
Welcome to our LLMs and knowledge graphs series. In this collection of blogs, we embark on a journey at the intersection of cutting-edge large language models and graph-based intelligence. Whether you’re a seasoned data scientist, a curious developer, or a business leader seeking actionable insights, this series promises to demystify the synergy between LLMs and knowledge graphs.
What to expect
Each blog in this series delves into practical applications, challenges, and opportunities arising from the fusion of LLMs and graph technology. From transforming unstructured text into structured knowledge, to prompt engineering and unraveling complex relationships, we explore how these powerful tools can revolutionise information extraction and decision-making.
Explore how LLMs breathe life into the Rockefeller Archive Center’s Officer Diaries, revealing funding patterns and bridging the past with the present.
Several scientists in the first half of the 20th century made enormous contributions to science and technology in different fields. We can mention several Nobel Prize winners, including Albert Einstein, Ernest Lawrence, and Niels Bohr, who provided fundamental contributions to physics studies. But what about their role as fundraisers? And what about their influence in funding research topics unrelated to their scientific contribution, such as life sciences and biology?
Institutions such as the Rockefeller Archive Center (RAC) collect information about science funding, including its long tail. In particular, RAC is a major repository and research center for studying the Rockefeller Foundation’s (RF) philanthropic activities and their impact worldwide. Among the documents used in this project, there are the Officer Diaries (ODs) dating back to the 1930s, which report on conversations between the RF Officers (Foundation’s representatives responsible for identifying research projects for funding) and scientists working on specific research topics in the natural sciences domain. This dataset was chosen because this is the exciting era when modern research topics, such as molecular biology or nuclear science, were being formed and defined.
Such diaries play an essential role, because the reported conversations and interactions between people may lead to the granting of a specific research project. However, understanding the dynamics driving the RF granting process is complex and requires producing well-structured data shaped as a Knowledge Graph (KG). Consider the case of Niels Bohr: he made foundational contributions to understanding atomic structure, but as reported by Wikipedia, he was also a promoter of scientific research. The KG created on the ODs revealed how this supporting activity has been concretely realised.
Moreover, this blog post will describe how we adopted the OpenAI GPT models in a production-ready and scalable environment to produce a high-quality KG on top of the ODs’ textual content. This environment is shipped with GraphAware Hume, GraphAware’s end-to-end graph analytics platform. The lessons learned in this article can be easily applied and extended to different application domains, from science to law enforcement, by combining the powerful features of GraphAware Hume and GenAI.
Let’s dive into the details
To move from Officer Diaries (ODs) to a KG, we exploited GPT and GraphAware Hume’s capabilities in several situations to build a meaningful, useful, and high-quality KG.
Our journey will start with an overview of the entire information extraction pipeline, and then continue with a discussion of the details.
The information extraction pipeline built for this use case involves several steps, each of which plays a crucial role in extracting relevant information accurately and efficiently.
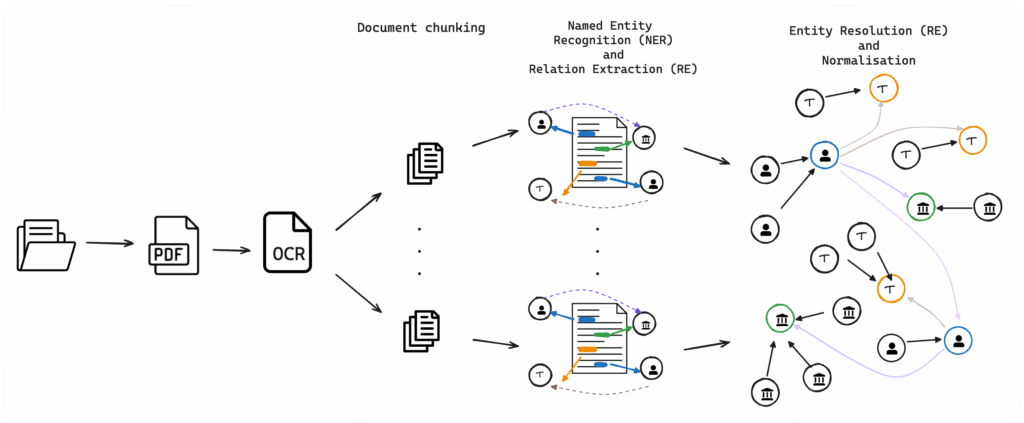
The main steps are:
- Document chunking: an ad-hoc chunking strategy for extracting diary entries;
- Named Entity Recognition(NER): identifies and classifies named entities mentioned in unstructured texts into predefined categories;
- Relation Extraction(RE): detects and classifies semantic relationships among pairs of entities;
- Entity Resolution(ER): creates a connection between different data records referring to the same entity.
Document chunking: Entry extraction from officer diaries
Usually, the processing of a large document can not be performed in one shot, but requires a chunking strategy. GPT comes with a token limitation that, despite rapidly increasing with the release of new versions, does not allow us to process the whole dataset at once. Besides, in our experience, the longer the text to be analysed, the poorer the quality of the entities and relations extracted.
In our case, the documents are Officer Diaries (ODs), so the natural way to divide them is to consider the dates when each diary entry was written. This step is fundamental for our use case because improper document segmentation risks losing valuable context, which is necessary for high-quality NER and RE.
For the document chunking, we perform a Date Extraction step that extracts the dates within the pages corresponding to diary entries.
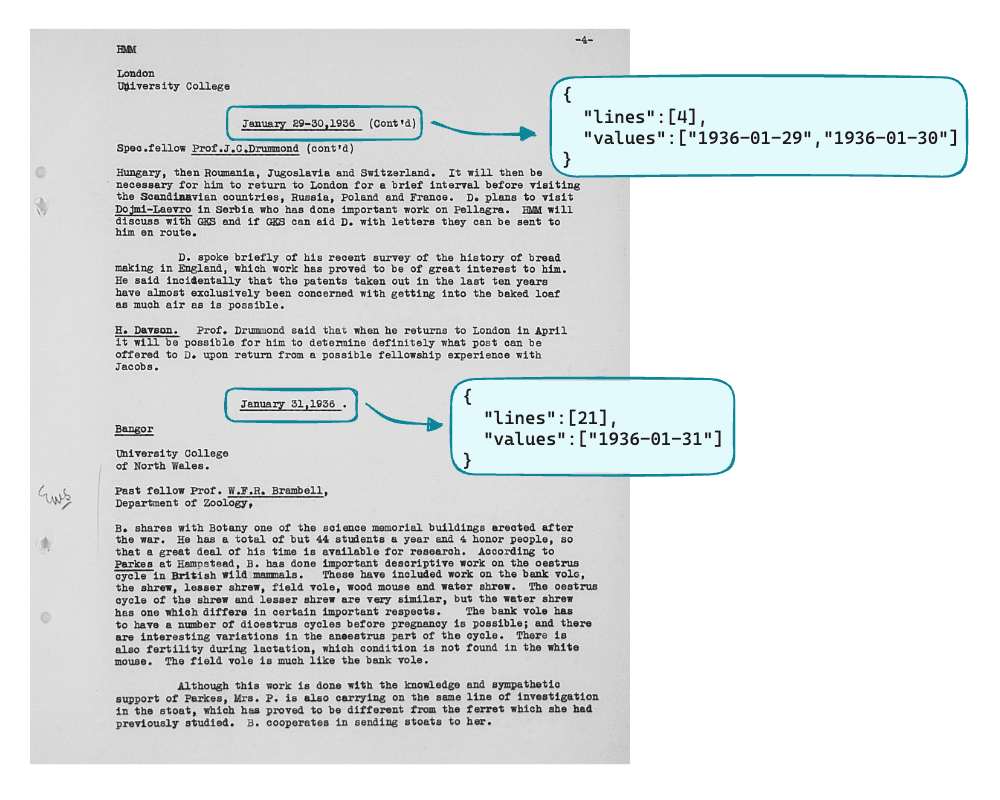
For the Date Extraction, we provided GPT an input list of enumerated lines corresponding to the page rows. For each page row, we specify in the prompt to detect a date that corresponds to a diary entry. The output format is a list of JSONs, wherein each element contains the lines in which the date appears and the normalised date, or a range of dates.
The Date Extraction process includes different steps for robustness reasons.

The first extraction attempt is done using the gpt-3.5-turbo model. If a failure occurs, a second attempt will be made using the gpt-4 model. The last step is to check if the result includes only diary entry dates and not generic dates mentioned in the text. By leveraging the extracted dates, we reconstruct the text of the Officer Diary Entries (ODEs).
NER and RE on officer diary entries
Executing NER and RE with GPT in a production environment requires considering multiple aspects:
- The documents’ length and the related impact on the accuracy of results.
- The flexibility in using multiple prompts to manage different cases and scenarios.
- The robustness against the failures of GPT services, and the results generated in an unexpected format.
To satisfy these requirements straightforwardly, we can directly leverage the features of the Orchestra system integrated into the GraphAware Hume platform.
Processing ODEs based on the length
As discussed in the previous section, extracting fine-grained information using GPT requires splitting the full ODs into individual diary entries (ODEs). However, in some cases, the input text is still long for the task we have to perform because some detected ODEs are spread over multiple pages.
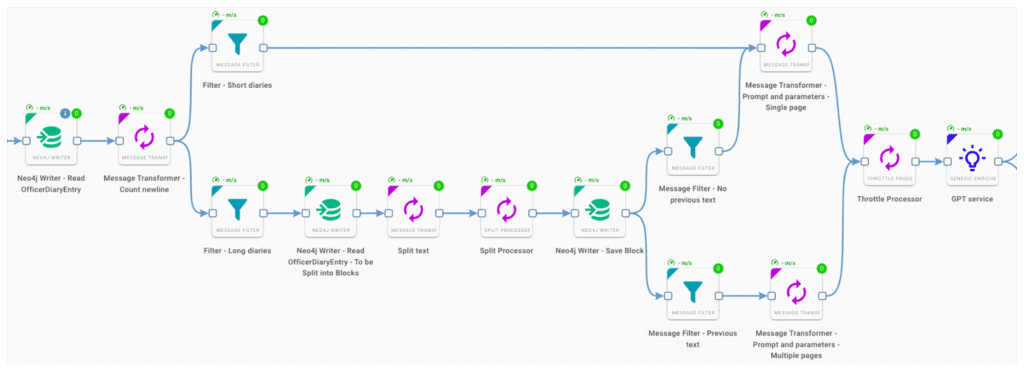
The figure above shows the Orchestra workflow built to process the text of the ODEs. More precisely, to deal with the situation mentioned earlier, we defined two branches: a straightforward one to process short diary entries and a more complex one, in which the text of the long diary entries are first split into blocks and then processed. This splitting step is adopted to manage the token limitation of the used GPT model (gpt-4) and, more importantly, to limit the degradation of the response quality related to long inputs. We noticed that this aspect must be considered in this type of task and, in general, in extracting facts from text using a generative model.
The components used to create the prompt are: Prompt and parameters – Single page and Prompt and parameters – Multiple pages. The goal of both prompts is to perform NER and RE tasks. However, the key difference between them is how they compose the prompt. Indeed, for ODEs split into blocks, it’s needed to add context (from the previous block to the one that we are processing), to take advantage of GPT’s implicit co-reference capabilities, or to handle the case where a sentence is split across the two blocks.
Process robustness
One of the key aspects related to the usage of GPT in a production-ready environment is related to failure management. We can identify two different types of failures:
- GPT service failure: this could be related to multiple reasons, from malformed input to unavailability.
- GPT response parser failure: the result is not in the expected format. Beyond the specificity of the prompt, this could happen due to the generative nature of the model.
To manage these cases, and potentially others, Orchestra workflows enable you to define branches useful to manage the failures of single or multiple components involved in the main process.
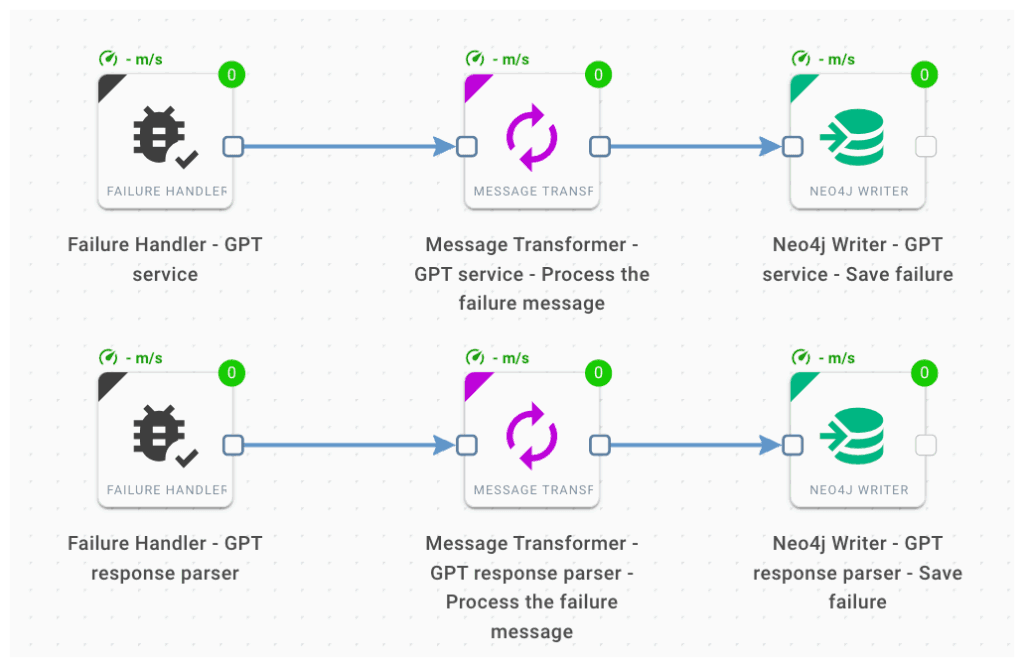
Each branch allows us to perform specific operations in case of component failures. In this scenario, we assign a distinctive label to the diary entries that generate the error to enable targeted investigation and, if needed, refine the process accordingly.
NER and RE results at a glance
In order to build an accurate Knowledge Graph from unstructured data, we need a high-quality knowledge extraction system that covers key building blocks such as NER and RE. To understand the effectiveness of this process, consider the following figure, which reports different pieces of text from a single Officer Diary Entry (ODE):
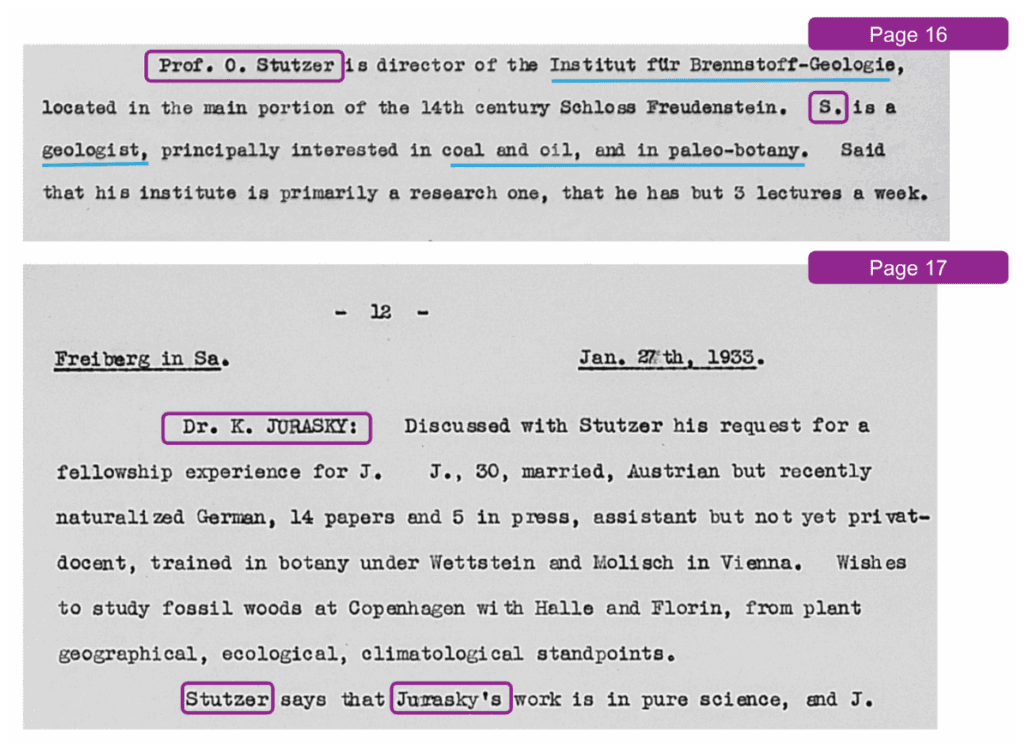
In this case, Prof. O. Stutzer is explicitly mentioned once on a single page of an ODE. Then, on the same page is mentioned as S., and he is mentioned again as Stutzer on the following page. Moreover, each of these mentions is related to mentions of different entities such as organisations, occupations, and other people.
Our goal is to produce a single node in the KG that corresponds to a unique entity representing all these different mentions of O. Stutzer and build the related relationships accordingly. To reach this goal, we instructed the model to recognise these situations. Moreover, we defined a prompt for leveraging the contextual information from the previous page to reconstruct the full names.
The following graph represents the result of performing advanced NER and RE steps on the previous text:
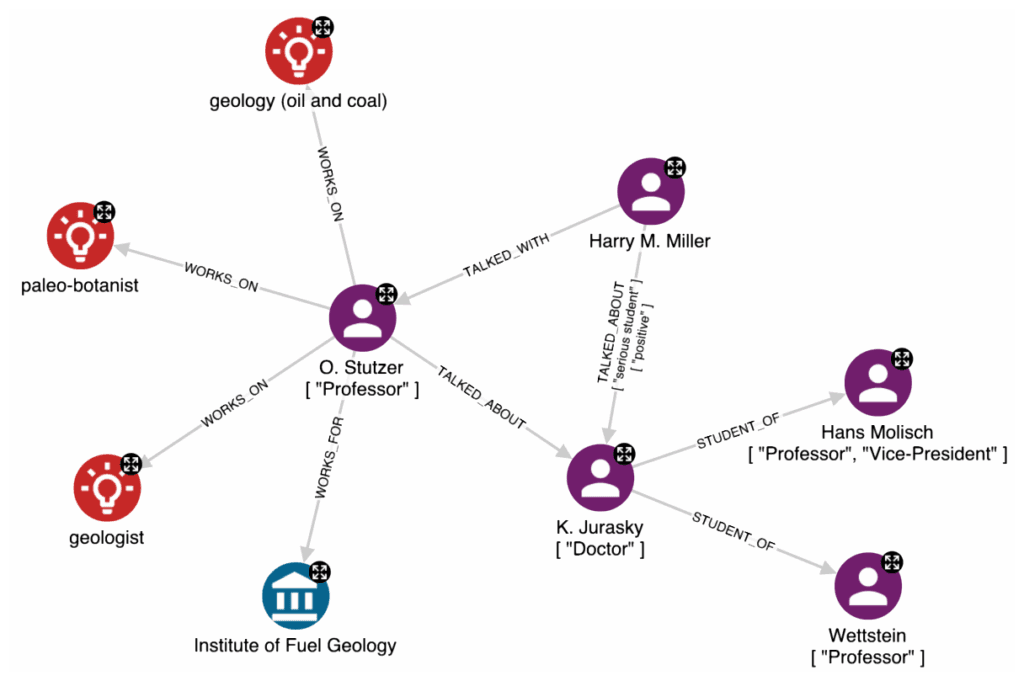
As you can see from this example, strings such as O. Stutzer and K. Jurasky have been recognized as person entities (purple nodes), while strings such as paleo-botanist and geologist have been recognized as occupation entities (red nodes). Moreover, in the case of person entities, the model has been able to reconcile different namings and perform the RE in an effective way by connecting O. Stutzer to the related entities.
Starting from NER and RE tasks, we are able to extract more specific information that is relevant for the application domain, such as sentiment analysis and conversation extraction.
Sentiment analysis
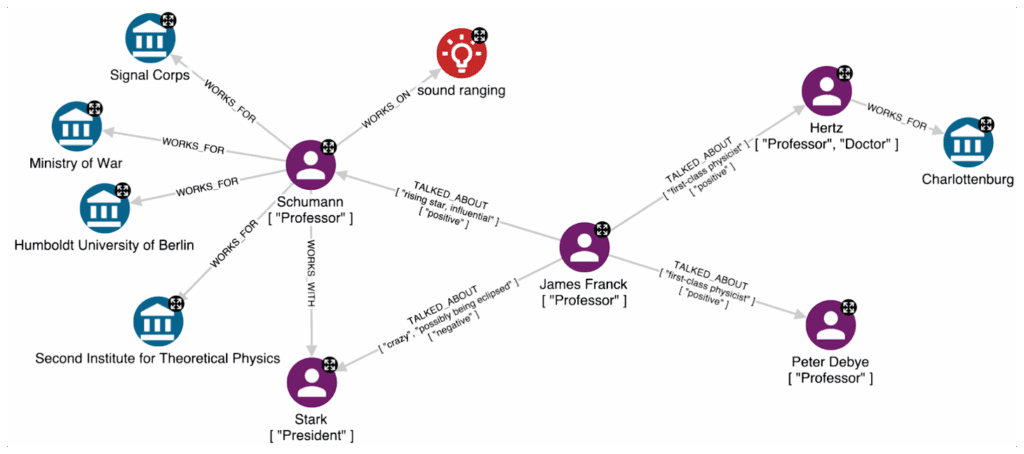
When reading through the diaries, we noticed how often the people also shared their personal sentiments about others. This could be a very important part of KG-based analysis of grant assignment patterns, allowing us, for example, to identify true influencers. By adjusting the GPT prompt related to TALKED_ABOUT relations, we can easily identify and store these complex impressions. Consider the following excerpt:

From the text, the opinion of J. Franck about some colleagues is clear. First, he talked about Stark and Schumann, expressing that Schumann outclassed Stark, and then he cited Hertz and Debye as first-class physicists in Germany. All this information has been correctly extracted, and the figure below contains the resulting graph.
Conversation Extraction
The diary entries are abundant in detailed descriptions of conversations between Rockefeller Foundation officers and scientists about their research projects. Consider the following piece of text:

Our goal is to identify these discussions in the text and convert them into conversation nodes with many details, including the participants, the discussed topics, and the context, such as an in-person meeting or a lunch. We added a requirement to identify had conversation with relation types in the prompt.
Prompt:
[...] "had conversation with" (i.e., an Officer talked with one or multiple persons present at the time) [...]
Example:
{
"entities": {
"person": [
{"id": 1,"name": "William Meade","titles": []},
{"id": 2,"name": "WW","titles": []}
]
}
}
{
"relationships": {
"had conversation with":[{"source": 2,"targets": [1],"context": "on-site"}]
}
}The result, modelled as a grap,h is the following:
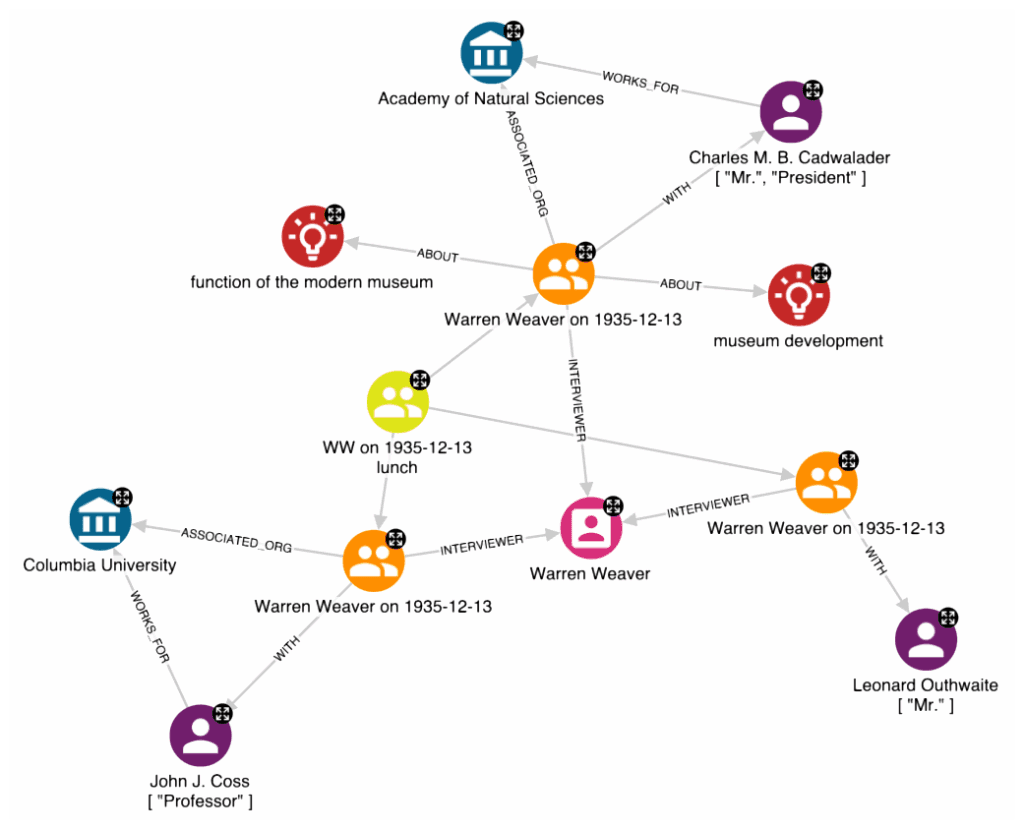
The model correctly identified a lunch conversation on December 13, 1935, between Warren Weaver (WW) and Prof. John J. Coss et al. about the function of the modern museum.
Let’s wrap up
The following figures show the graph result we are able to achieve by combining all the previous ingredients.
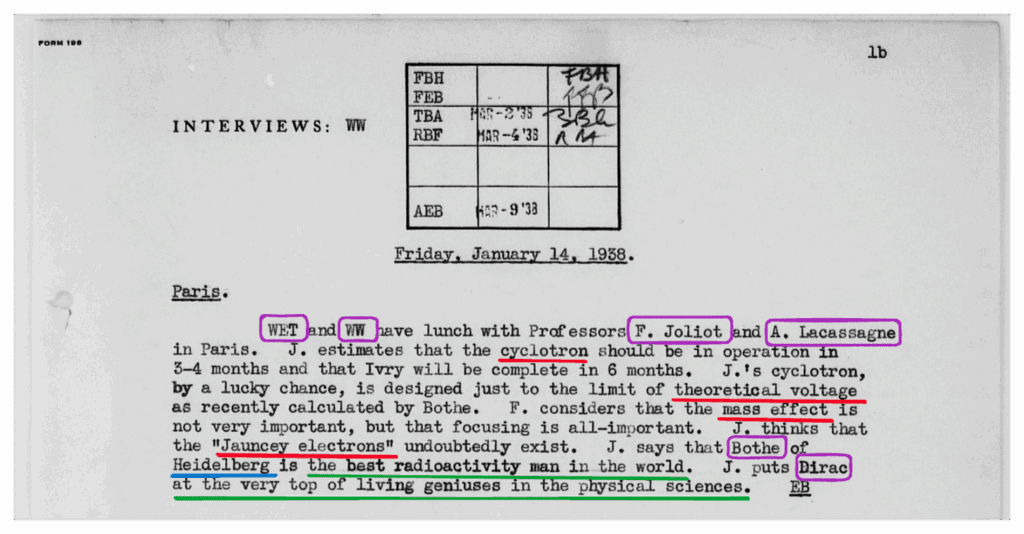
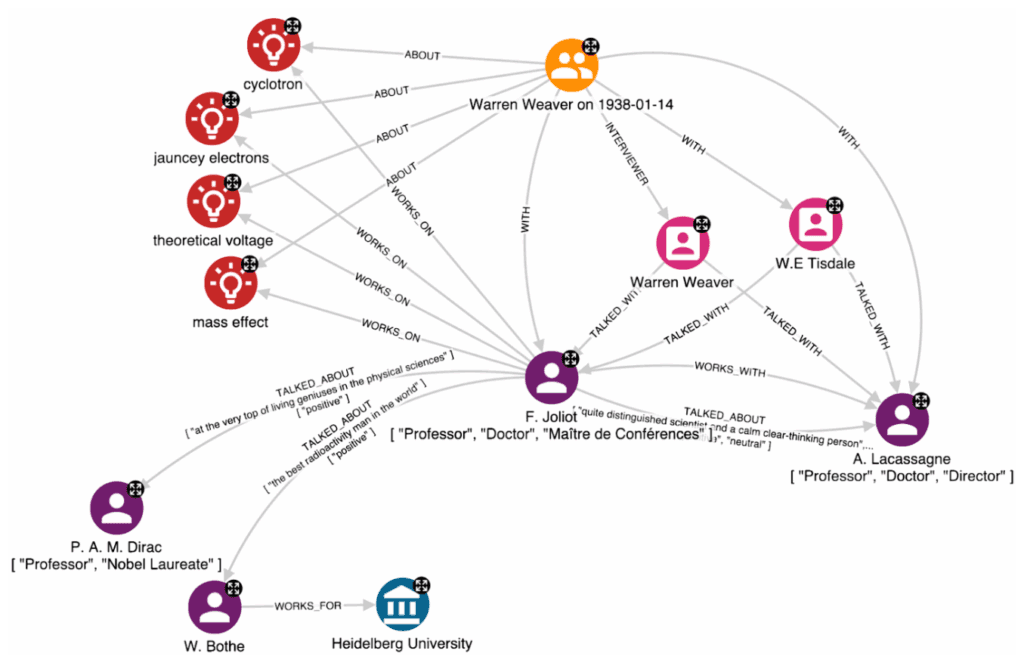
This example shows how we are able to represent in a powerful way a conversation between the two RF Officers, Warren Weaver and W. Tisdale, and two scientists, W. E. Tisdale with A. Lacassagne and F. Joliot. The latter also mentions the research activities of W. Bothe and P. A. M. Dirac. By reading the text, you will notice that these two people are mentioned only by their surnames. Moreover, there is no previous textual context that contains the full names. However, one of the key aspects of building a high-quality KG is to identify the same person or organisation, beyond their multiple expressions in different pages or documents, to resolve ambiguous entities and represent them with unique nodes.
Graph-based entity resolution with GPT
Entity Resolution (ER) is a widely applicable approach to resolving data into unique and valuable entity profiles. This crucial process allows organisations to make key decisions based on complete and/or unscattered data.
In the case of unstructured content, the objective is to reconcile ambiguous entity mentions across paragraphs, pages, and even other documents into final resolved entity nodes.
For example, consider these different pieces of text coming from different ODEs of Frank B. Hanson (FBH), shown in the figure below that mentions “Curtis”.

In this case, page 121 of the FBH ODE from 1934 mentions the surname Curtis. Another ODE from 1933 mentions the full name W. C. Curtis. And the last ODE from 1938 mentions Howard J. Curtis. Based on different sources, could we leverage the relations generated by GPT on these different person mentions to clearly state that Curtis corresponds to W. C. Curtis or Howard J. Curtis, or neither?
Person ER through organisations and topics normalisation
To perform ER on person entities, we cannot only consider the similarity of names, but we also need to include other signals to increase the fidelity. By performing complex Relation Extraction (RE) tasks, we have associated most of these names with the organisation they work for and the scientific field or topic they work on.
Although information about organisations and research topics is particularly useful, such information could be expressed in different ways. For instance, Oxford University could be interchangeably expressed as Oxford or University of Oxford. More advanced scenarios allow us to understand that Christ Church, Oxford, is somehow connected to the academic institution.
Regarding the topics, we can express the same research field using different words. For example, radiation problems related to living organisms and effects of radiation upon living organisms express the same concept, but the adopted strings use different terminologies.
To address these specific issues and to aggregate (and potentially reconcile) the different expressions for organisations and topics, we adopted two different approaches, one based on the definition of a proper prompt and the other that leverages the embeddings computed by GPT.
In the case of the organisations, we specifically asked GPT to normalise the names and understand the hierarchical connections between the organisations. To reach this goal, we defined an Orchestra workflowin which the organisation names extracted from GPT during the NER/RE phase are passed again as input to GPT for the normalisation task. The defined prompt includes the following key information:
Prompt:
[...] normalize the organization name, identify the main institution of the organization (if exists) [...]
{
"name": "harvard school of medicine",
"name normalized": "Harvard Medical School",
"main institution": "University of Harvard"
}The resulting graph is the following:
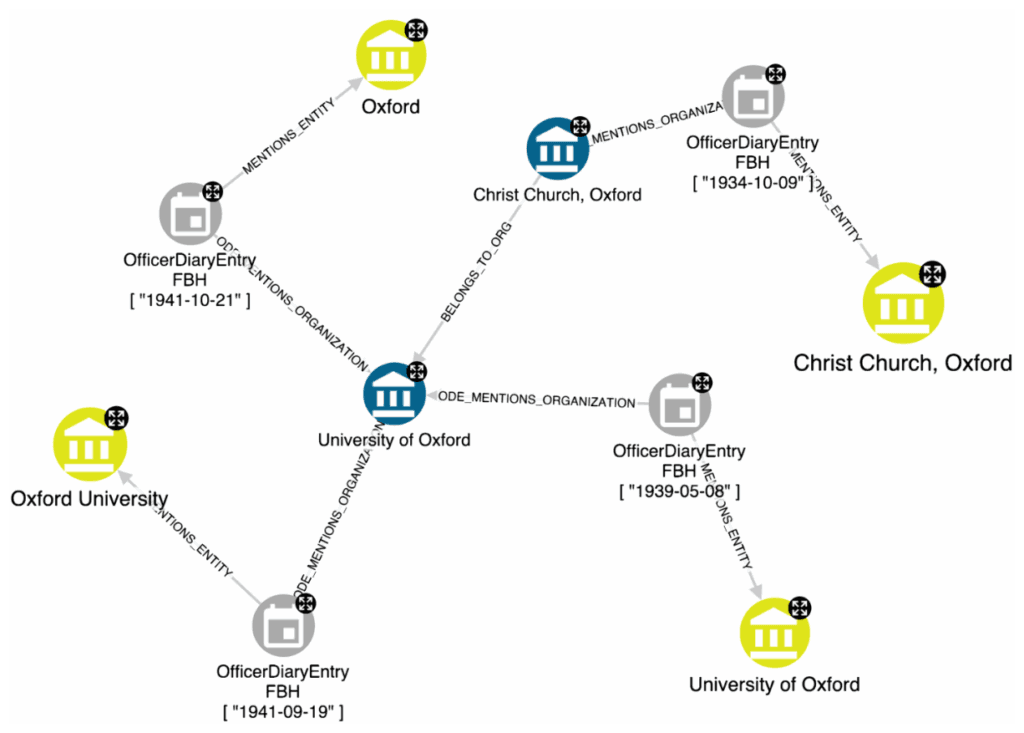
The yellow nodes are the entities extracted during the NER/RE phase, while the blue nodes define the resolved entities. This operation is beneficial for noise reduction, because the analyst will analyse only two nodes and their relationships, instead of four disconnected nodes.
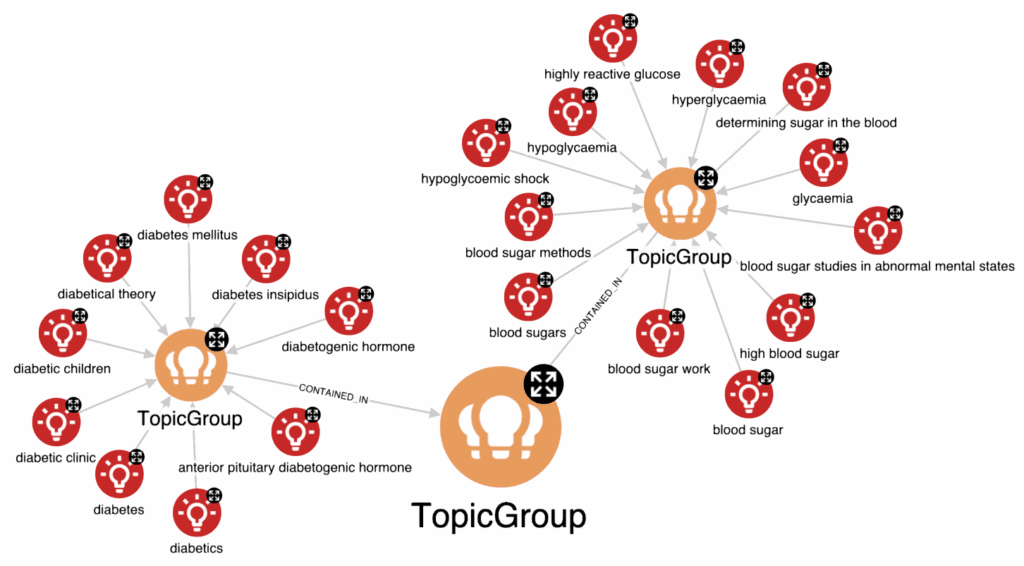
Regarding the topics, our purpose is to group them in terms of semantic similarity. To achieve this, we decided to jointly exploit embedding and clustering operations. The former allows us to project topics in a vector space, where the closer the embeddings are to each other, the more semantically similar the topics are. More precisely, the embeddings are computed through the text-embedding-ada-002 GPT model. The latter uses this closeness to group topics according to the desired semantic granularity using hierarchical clustering. The following figure shows the cluster (group) related to hyperglycemia. The topics are grouped into TopicGroup nodes, which are themselves grouped hierarchically. This enables the selection of the most suitable semantic grain for the use case, as in the example where a coarser grain allows merging the cluster related to hyperglycemia with the one related to diabetes. Both embedding and clustering operations have been performed using Orchestra.
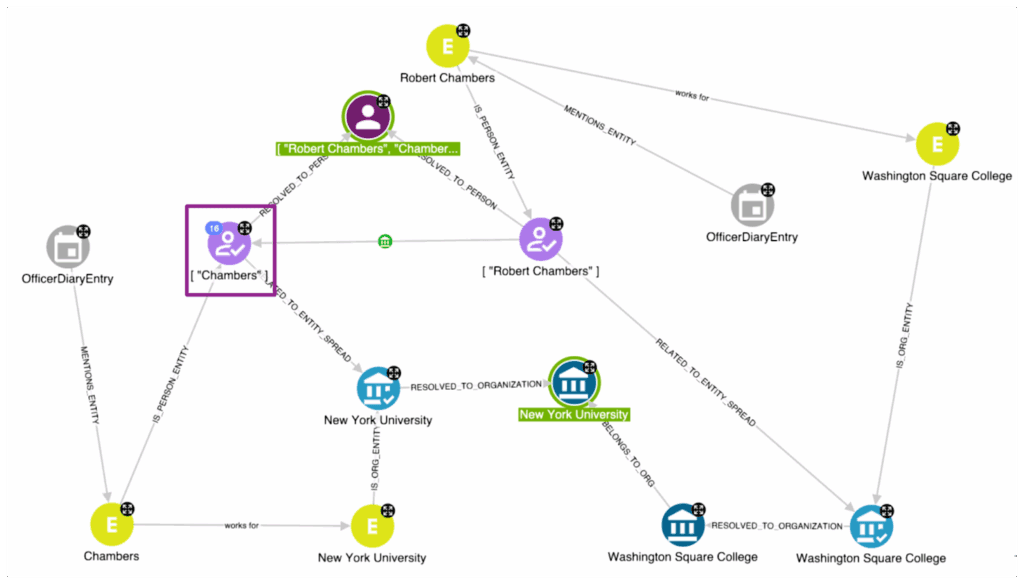
Let’s see the impact of these normalisation steps in terms of persons’ resolution. The graph below shows why Chambers and Robert Chambers nodes must be resolved as the same person. The first one explicitly works for New York University. The second one works for Washington Square College. However, GPT recognized that the University and the College are connected. As reported on the New York University page in Wikipedia:
“In 1914, Washington Square College was founded as the downtown undergraduate college of NYU”.
Based on this non-trivial connection, we can state that Chambers and Robert Chambers very likely represent the same person in the real world, which would not be a conclusion accurate enough purely based on the same surname.
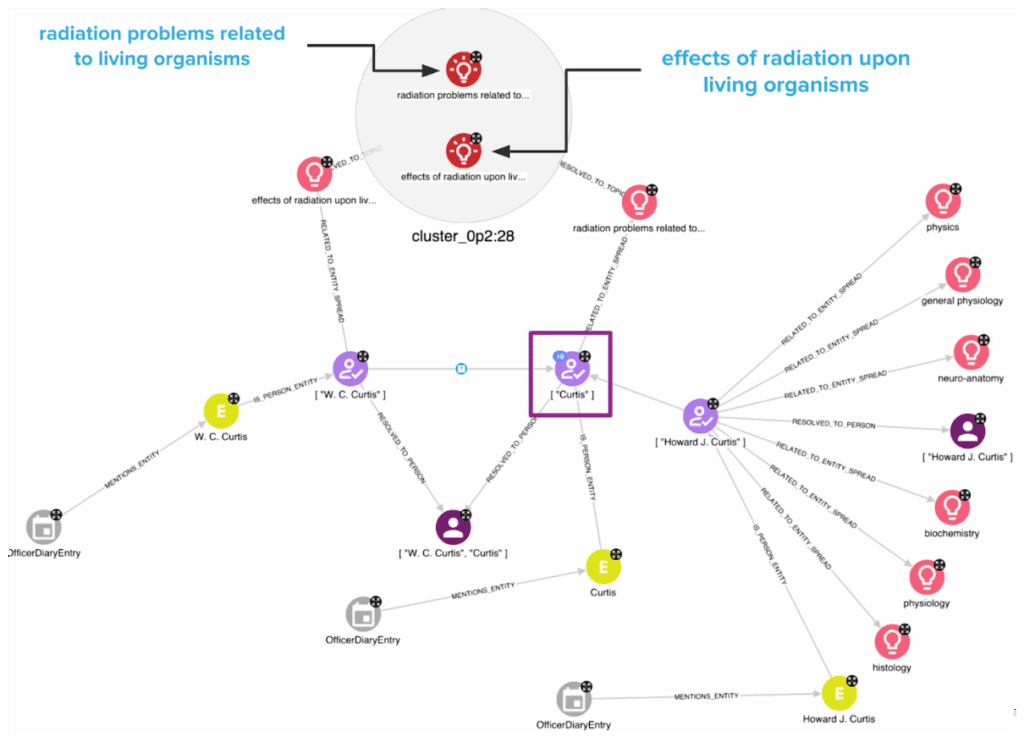
Now, let’s try to answer the question we posed at the beginning of this section dedicated to ER:
“Could we leverage the relations generated by GPT on these different person mentions to clearly state that Curtis corresponds to W. C. Curtis or Howard J. Curtis, or neither?”
The graph available below answers the question. As you can notice, Curtis works on radiation problems related to living organisms, while W. C. Curtis works on the study of the effects of radiation upon living organisms. These two strings represent the same research field, but a trivial algorithm for string similarity would struggle to detect such similarity. On the contrary, our approach to managing semantic similarity allows us to correctly resolve Curtis as W. C. Curtis and not as Howard J. Curtis.
KG-based insights discovery
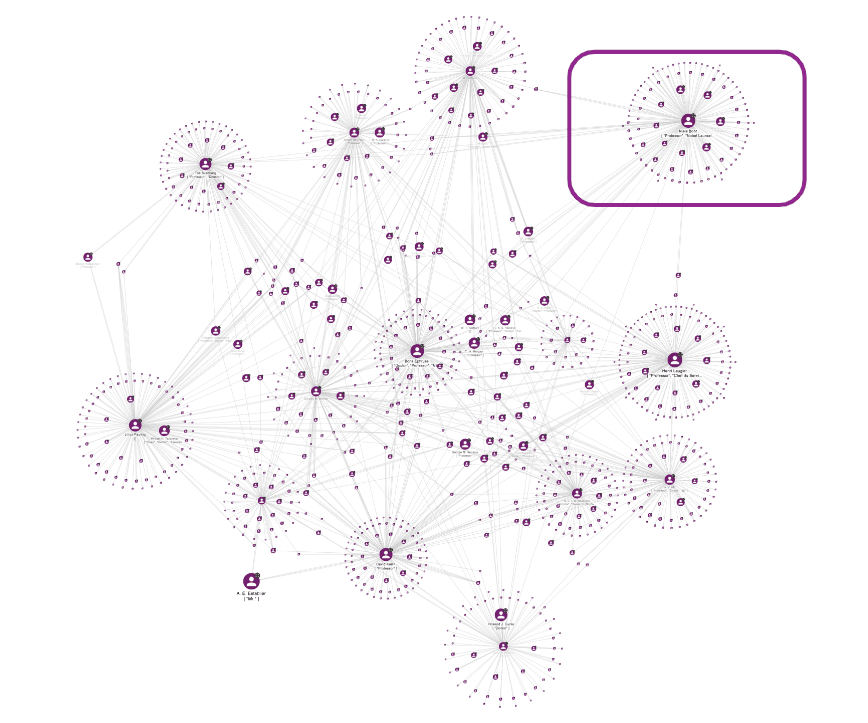
The KG constructed using GPT combined with the GraphAware Hume capabilities enables us to investigate the network-based dynamics that can reveal, for example, the influence of scientists such as Niels Bohr in promoting research activity. This analysis can start with the influence network that shows the most influential scientists by leveraging multiple relationship types, including TALKED_WITH, TALK_ABOUT, STUDENT_OF, and WORKS_WITH, and graph algorithms revealing patterns and insights.
The figure below gives you an idea of the complexity of this network (it represents only a sub-graph of the whole influence network), in which the dimension of the hub nodes depends on the score computed by the PageRank algorithm. In this context, PageRank measures the importance of a person within the network based on the number of incoming connections and the significance of the corresponding source of the relationships. This perspective is beneficial for our purpose, because if many relevant persons actively interact with a hub, this means that this hub can influence decisions. One of the most important communities in this network shows that Niels Bohr is a central node (highlighted in the figure below).
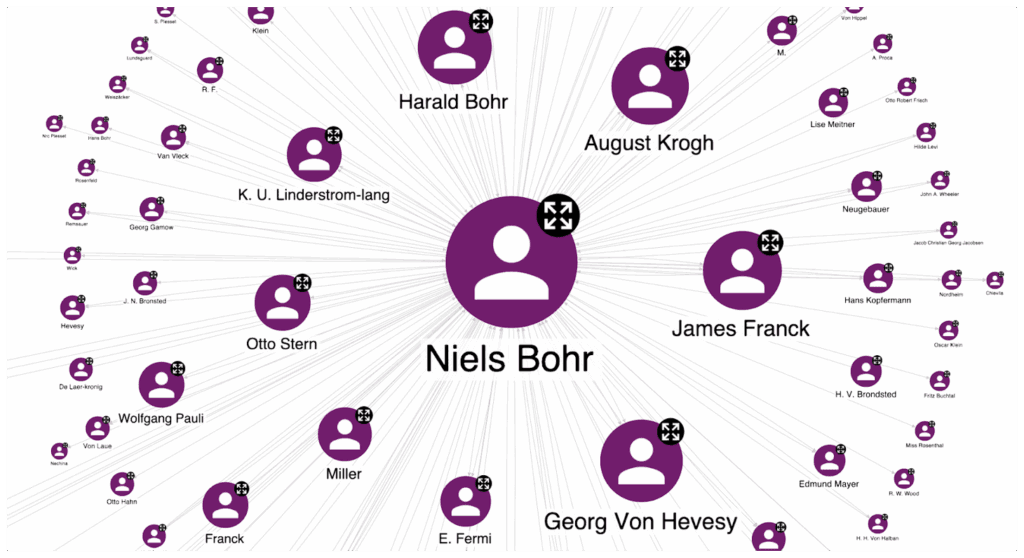
Suppose you take a look at Niels Bohr’s Wikipedia page. Several scientists from this community (see the image below), such as Otto Stern, Harald Bohr, Georg Von Hevesy, and James Franck, are mentioned on this page and belong to Niels Bohr’s scientific field. On the one hand, this confirms that the network dynamics that emerged from the ODs correspond to well-known knowledge about these scientists, in particular Niels Bohr. On the other hand, we are interested in discovering long-tail information related to the influence of Niels Bohr in enabling the funding of different scientific fields.
To reach this goal, we can continue our investigation by exploring the grants awarded by the Rockefeller Foundation mentioning Niels Bohr, and focusing on research topics that are not directly connected with his research activity. Consider the following example showing a grant depicted with the green colour.
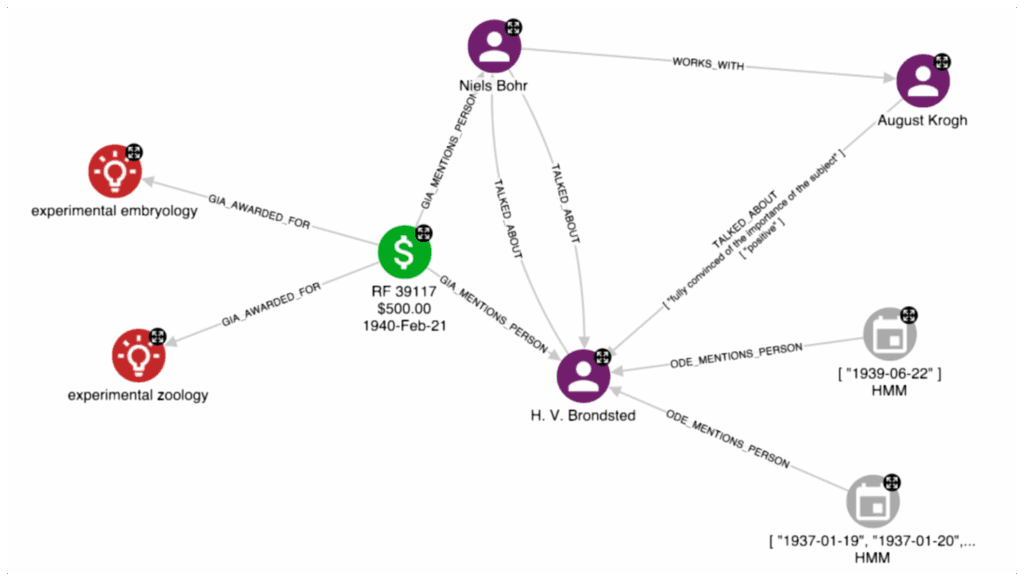
By exploring the connections to the grant, we discovered that it has been assigned to H. V. Brondsted and it has been awarded to biology topics, such as experimental zoology. Moreover, the grant details mention Niels Bohr. Starting from this grant information, the information extracted from ODEs, and the KG built on top of this information, we can try to answer the following question:
“Could we reconstruct the interactions between H. V. Brondsted, Niels Bohr, and other related key persons that may have led to the awarding of the grant?”
From the graph above, we noticed that there is a reciprocal TALKED_ABOUT relationship between H. V. Brondsted and Niels Bohr. Moreover, we noticed that August Krogh, one of the main collaborators of Bohr based on his personal network, also has a TALKED_ABOUT relationship with Bronsted that provides a positive judgement about the researcher.
By leveraging this portion of the graph and running an explanation action (a cypher query defined on the GraphAware Hume platform) on the TALKED_ABOUT relationship, we can easily explore the original sources that describe how these three people interact with each other.
An initial interaction was reported in 1937 by the HMM Officer:
“Brondsted said that he has established connections with N Bohr and will investigate the effects of X-radiation on protoplasm of sponges at the Finsen Institute.”
Another ODE from 1939 further clarifies the role of Niels Bohr and August Krogh for the grant assignment.

As you have seen from this example, by combining the GPT output, KG technology, and GraphAware Hume features, we can easily reconstruct the interactions between the researchers in a straightforward way. This particular example shows how we can directly answer our initial requirement, which was related to the understanding of the influence of Niels Bohr in supporting unusual topics based on his main research activity.
Lessons learned
This blog post shows that GPT and LLMs are opening incredible opportunities in constructing high-quality and large-scale KGs from textual data, addressing complex tasks such as Named Entity Recognition, Relation Extraction, and Entity Resolution in real scenarios. As emerged from this article, we adopted multiple models during our journey. We noticed that combining various models can help address less complex tasks more efficiently, using more advanced and expensive models for managing edge cases or more complex situations. The example related to Niels Bohr suggests the enormous potential of combining LLMs with KGs for information discovery in natural language contents. Moreover, due to the flexibility of these technologies, the techniques adopted to investigate these cases can be transferred and generalised to other domains, such as journalism and law enforcement. To further show the power of combining LLMs and KG to perform more advanced insights and discoveries, a comprehensive analysis of the RAC KG will be a topic in one of the next blogs.
Leveraging LLMs for Intelligence Analysis
How Hume leverages GPT and LLMs to expedite intelligence analysis on extensive unstructured dataset

