
Data is everywhere. News, blog posts, emails, videos and chats are just a few examples of the multiple streams of data we encounter on a daily basis. The majority of these streams contain textual data – written language – containing countless facts, observations, perspectives and insights that could make or break your business.

The data, in its native form, is completely useless because it doesn’t provide any value. It is sparse, distributed and unstructured – it is chaotic.
To make sense of the data, we have to transform and organise it – a process that produces information. However, for the information to become “knowledge,” which is learned, requires more work. Knowledge is connected information. There is a big jump between information and knowledge. It is a quality change, but it is not an easy change. It requires a transformation process which, by connecting the dots, creates sense, significance and meaning from the information.
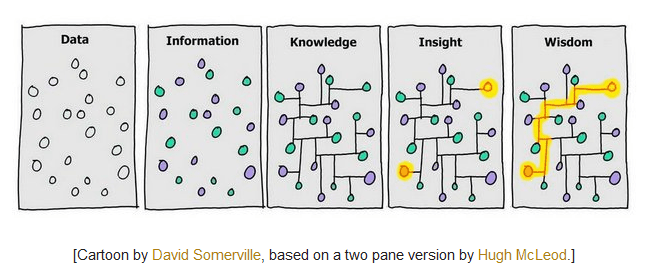
Insight and wisdom are above knowledge. They aim to identify meaningful pieces of information and relate them to each other by using, for instance, cause-and-effect relationships, similarity or dissimilarity. Insight and wisdom gained from connected data provides guidance on producing better products, making users happier, reducing costs, delivering new services, etc.
This is how to realise the full value of data, after a long transformation path, in which machine learning provides the necessary “intelligence” for distilling value from it. The graph database supports a proper descriptive model for representing knowledge, as well as a powerful processing framework to get wisdom back in return.
A mental shift (from classical KPI-based), new computational tools, and a proper “representational” model are required to help organise and analyse vast amounts of information.
This blog post describes some of the techniques needed to bring order to the chaos of unstructured data using GraphAware Hume (formerly known as GraphAware Knowledge Platform) and Neo4j.
GraphAware Hume transforms your data into searchable, understandable and actionable knowledge by combining state-of-the-art techniques from natural language understanding, graph analysis and deep learning to deliver a wide range of solutions for your most challenging problems.
Step 1: Representation matters
Whether you are working on an enterprise search engine, a recommendation engine or any kind of analytics platform, the traditional approach to organising text, based on pure inverted index – common in all the search engines – is not flexible enough to handle the multiple machine learning algorithms required for processing it. An inverted index organises the data for fast retrieval; it doesn’t produce or store any knowledge.
The task of transforming data into knowledge has two main challenges: knowledge representation and knowledge learning and construction.
Knowledge representation refers to the way in which information is modelled so that a computer program can access it autonomously for solving complex tasks. It plays a fundamental role since, if properly designed, it speeds up processing by making the concepts [re]usable and extensible. It represents an ordered and connected version of the same information that’s otherwise isolated, distributed and disorganised.
A knowledge graph is the representational model used in Hume. Knowledge graphs consist of a set of interconnected typed entities and their attributes. Here, the knowledge graph sits in the middle of the evolutionary path of data and represents the concrete enabler for AI. It collects and organises the data from multiple data sources and analyses results, providing flexible and extensible access patterns to it.
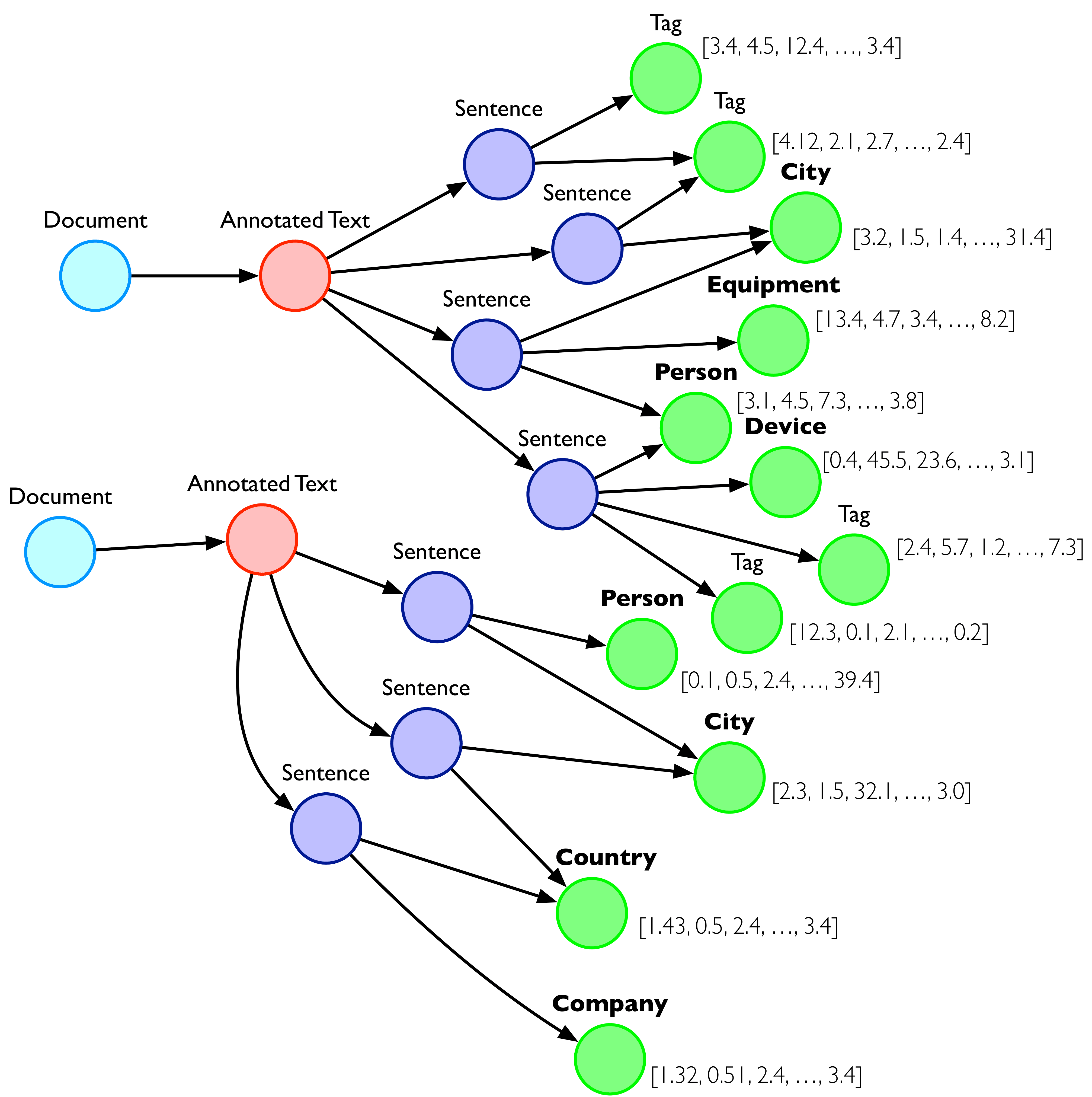
Hume uses a combination of frameworks and technologies borrowed from Natural Language Processing [1] (NLP) and, more generally, machine learning, as well as external knowledge sources for knowledge learning and construction. GraphAware Hume’s knowledge graph creation and analysis process is described in the following image.
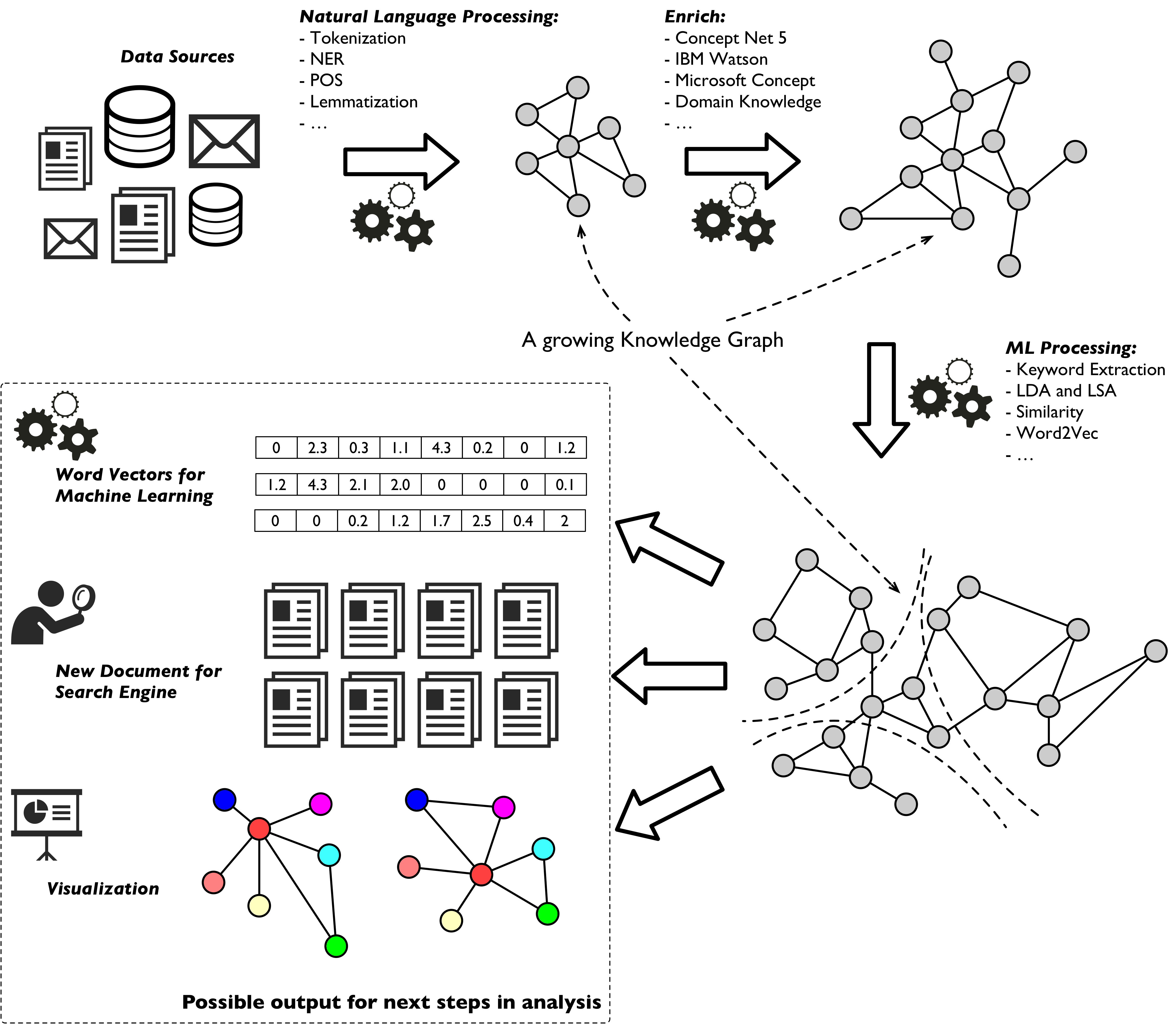
The order of the steps above can change, and each step can be executed multiple times. Step by step, the knowledge graph grows in content and capability to organise and connect concepts and documents. At first, GraphAware Hume extracts the text’s structure and represents it in the first knowledge graph.
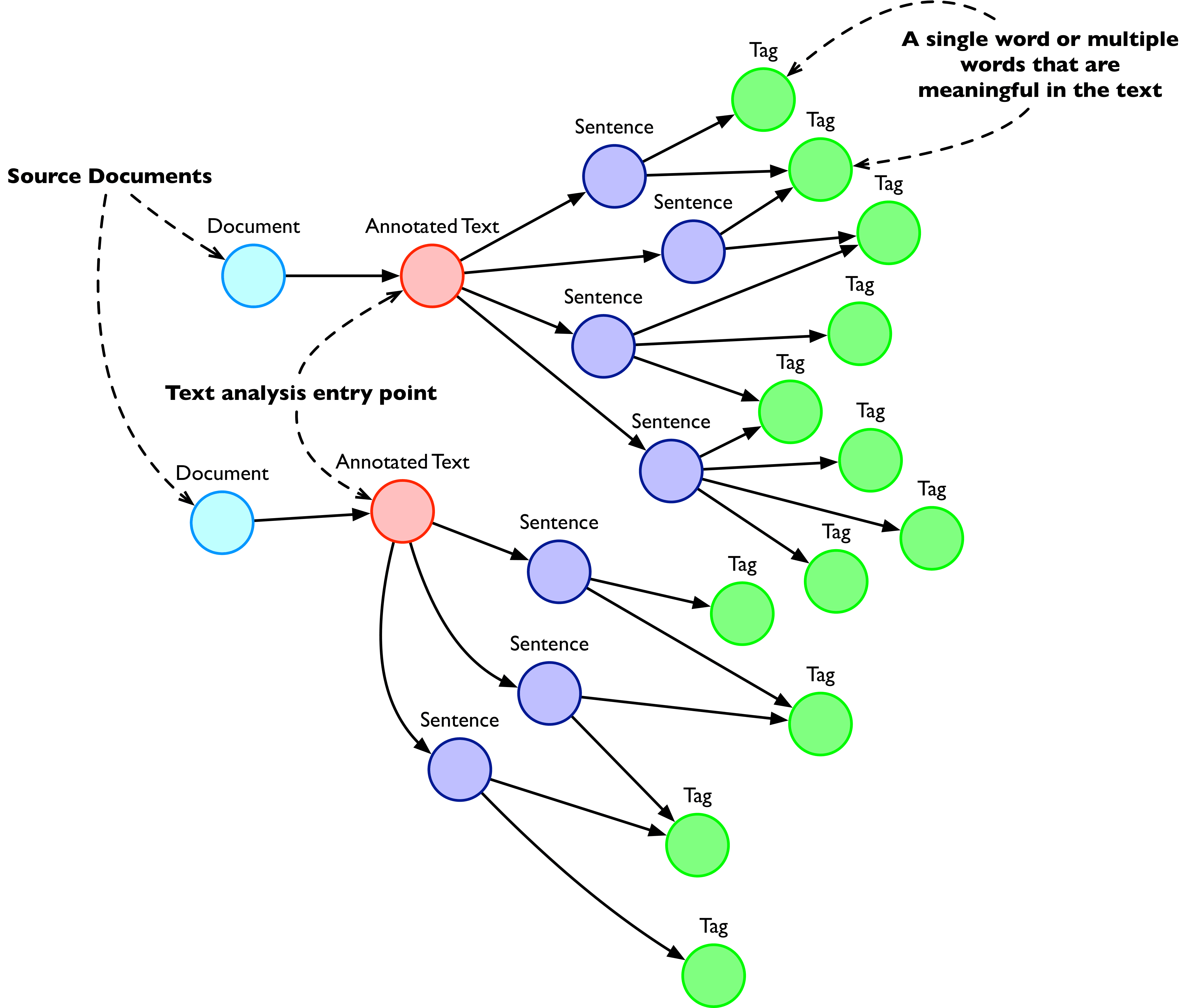
GraphAware Hume’s knowledge graph has been modelled to allow multiple representations of the text for feeding other algorithms in the pipeline.
Let’s consider the most common:
- Bag of Words (BoW): represents a text (such as a sentence or a document) as the multiset (a bag) of its words, disregarding grammar and order, but keeping frequency that represents the words’ weight in the vector.
- TF-IDF: Extends the BoW’s weighting schema, based on the pure words’ frequency in the text (Term Frequency, TF), considering it relative to the number of times they occur in the overall corpus (Inverse Document Frequency, IDF). Words that appear more often (compared with the corpus) in the current text are more relevant.
- N-Gram: BoW and TF-IDF lose a lot of the meaning inherent in the order of words in the original sentence. By extending the representation to include multi-word tokens, the NLP pipeline can retain much of the meaning inherent in the order of words in our statements. N-Grams are sequences containing up to N tokens which appear one after the other in the original text.
- Co-Occurrence Graph: It is a graph representation of a document where each node is a word, and an edge among words exists if the connected words appear in a N-grams. This is a totally different text representation compared with the vector-based one. In Hume, it is the input for keyword extraction algorithms, which use PageRank to find the most interesting words in the text.
Details are available in a previous blog post.
Here’s an example of how to extract a BoW vector from Hume’s knowledge graph:
match (n:Document)
where id(n) =
match (n)-[:HAS_ANNOTATED_TEXT]->(:AnnotatedText)-[:CONTAINS_SENTENCE]->(:Sentence)-[r:HAS_TAG]->(t:Tag)
with n, t, sum(r.tf) as tf
return collect(t.value + " : " + tf) as BoW 
Step 2: Every word counts
The first step extracts the text’s hidden structure using grammatical and lexical analysis. This analysis creates a basic graph that can be used for further analysis, but it doesn’t provide any hint about the meaning of the words or their semantic relationships.
The second step uses machine learning techniques and external sources to enrich the knowledge graph with words’ meanings.
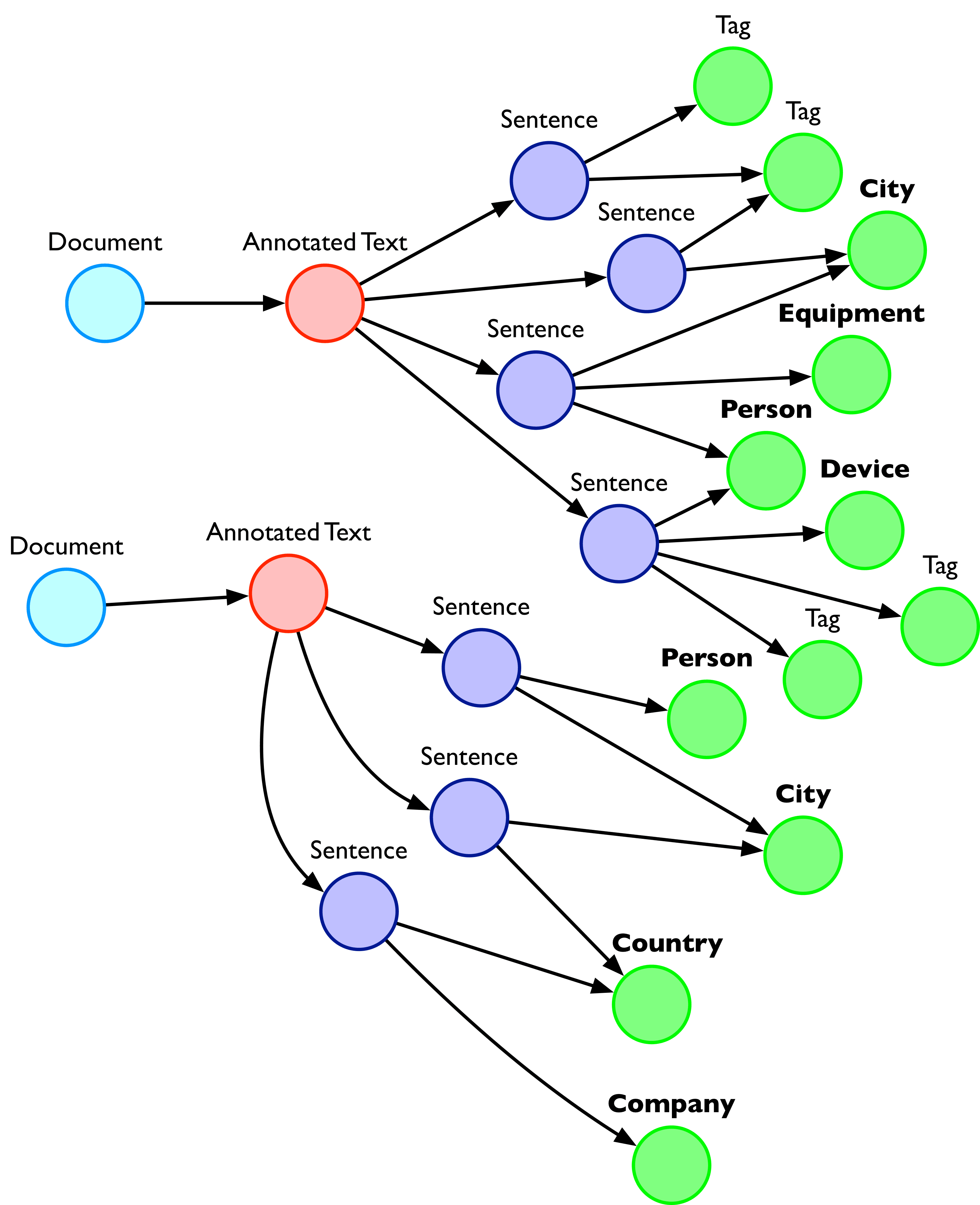
Named entity recognition
Named entities are specific language elements that belong to certain well-known categories, such as people’s names, locations, organisations, chemical elements, devices, etc.
Recognising them allows GraphAware Hume to:
- Improve search capabilities
- Connect documents (e.g connecting people in a financial document with information from a business registry)
- Relate causes (e.g weather conditions, accidents, news) with effects (e.g. flight or tram delay, stock price changes)
There are several approaches to named entity recognition, which typically require extensive training or complex configuration.
By combining multiple techniques and algorithms, GraphAware Hume delivers high-quality Named Entity Recognition models. We’ve created NER models that can be quickly added into projects for some of the most common use cases, like Companies, People, Points of interest, etc. Adding named entities to the knowledge graph gives GraphAware Hume more contextual information to use for building connections.
Word2Vec
BoW, TF-IDF and N-Grams treat words as atomic units. The advantage of that approach is simplicity and robustness. However, to transform text into knowledge, you need to identify semantic relations between words.
Word2Vec is a deep learning algorithm that encodes the meaning of words in vectors of modest dimensions [2]. The algorithm learns the meaning of words by processing a large corpus of unlabeled text. No one has to tell the algorithm that the “Timbers” are a soccer team, that Los Angeles and San Francisco are cities, that soccer is a sport, or that a team is a group of people. Word2vec can learn those things and much more on its own. All you need is a corpus large enough to mention “Timbers,” “Los Angeles”, and “San Francisco” near other words associated with soccer or cities.
GraphAware Hume provides comprehensive support for word2vec including:
- Computing word2vec from the imported corpus
- Importing word2vec (tested with Numberbatch and Facebook fasttext)
- Computing similarity between words
Computing or importing the vector for each tag in the knowledge graph allows you to extend tag nodes with a property that can be used to compute semantic distances between words. These distances are valuable since they express how much two words are related and can be used in multiple ways.
For instance, in GraphAware Hume, the distances are used for filtering out spurious named entities or finding more relevant concepts in the ontology hierarchies imported (described later).
Ontology enrichment
Sometimes the text in the corpus is not comprehensive enough for machines to automatically find the kinds of connections that humans can easily find.
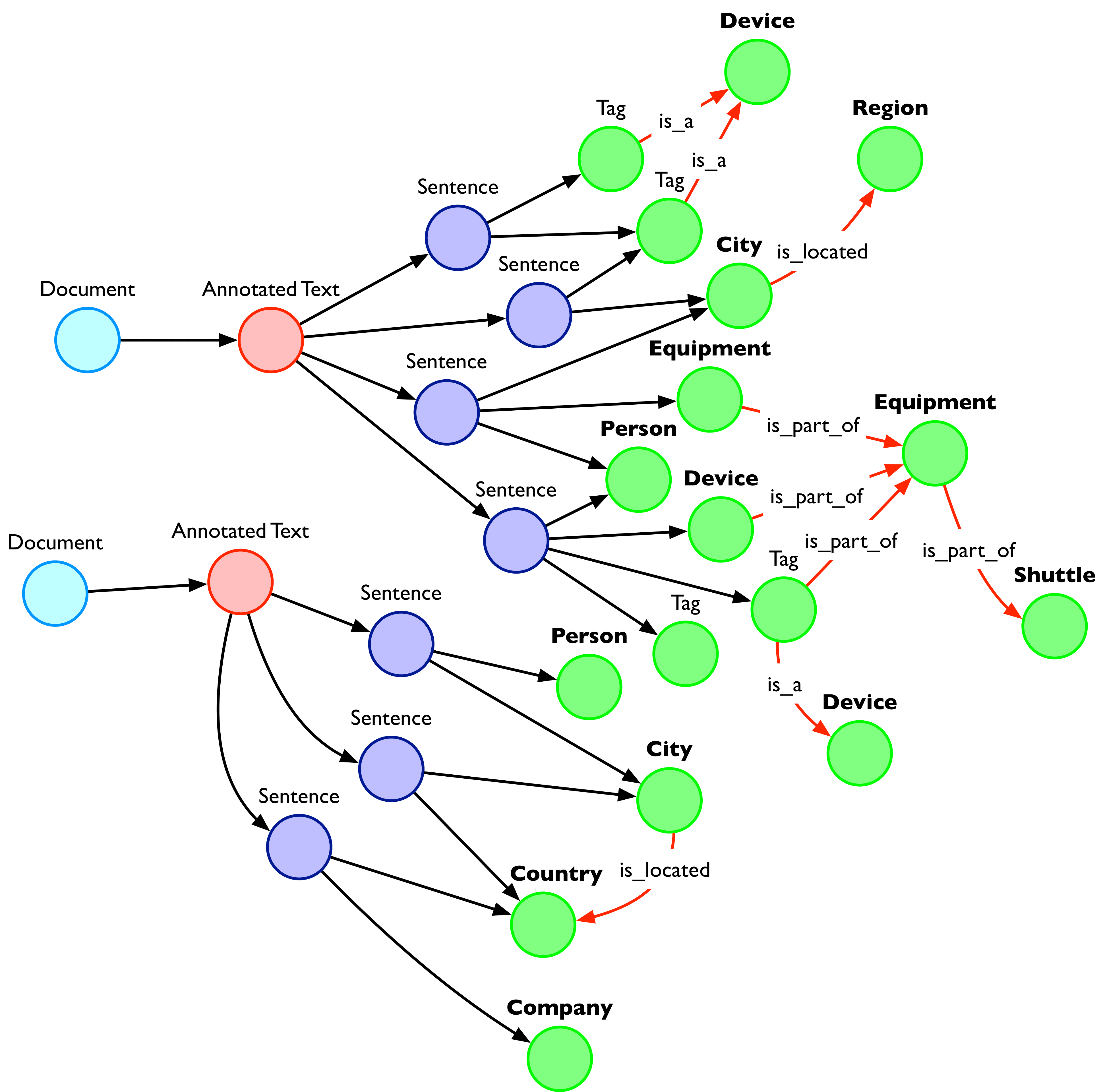
Suppose you are analysing some news and you find two articles describing earthquakes that were felt in Los Angeles and San Francisco, respectively. The machine can easily identify the two cities as locations, but it may not connect these two events because they happened in distinct locations.
To solve this problem, GraphAware Hume integrates with multiple external knowledge bases. These knowledge bases are designed to help computers understand the meaning of words by building a hierarchy of concepts. Hume queries external knowledge on demand to find new relationships.
The Cypher procedure that implements enrichment can be invoked as follows:
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships: ["IsA","PartOf"]})
YIELD result
RETURN result
In our example scenario, GraphAware Hume will learn that Los Angeles and San Francisco are both located in California, which gives it another way to connect the two events in the news articles. The enriched version of the knowledge graph looks like:
Step 3: Close to me
A powerful navigational pattern for large datasets is finding related content based on similarity. While reading a paragraph, it could be helpful for the reader to be able to find other content that expresses the same idea in a simpler or more detailed way.
GraphAware Hume supports similarity computation at different levels, including documents, paragraphs, sentences and words through simple procedures.
MATCH (a:Tag:VectorContainer)
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({
input:nodes,
property:'word2vec'})
YIELD result
return result;
Storing distances or similarities (as you would prefer to see them) is a trivial task in a graph; here is the result.
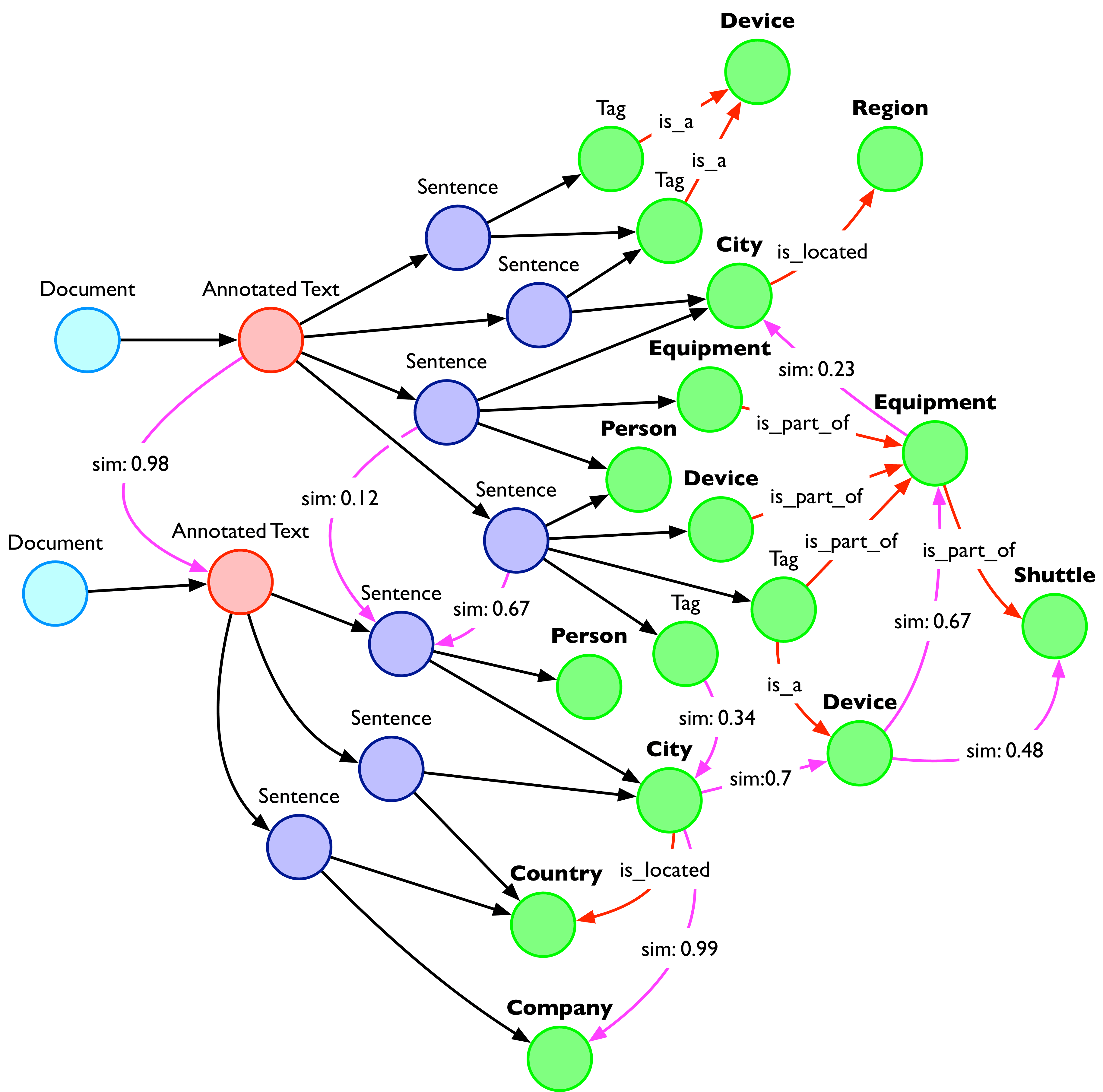
Similarities between items are useful not only for navigation – they are part of graph construction techniques which help to create a graph where we can run PageRank to identify, for instance, relevant paragraphs. This approach allows Hume to provide summarisation.
Step 4: Like by like
The typical (old-style) way we access and navigate information is by using search and link. We type keywords into a search engine and find a set of documents related to them. We then go over the documents in that result set and possibly navigate to other linked documents.
This approach is a useful way for interacting with online archives, but has many limitations since you have to know upfront the keywords and the filters. With the amount of text available today, it is impossible for humans to access it in an effective way using this approach.
Suppose you could have a mechanism that allows you to “zoom in” and “zoom out” to find specific or broader themes; you might look at how those themes changed through time or how they are connected to each other. So, rather than finding documents through keyword search before, you might first find the theme that you are interested in, and then examine the documents related to that theme.
By leveraging machine learning tools, Hume allows you to organise the corpus in themes or topics. The resulting “thematic structure” is a new view which you can use to explore and digest the collection of documents.
Probabilistic topic modelling
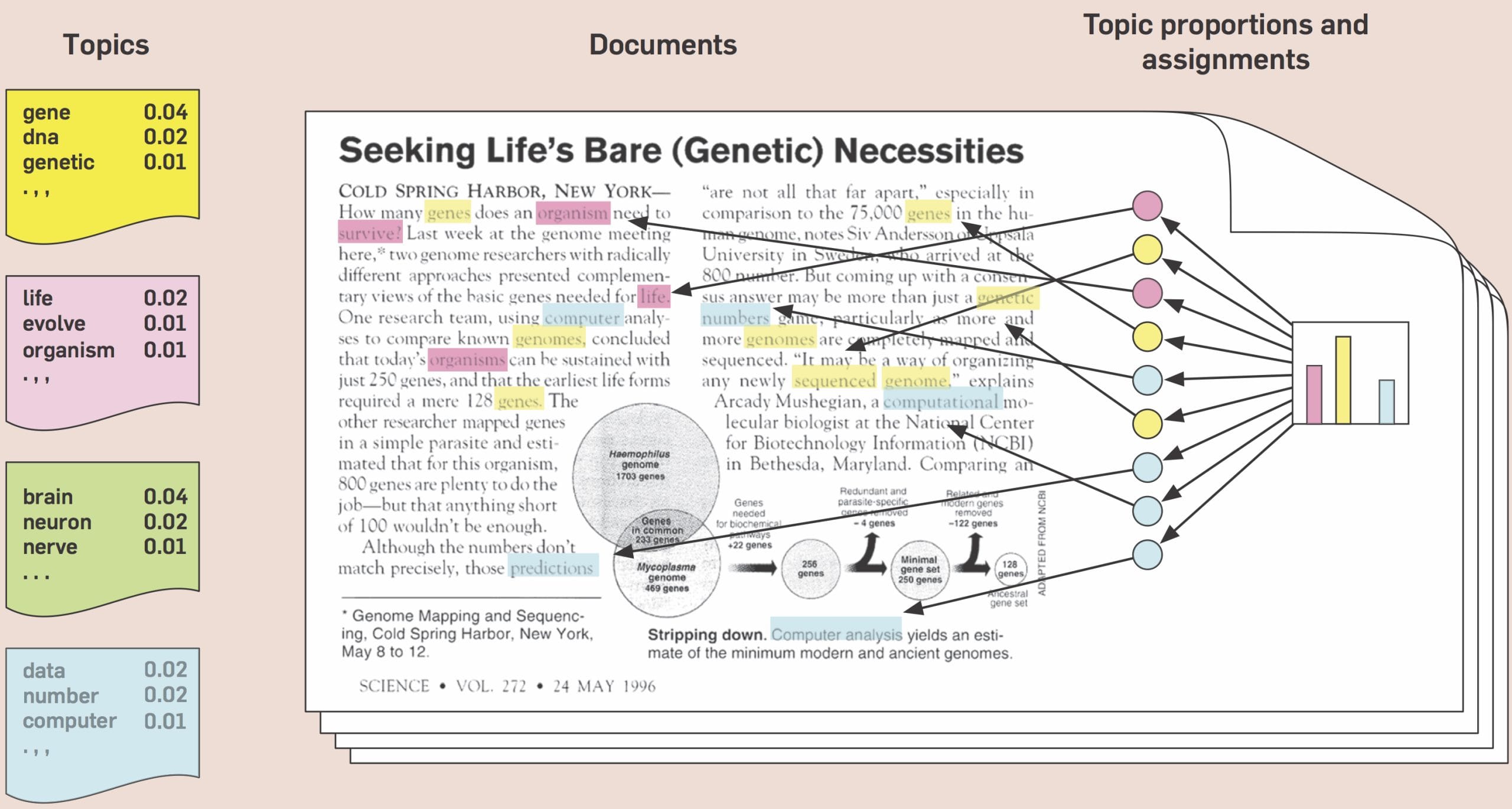
Probabilistic topic modelling algorithms, such as Latent Dirichlet Allocation (LDA), are statistical methods that analyse the words in the texts to discover the themes that run through them, how those themes are connected to each other, and how they change over time [3].
Probabilistic topic modelling algorithms do not require any prior annotations or labelling of the documents – topics emerge autonomously from the analysis of the original texts. This is a huge advantage for this kind of algorithm since they don’t require any “previous” effort in annotating documents. The topics emerge from the corpus itself.
GraphAware Hume provides topic modelling by using LDA through a couple of procedures:
CALL ga.nlp.ml.enterprise.lda.compute({
iterations: 10,
clusters:35,
topicLabel:'LDATopic'})
YIELD result
RETURN resultOnce computed, topics point to the related documents. They become new entry points for accessing or navigating your information.
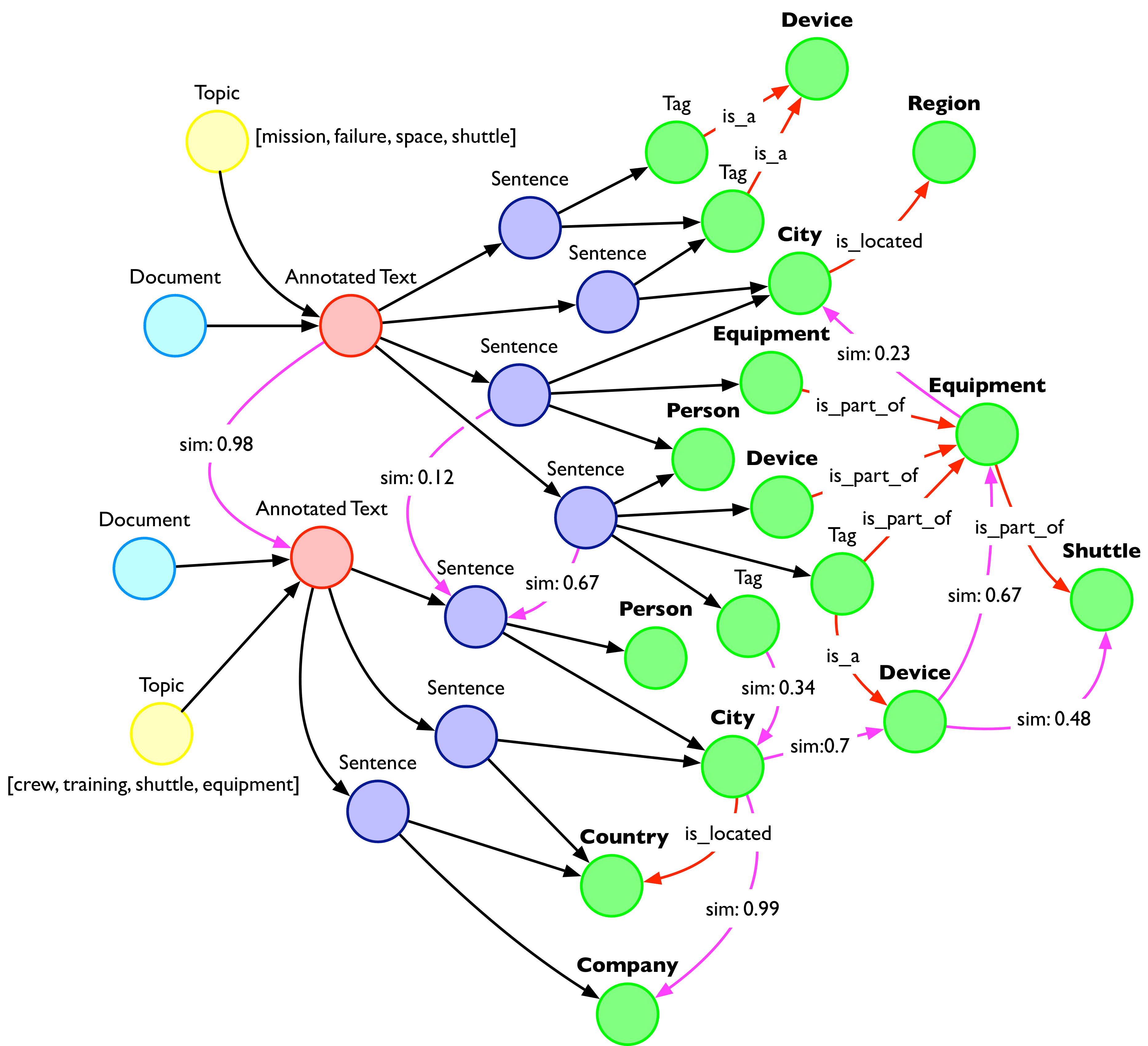
Each topic is described by a number of words since the machine cannot (yet) abstract a single word that summarises the content in the cluster.
Step 5: Caring about sentiment
It is often useful to relate a piece of text to the sentiment expressed in it. Extracting and processing sentiments from text provides a new emotional access pattern to your corpus and also new knowledge that reveals new insights.
Suppose you want to build a recommendation engine which leverages reviews to spot detailed strengths and weaknesses of different hotels (e.g. good location but bad staff).
Sentiment analysis is a difficult task, because in different contexts the same sentence can have different meanings. Many models predict sentiment based on the BoW approach, while others use a recursive deep neural network to build a representation of the complex underlying structure of sentences [4].
Hume integrates and combines multiple approaches. Users can choose from or customise a sentiment model for their specific use case. In a previous blog post, we compared the different approaches, all available in Hume, to show the advantages and disadvantages of each of them.
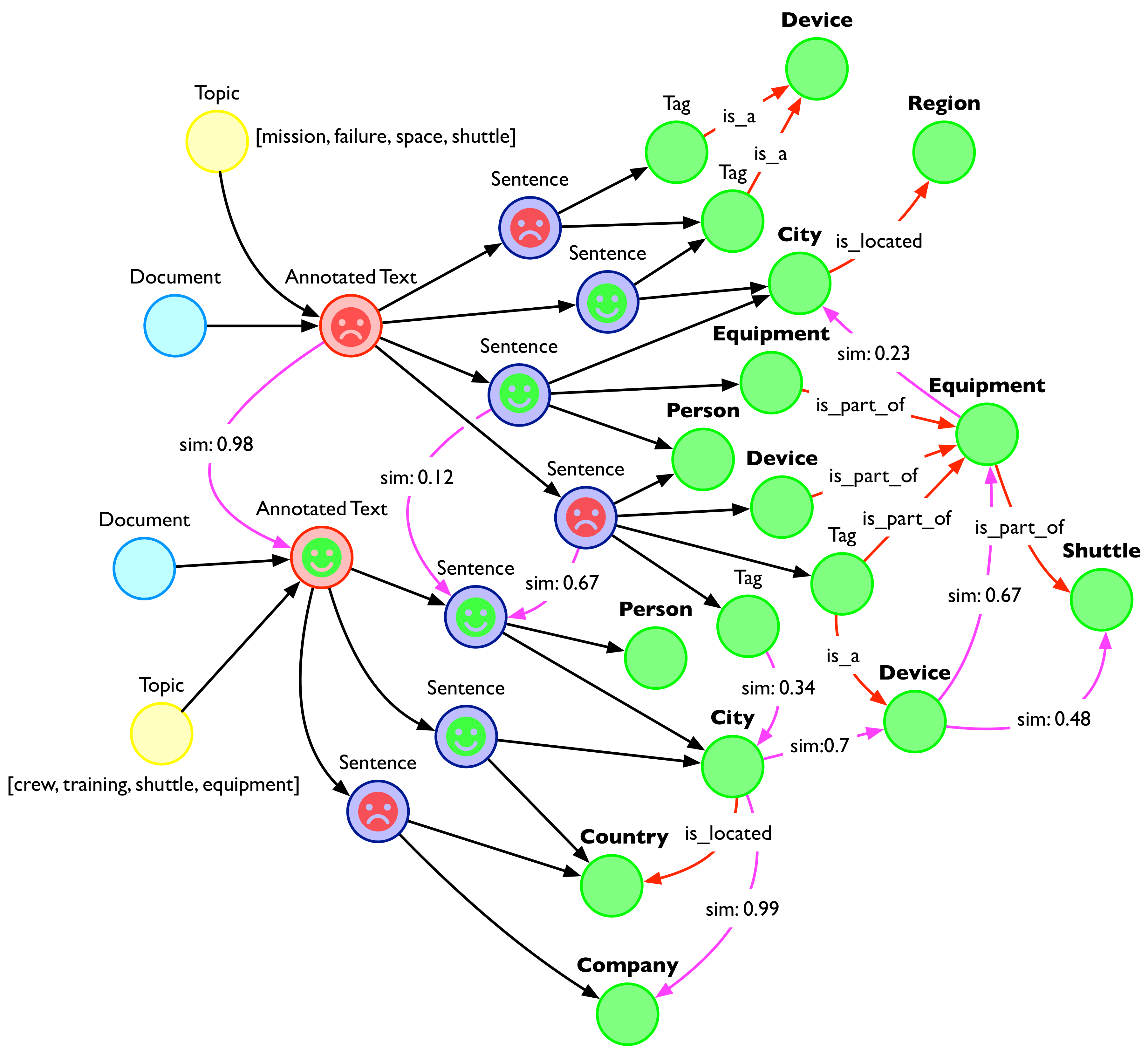
Sentiment can be computed either for the entire document or for each sentence according to the specific use case. Having such sentiment, it can be easily related to people, keywords, topics, etc.
Conclusion
The techniques, tools and the knowledge graph representation described here show how to bring order to the chaos inherent in unstructured data.
By integrating these techniques and others, Hume makes it easier for you to transform your data into actionable knowledge, which will help you realise the full value of your data, create new services, deliver better results, improve productivity and reduce costs.
Get in touch with GraphAware to see what GraphAware Hume can do for you.
Bibliography
[1] Cole Howard, Hannes Hapke, and Hobson Lane, “Natural Language Processing In Action”, Manning, 2018
[2] Tomas Mikolov, “Statistical Language Models Based on Neural Networks”. PhD thesis, PhD Thesis, Brno University of Technology, 2012.
[3] David M. Blei, “Probabilistic Topic Modeling” , Communications of the ACM, April 2012, Vol. 55 No. 4, Pages 77-84
[4] Richard Socher et al., “Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank”, Conference on Empirical Methods in Natural Language Processing (EMNLP 2013)

