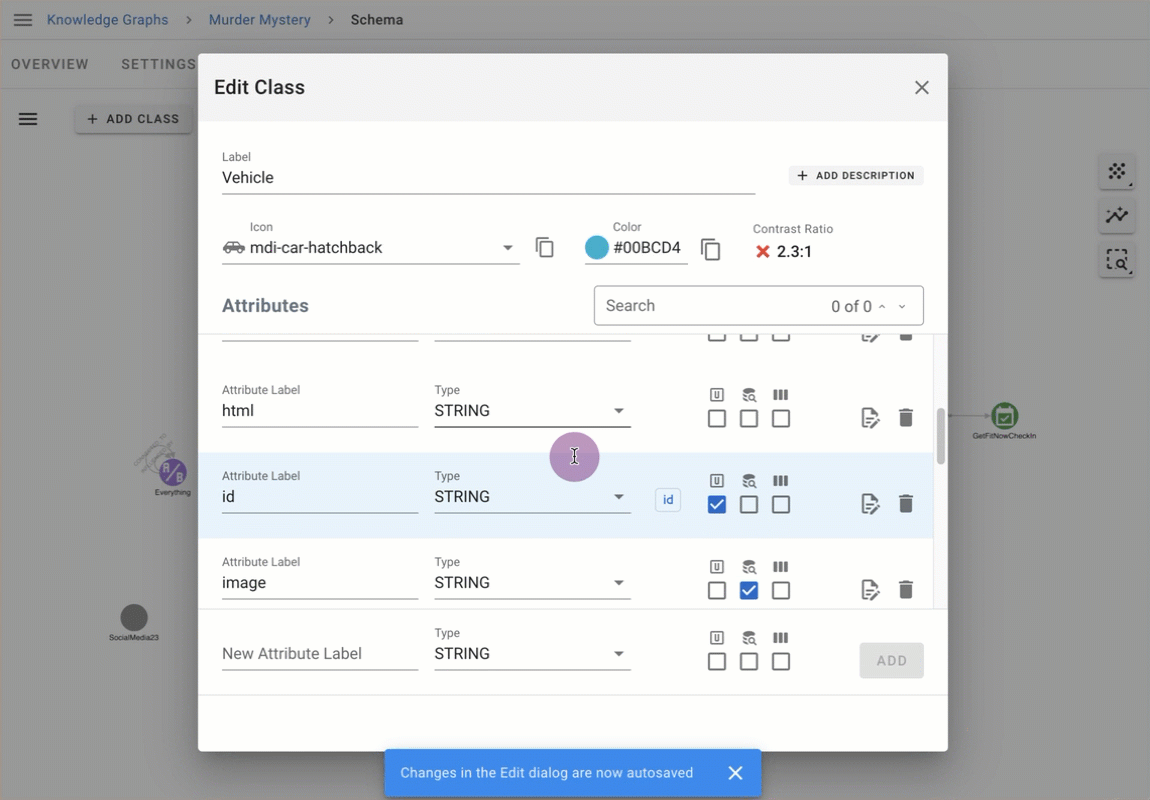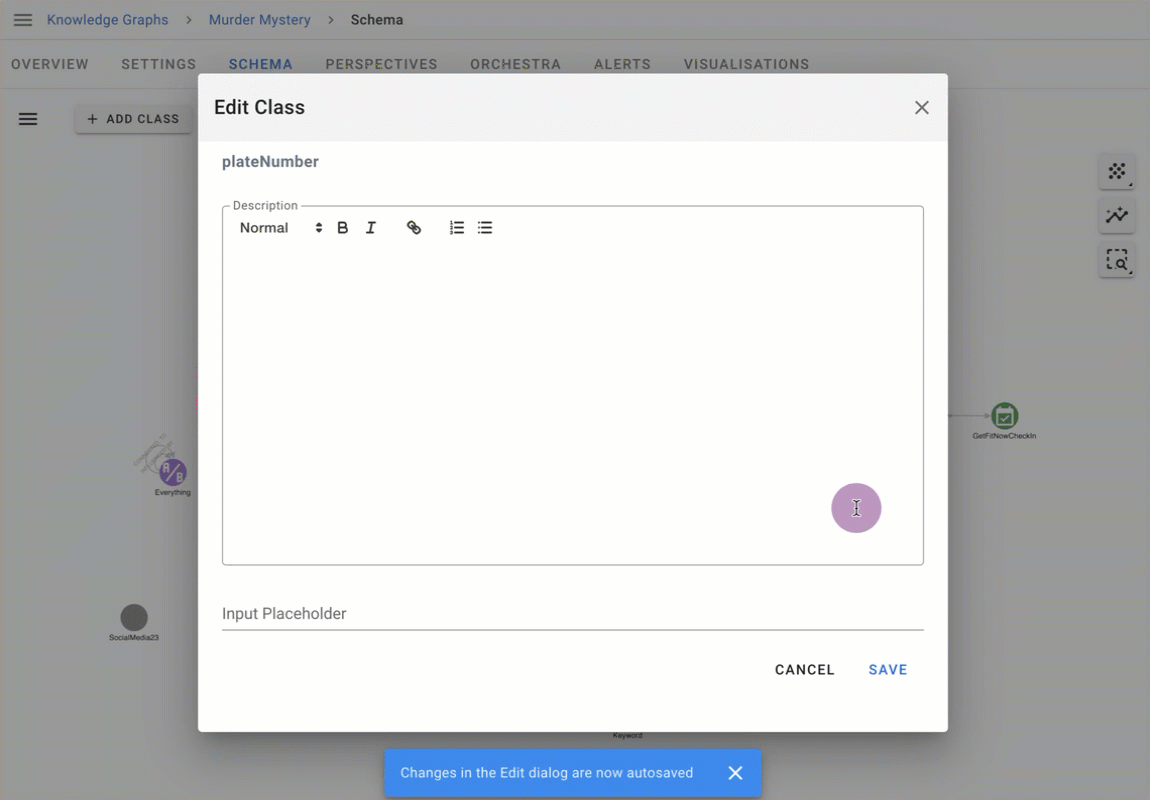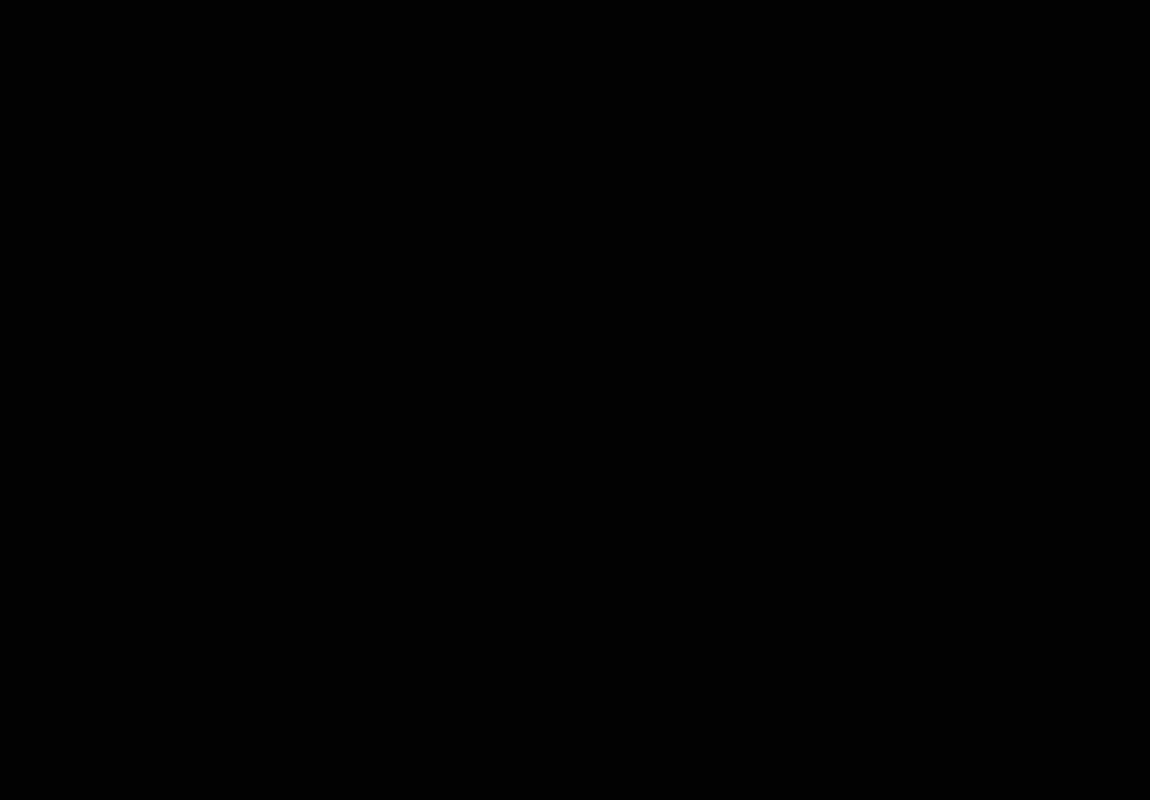
Descriptions are available to end users where needed, including the Properties panel, Advanced Expand, and Graph Editing.
Other core improvements
- Advanced Expand query generation now takes advantage of the property type constraints introduced in Neo4j 5. This allows Hume to automatically generate the best query for performance if a date or date time constraint is present.
- Custom group captions allow users to manually rename any group node in their visualisation to capture specific meanings that help their investigations.
- Link arrows are very important because they indicate the directionality of relationships. They are now always visible even when they overlap with node labels.
- HTTP API actions can now propagate the Keycloak token of the logged in user in any Header, allowing to seamlessly authenticate the user into external systems.
- The visualisation name of temporary visualisations generated via URLs can now be customised using a URL parameter.
Improved dev experience with Orchestra Workflows
2.23 introduced many features and improvements for data engineers to simplify and boost their experience when developing complex data workflows in Orchestra.
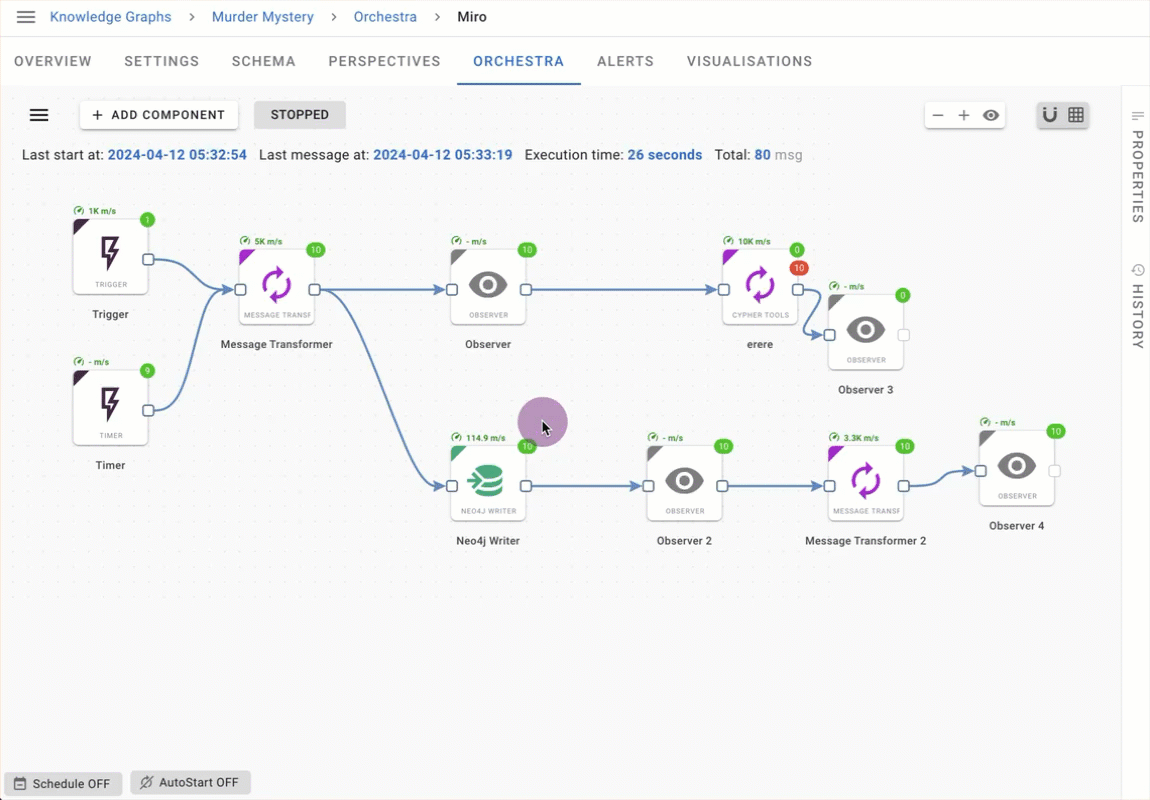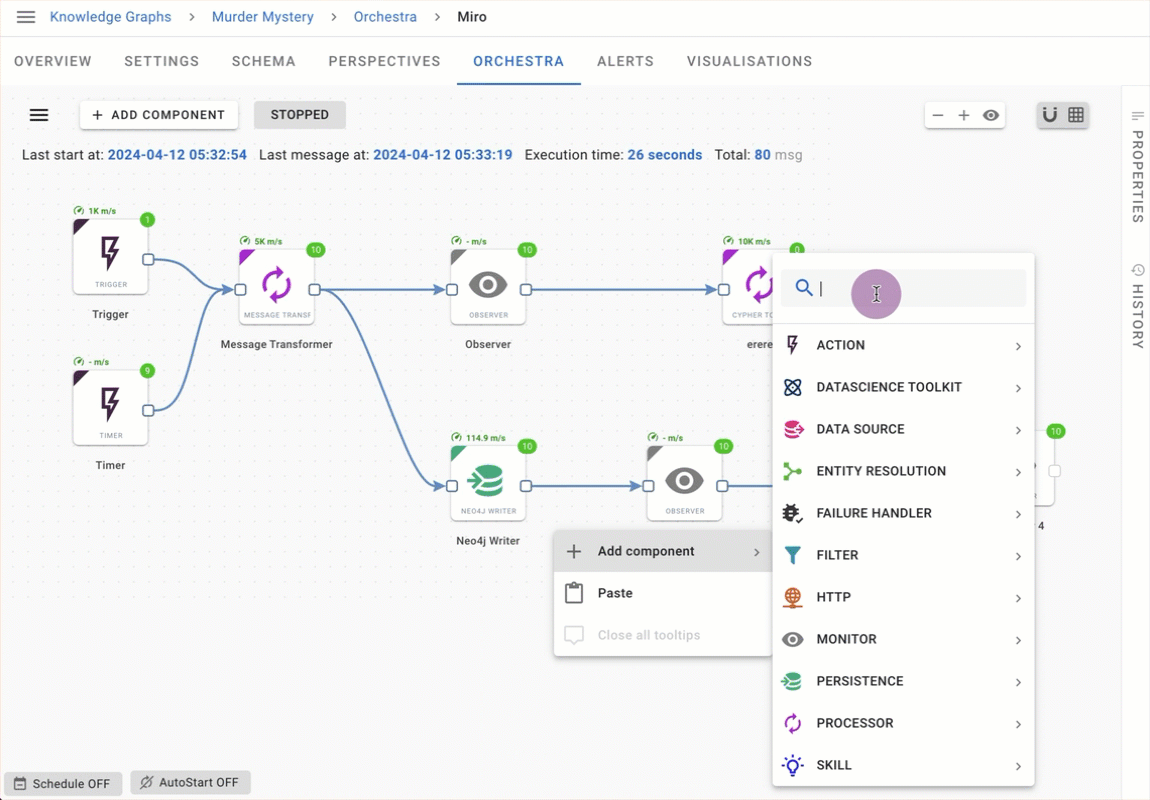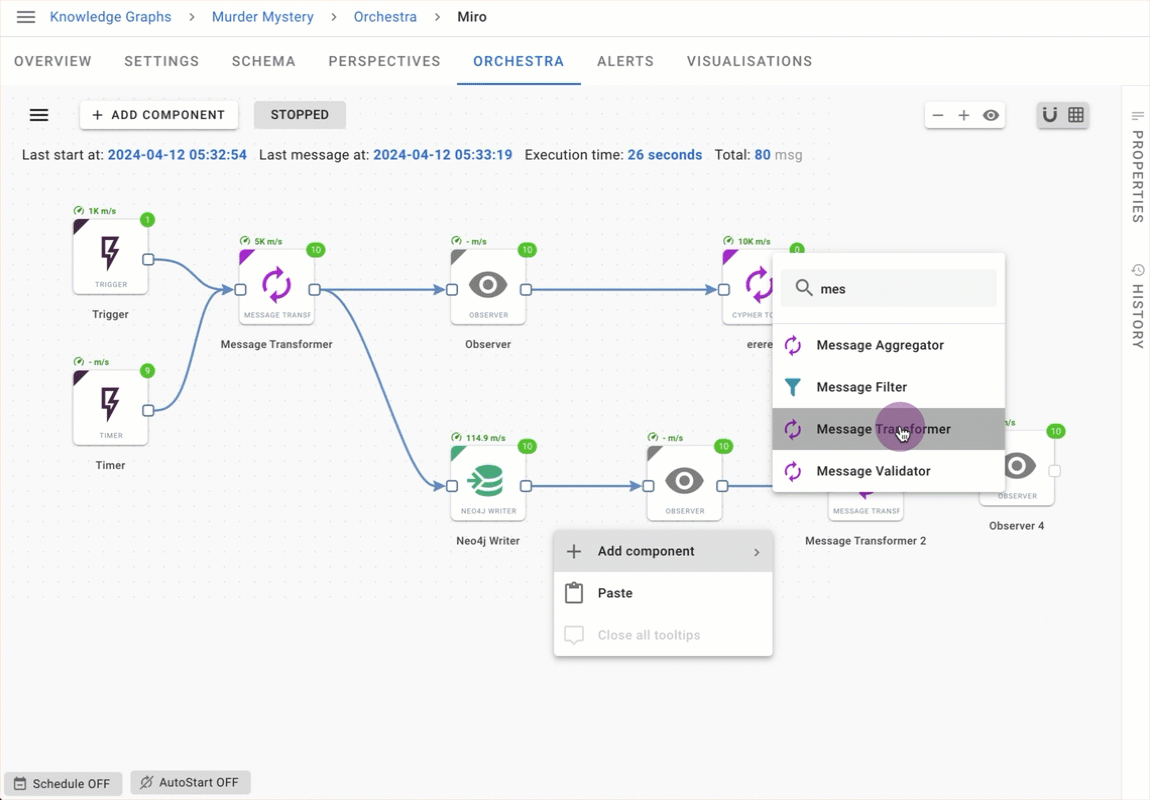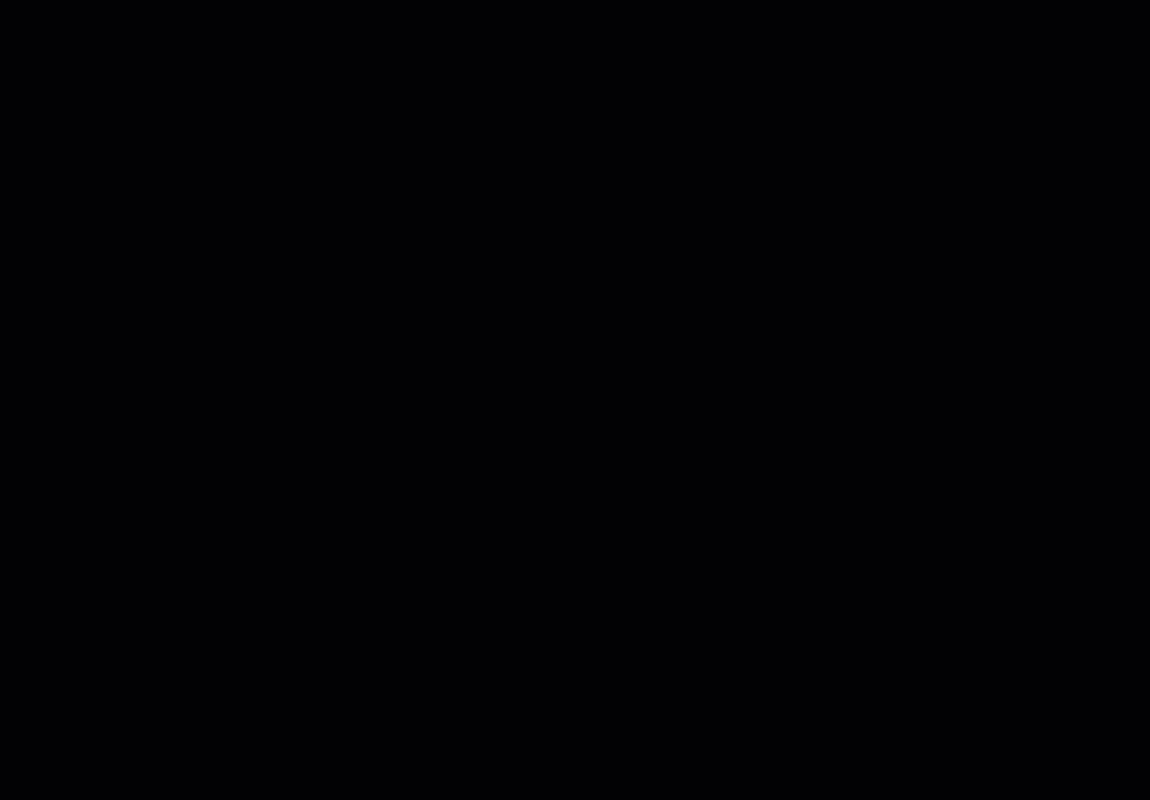
Workflow component search
Finding the Orchestra component that you need is easier than ever with the new context menu component search. As you type the name of the component, the filter displays components matching your search results.
Filter message content with JSONPath
2.23 introduces the ability to filter message content in Orchestra workflows. Now, you can inspect the contents of a message with the JSONPath query language. As messages can contain large arrays or nested objects, the message filter allows you to easily find particular fields and their values. Furthermore, it is possible to filter across all visible messages. This ability speeds up both development and debugging time.
New load balancer component
A new LoadBalancer component in Orchestra allows the automatic distribution of messages across multiple branches to simplify parallel computation scenarios. Supported methods include ROUND_ROBIN, RANDOM, and STICKY.
Other Orchestra improvements
- Neo4j Writer components can now combine the streamed output of the Cypher query with the original incoming message to facilitate and optimise chained processing downstream.
- Developers can now clear all unnamed versions of a workflow at once. This is not only very convenient, but also practical to clean up workflow history of any security information left during development.
- Developers can now freely engage in claim-check patterns for event-based architectures with Azure and AWS, by passing a reference inside lean Orchestra messages and retrieve big payloads from storage only when needed (supports Azure Blob Storage or AWS S3).
- When Message Transformer and Message Filter components are added to a workflow, they now have a default “pass through” Python body, so that they’re immediately usable. Users can now just run the workflow to let messages populate in the newly added components, and bootstrap their actual Python development.
- Some metadata including the knowledge graph and workflow name and id, and the workflow execution id, are now automatically available inside the workflow context to simplify access.
- Developers can now open a workflow in a new tab or copy the workflow id directly from the workflow list.
A detailed description of changes is available in the Hume 2.23 release notes in the documentation portal.
