
A great part of the world’s knowledge is stored using text in natural language, but using it in an effective way is still a major challenge. Natural Language Processing (NLP) techniques provide the basis for harnessing this huge amount of data and converting it into a useful source of knowledge for further processing.
Introduction
NLP is used in a wide variety of disciplines to solve many different types of problems. Analysis is performed on text from different sources, such as blogs, tweets, and various social media, with size ranging from a few words to multiple documents. Machine learning and text analysis are frequently used to enhance already existing services or to create completely new functionality. Some of the application areas could be:
- Search: This is one of the most common applications and aims at identifying specific elements in text and returning the documents that contain such elements. It can be as simple as finding the occurrence of a name in a document or might involve the use of synonyms, ontology hierarchy, alternate spelling or misspelling to find entries that are close to the original search string.
- Sentiment analysis: One of the most interesting uses of NLP and machine learning, this aims at inferring people’s feelings and attitude towards some topic like a movie, an election candidate, or a book.
- Summation: Aims at summarizing paragraphs, articles, documents, or collections of documents.
- Named Entity Recognition: Involves identifying names, locations, people, companies, dates, and things in general from the text.
- Question Answering: Aims at providing an automatic reply to queries written in natural language. This requires that the system understands the entire content of a document to find relevant information and provide the right answer to the user’s question.
Text is often referred to as unstructured data. However, in reality, free text has a lot of structure – it’s just that most of it isn’t explicit, making it difficult to search for or analyze the information within the text [1]. NLP uses computer science, artificial intelligence and formal linguistics concepts to analyze natural language, aiming at deriving meaningful and useful information from text.
In particular, Information Extraction (IE) is the first step of this process. It attempts to make the text’s semantic structure explicit so that it can be more useful. More precisely, IE is the process of analysing text and identifying mentions of semantically defined entities and relationships within it. These relationships can then be recorded in a database to search for a particular relationship or to infer additional information from the explicitly stated facts.
Note that to build a useful database, IE must do much more than to find a sentence in the text: it must identify the event’s participants and properties, resolve pronouns and compute dates and times. Once “basic” data structures like tokens, events, relationships, and references are extracted from the text provided, the information related could be extended by introducing new sources of knowledge like ontologies (ConceptNet5 [3], WordNet, DBpedia, …) or further processed/extended using services like Alchemy[4].
Due to the highly connected nature of the data produced, a suitable model for representing them is in the form of a graph using a specific database like Neo4j. It not only stores the main data and relationships extracted during IE process but allows further extension by adding new information computed in a post-processing phase, such as similarity, sentiment extraction, and so on.
With these ideas in mind, GraphAware started working on a new NLP project that integrates NLP processing capabilities available in several software packages and services like Stanford NLP and Alchemy, existing data sources, such as ConceptNet5 and WordNet, and our knowledge of Recommendation Engines. This project, called GraphAware NLP (not publicly available yet), is a continuation of our efforts to provide tools for managing textual data, which started with our full duplex integration of Neo4j and Elasticsearch.
GraphAware NLP
GraphAware NLP is developed as plugin for Neo4j and provides a set of tools, by means of procedures, background process, and APIs, that allow:
- Information Extraction (IE) – processing textual information for extracting main components and relationships
- Storing data
- Extracting sentiments and storing them as labels
- Enriching basic data with ontologies and concepts (ConceptNet 5)
- Computing similarities between text elements in a corpus using base data and ontology information
- Enriching knowledge using external sources (Alchemy)
- Providing basic search capabilities
- Providing complex search capabilities leveraging enriched knowledge like ontology, sentiments, and similarity
- Providing recommendations based on a combination of content/ontology-based recommendations, social tags, and collaborative filtering
Information Extraction
Information Extraction is the first step in the NLP process. GraphAware NLP leverages Stanford CoreNLP [5] in order to perform the following text analysis operations:
- Sentence Splitting
- Parsing
- Tokenization
- Lemmatization
- Named Entity Recognition
- Coreference Resolution
- Part Of Speech identification
- True case annotation
The plugin provides a procedure that allows processing text, using the previous steps and stores results in Neo4j. This is an example of the call to the procedure that performs the annotation process (news source is The New York Times [6]):
#Add a new node with the text (not mandatory)
CREATE (news:News {text:"Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff."}) RETURN news;
#Annotate the news
MATCH (n:News)
CALL ga.nlp.annotate({text:n.text, id: n.uuid}) YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN n, result;The process is not a simple tokenization; it tokenizes, extracts lemmas, composes tokens that need to be together (i.e. dates, person’s names or companies, locations) and could take some time due to the amount of work required.
The output of the previous calls looks like the following graph:
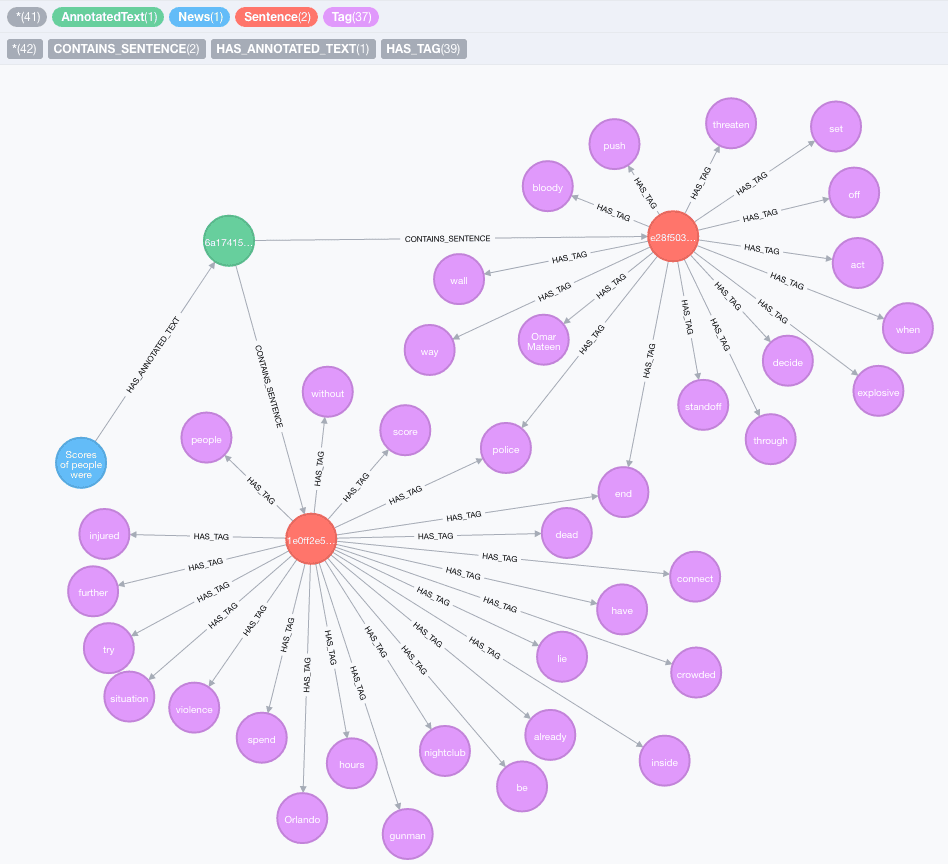
Details on Data Structure and Database
The entry point of the annotate processing procedure is a node with label AnnotatedText that contains a property, id, that is used to identify the text to avoid recomputing it multiple times. The text is decomposed into sentences, stored as nodes with label Sentence and connected with the related annotated text through a relationship of type CONTAINS_SENTENCE. Each sentence is connected to all the tags extracted with a HAS_TAG relationship, where we also store a tf property that contains the term frequency of that tag in the sentence. Each tag is stored with label Tag and contains properties like: POS (part of speech), NE (Named Entity) and Lemma (the lemma of the value of the tag). Starting from this main component, other relationships are created to identify coreference relationships between the elements in a corpus of text.
Sentiment Analysis
Sentiment analysis can be performed using two different tools: Stanford CoreNLP (using local resources) or Alchemy (using external service). The entry point for sentiment analysis could be an AnnotatedText node or plain text. The output of the analysis are 5 levels of sentiment from 0 to 4, mapped with 5 different labels one of which is assigned to the Sentence(s) related to the AnnotatedText node (created or already existing): VeryNegative, Negative, Neutral, Positive, VeryPositive.
Also, in this case, there is a procedure that allows inferring sentiment from text. This is an example of the call:
MATCH (n:News)
CALL ga.nlp.sentiment({text:n.text, id: n.uuid, processor: “stanford”})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN n, result;Or
MATCH (n:AnnotatedText {id: ed0b07b0-3677-11e6-a169-6003088ff7de})
CALL ga.nlp.sentiment({node:n, processor: “alchemy”}) YIELD result
RETURN result;These calls will label the sentence nodes with the right labels accordingly to the sentiment inferred by the text. Here an example of the output.
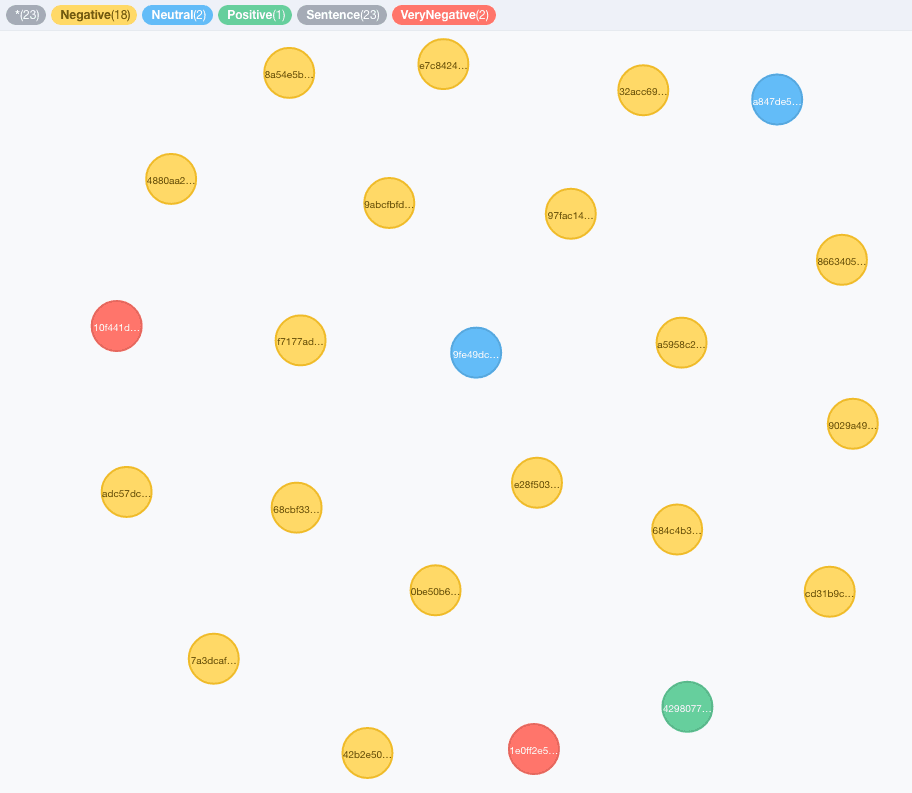
Ontology Extension
Another feature provided by GraphAware NLP is the ability to build ontology hierarchies, starting from the tags extracted from the text. The source for this ontology is ConceptNet5. It is a semantic network containing lots of things computers know about the world, especially when understanding text written by people.
The following is an example of the provided procedure:
MATCH (at:AnnotatedText) CALL ga.nlp.concept({node:at, depth: 1, admittedRelationships: [“Synonym”, “IsA”, “RelatedTo”]})
YIELD result
RETURN result;In this call, depth indicates how many levels should be explored for each node, while the admittedRelationships parameter allows filtering the explored relationships. Both of the parameters are optional, the default depth is 2 while the list of admitted relationships contains: RelatedTo, IsA, PartOf, AtLocation, Synonym, MemberOf, HasA, CausesDesire. Depending on the length of the text and the depth, the process may take long time to complete. This is an example of the output:
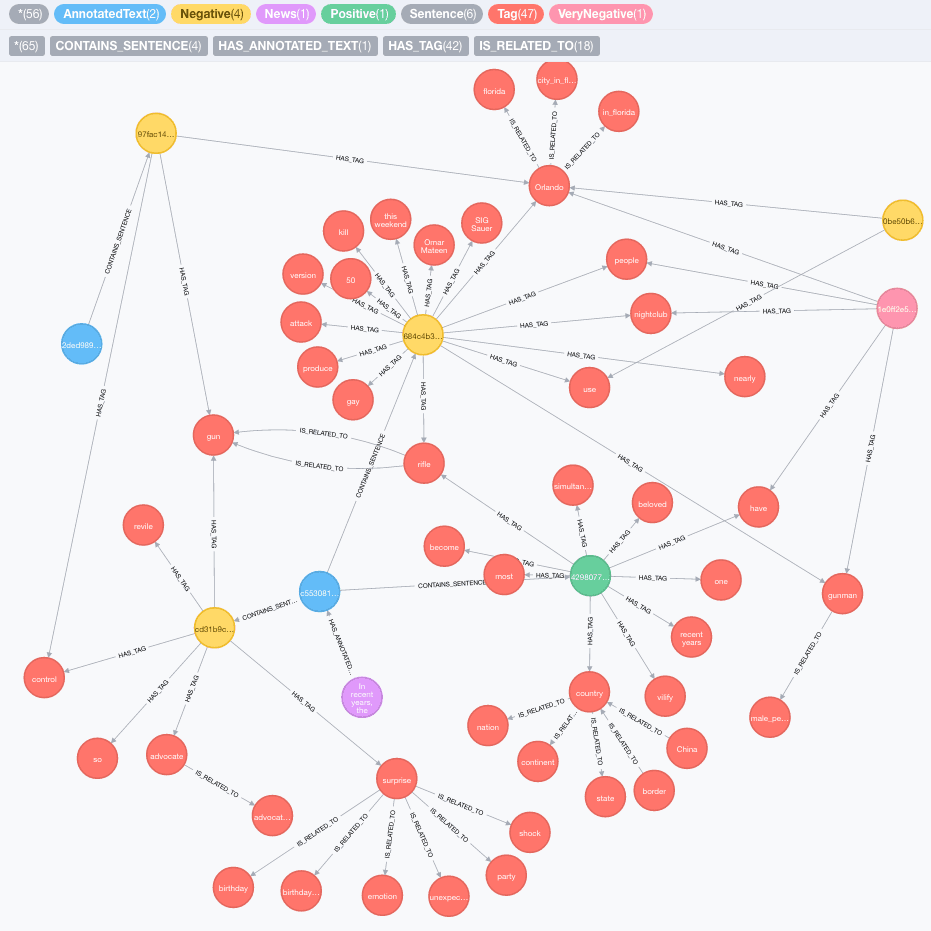
Computing Similarity
Once tags are extracted from all the news or other nodes containing some text, it is possible to compute similarities between them using content based similarity. During this process, each annotated text is described using the TF-IDF encoding format. TF-IDF is an established technique from the field of information retrieval and stands for Term Frequency-Inverse Document Frequency. Text documents can be TF-IDF encoded as vectors in a multidimensional Euclidean space. The space dimensions correspond to the tags, previously extracted from the documents. The coordinates of a given document in each dimension (i.e., for each tag) are calculated as a product of two sub-measures: term frequency and inverse document frequency.
Term frequency describes how often a certain term appears in a document (assuming that important words appear more often). To take the document length into account and to prevent longer documents from getting a higher relevance weight, some normalization of the document length should be done. Several schemes are possible; currently for simpler computation, no normalization is used for tf.
Inverse document frequency is the second measure that is combined with term frequency. It aims at reducing the weight of keywords that appear very often in all documents. The idea is that those generally frequent words are not very helpful to discriminate among documents, and more weight should therefore be given to words that appear in only a few documents. Let N be the number of all recommendable documents and n(t) be the number of documents from N in which keyword t appears. The inverse document frequency is calculated in the following way:
Idf (t) = 1 + log (N/(n(t)+1))Starting from such a vector representation, similarity between vectors is computed using cosine. The call to the procedure for computing similarity will look like this:
CALL ga.nlp.cosine.compute({}) YIELD result;The procedure computes similarity between all the annotated texts available and stores the first k similarities for each of them as relationships of type SIMILARITY_COSINE between all top k similar nodes. The result after the storing process will look like this:
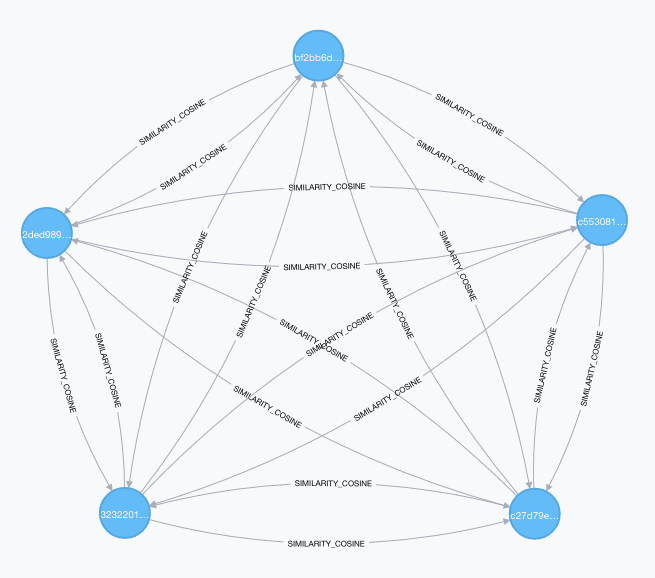
Providing Search Capabilities with Graph
Text processed during the annotation process is decomposed in all the main tags. Stop words, lemmatization, punctuation pruning and other cleaning procedures are applied to reduce the amount of tags to the most significant. Furthermore, for each tag, its term frequency is stored to provide information about how often a lemma appears in the document. Using such data and inspired by Elasticsearch scoring functions [8], GraphAware NLP exposes a search procedure that provides basic search capabilities leveraging tag information stored after text analysis.
The procedure is called in the following way:
CALL ga.nlp.search("gun Orlando") YIELD result, score
MATCH (result)<-[]-(news:News)
RETURN DISTINCT news, score
ORDER BY score desc;Internally the Cypher query looks like this:
MATCH (doc:AnnotatedText)
WITH count(doc) as documentsCount
MATCH (t:Tag)
WHERE t.value IN {searchTokens}
WITH t, documentsCount, {querySize} as queryTagsCount
MATCH (t)<-[:HAS_TAG]-(:Sentence)<-[]-(document:AnnotatedText)
WITH t, count(distinct document) as documentsCountForTag, documentsCount, queryTagsCount
MATCH (t)<-[ht:HAS_TAG]-(sentence:Sentence)<-[]-(at:AnnotatedText)
WITH DISTINCT at, t.value as value, sum(ht.tf)*(1 + log((1.0f*documentsCount)/(documentsCountForTag + 1)))* (1.0f/at.numTerms^0.5f) as sum, queryTagsCount
RETURN at, (1.0f*size(collect(value))/queryTagsCount)*(sum(sum)) as scorewhere searchTokens are the tokens obtained from the search query after text analysis. In the query above, TF and IDF is computed for each tag, and other normalization factors are computed for each document. It is worth noting that the procedure for search does not have the goal to replace Elasticsearch capabilities (Elasticsearch is already integrated with Neo4j thanks to our plugin). GraphAware NLP aims at extending basic search capabilities with a lot of new information extracted such as ontologies, similarities, sentiment and so on. These features can be combined with Elasticsearch queries to provide better custom results.
Conclusion
In this blog post, we have demonstrated that graph databases, and Neo4j in particular, can be considered a viable tool for mining and searching complex textual data. Using GraphAware NLP, it is possible to create applications that use text to deliver business value to end users.
No matter what application you are building with Neo4j, you can get in touch with GraphAware’s Neo4j experts, who will help you get the best out of the world’s most popular graph database. For latest updates on GraphAware NLP, follow us on Twitter or visit our booth at GraphConnect San Francisco!
References
[1]. Ralph Grishman, “Information Extraction” – IEEE Intelligent System, September/October 2015, pp. 8-15.
[2]. Richard M. Reese, “Natural Language Processing with Java” – Packt Publishing, 2015
[3]. ConceptNet 5, https://conceptnet5.media.mit.edu/
[4]. AlchemyAPI, https://www.alchemyapi.com/
[5]. Stanford NLP, https://nlp.stanford.edu/software/
[6]. The New York Times (on line), https://www.nytimes.com/
[7]. Jannach, D., Zanker, M., Felfernig, A., Friedrich, G., 2010. “Recommender Systems: An Introduction”. Cambridge University Press.
[8]. Elasticsearch: The Definitive Guide [2.x]: Lucene’s Practical Scoring Function, https://www.elastic.co/guide/en/elasticsearch/guide/current/practical-scoring-function.html
