
This post explores how we think about the role of AI in intelligence analysis, and how it can accelerate the work of intelligence analysts. Some of the capabilities discussed, including Document Intelligence, are currently in active development for a future GraphAware Hume release. Workspaces, referenced throughout, are available now in GraphAware Hume 3.0.
There is a moment every intelligence analyst knows. A new case opens and within days, sometimes hours, the material starts arriving. Intercepts, surveillance logs, witness statements, open-source reports, financial records, intelligence from partner agencies. Each document potentially contains the thread that connects everything together. Each one requires someone to actually read it.
In practice, no one reads all of it. Not because analysts aren’t thorough, they are, often relentlessly so, but because there simply isn’t enough time. An experienced analyst makes calculated bets about where to look first. Some documents get read in full. Others get skimmed. Some never get opened at all. And somewhere in that unread pile, occasionally, is exactly what the investigation needed.
The problem is a lack of time, rather than a lack of data. And it’s one of the most persistent pain points we hear from the analysts and teams we work with.
It’s also one of the clearest examples of where AI has a genuine role to play in intelligence work. But how that role is defined matters as much as whether it exists at all.
The role AI should play, and the role it shouldn’t
In many industries, AI is used to generate answers quickly. In intelligence analysis, that approach doesn’t hold.
Every conclusion that reaches a report, a briefing, or a courtroom needs to be defensible. It needs to be traceable to evidence and the product of human judgement exercised by someone accountable for that judgement. AI that makes decisions on the analyst’s behalf, however confidently, however accurately on average, fails to meet the standards of accountability this work requires.
We see the role of AI in intelligence analysis differently. It shouldn’t replace the analyst or their judgement. It should support the work they’re already doing, helping them move faster and with more confidence without losing control. It should read the documents the analyst hasn’t had time to read in full, surface connections they can then verify, and answer questions in a way that points the analyst directly to the source. It should accelerate their work, not replace them.
This distinction matters because it shapes everything else. The architecture of an AI capability designed to support analyst judgement is fundamentally different from the architecture of one designed to replace it. The choices look different, the safeguards look different, and the boundaries of what the system is allowed to do look different.
What changes when analysts have a space of their own
Before any of this becomes practical, analysts need somewhere to work.
GraphAware Hume started as a graph platform. It was powerful and flexible, built primarily around the data engineers and developers who configured, structured, and maintained it. Analysts used it, but in an environment fundamentally shaped by technical decisions made elsewhere.
GraphAware Hume 3.0 changes that. The centrepiece of this release is Hume Workspaces: a dedicated environment where analysts can structure and manage their own investigative work. Each Workspace is a clearly defined space to organise files, visualisations, case snapshots, and lines of enquiry, with controlled access, clear ownership, and a full audit trail of activity.
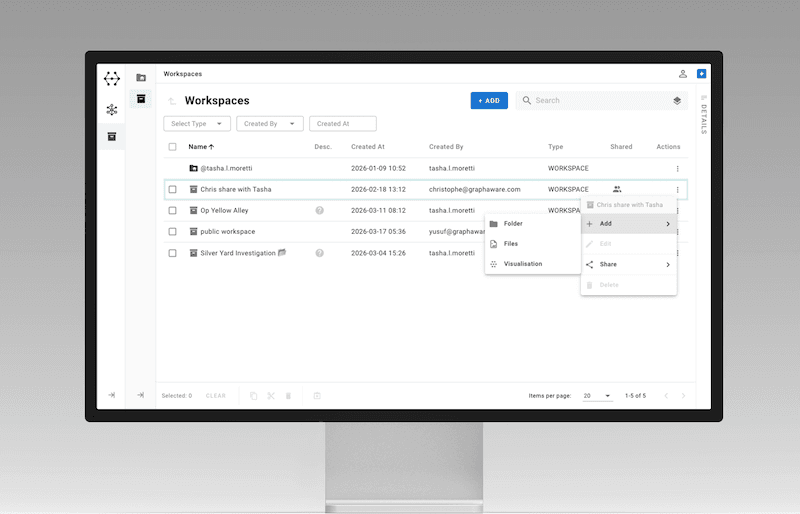
This matters because, in intelligence work, an analyst’s ability to clearly own, share, and account for their investigative output is operationally and legally significant. Workspaces give analysts that ability without requiring a data engineer to set up every case, and without the sprawl of disconnected assets that currently makes complex investigations hard to manage.
It’s also the foundation on which the next layer of capability becomes possible.
Before you can ask AI to reason over your case material, you need a structured and controlled place to put it.
The question Workspaces make possible
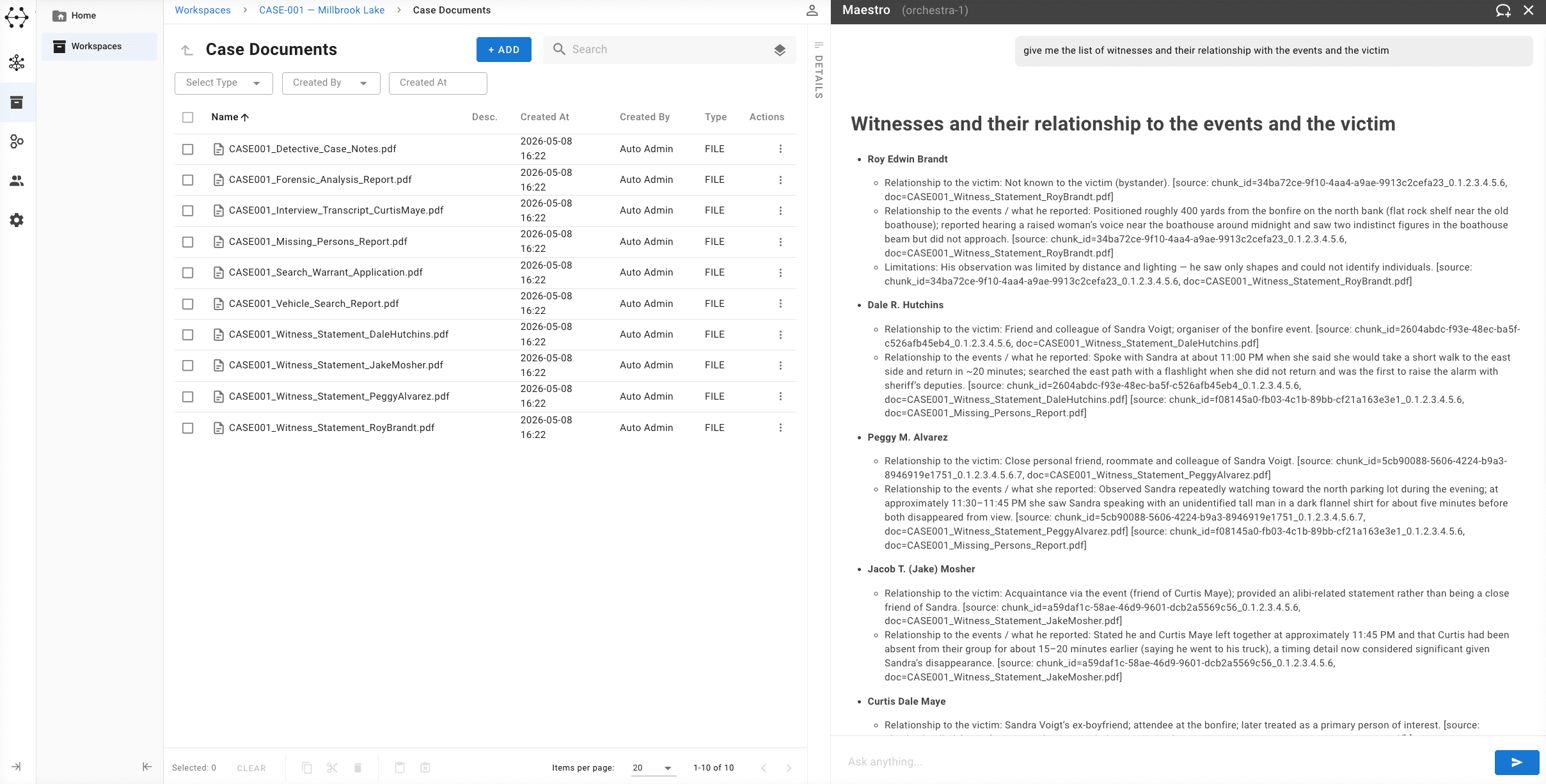
Once an analyst has uploaded their case documents into a Workspace, a natural question follows: can I ask this material something?
Not “search” in the keyword sense. I mean ask. As in, what does this collection of documents tell me about the financial relationship between these two individuals? Has anyone in these witness statements mentioned this location in a context other than their stated alibi? Across these three reports from different agencies, is there a consistent description of the vehicle involved?
These aren’t keyword searches. They’re analytical questions that require reading across documents, synthesising information, and reasoning about what is and isn’t there. Exactly the kind of questions an analyst would ask a very well-prepared colleague who had somehow read everything.
Document Intelligence in GraphAware Hume is the capability we’re building to make that possible. It’s currently in active development, and when it launches, it will allow analysts to interrogate their Workspace documents through natural language, and receive answers that are always, without exception, linked back to the specific source that supports them.
This last point is fundamental to the whole design.
Why “show your work” isn’t optional in this domain
There’s a term in AI circles, hallucination, that describes what happens when a language model produces a confident, fluent, entirely plausible-sounding answer that isn’t actually supported by the evidence. The model fills the gap between what it knows and what it was asked with something that sounds right.
In many applications, hallucination is an annoyance. In a customer service context, a wrong answer gets corrected. In an intelligence or law enforcement context, a wrong answer is a case risk. A line in a report that traces back to an AI system’s confident invention rather than a real document, and is later discovered in disclosure, does not just undermine an answer. It can undermine the entire investigation it appeared in.

This is why the most fundamental design principle for any AI capability we add to GraphAware Hume is what we call evidence linkage. It’s where every output the system produces is anchored to the specific document passage that supports it. The analyst receives the answer and the exact source passage, and they can go directly to that passage to verify it.
This isn’t, as it might sound, simply good practice we’ve decided to enforce. It needs to be structural. The system needs to be built so that it can’t surface a conclusion without surfacing the evidence that supports it. There’s no path from question to answer that bypasses the source. If the system can’t find supporting evidence in the analyst’s documents, it should say so, rather than constructing something that sounds plausible.
The distinction between an AI that reasons over verified data and an AI that generates conclusions from its own training is one I feel strongly about. It drives many of the architectural choices I will describe more fully in the next post in this series. For now, the short version is this: the AI does not produce its own truth. It helps the analyst find the truth that is already in their documents, and it shows every step of how it got there.
Two stages of an investigation, one principle
An important thing I noticed as we designed this capability, through conversations with analysts and reflection on how real investigations actually proceed, is that the value of evidence linkage varies across different stages of a case. Understanding that difference is what made us confident that this approach is genuinely useful rather than theoretically sound.
In the early stages of an investigation, breadth matters more than precision. An analyst working across 300 documents doesn’t need certainty about every detail yet. They need leads. They need to know which threads are worth pulling. They want to scan the landscape and understand which documents are relevant, what themes emerge, and what is connected to what, so they can form working hypotheses and decide where to invest their limited reading time. Speed matters here.
Being wrong about something at this stage is recoverable.
In the later stages, particularly when preparing for legal proceedings, the requirement flips entirely. Every assertion that will appear in a report or support a charge needs to be traceable to a specific source. An analyst cannot point to an AI output and say, “The system told me.” They need the document, the page, the passage. This is evidence mode, and here the AI is not a scout; it is a precision retrieval tool, and full traceability is not a nice-to-have, it’s the entire point.
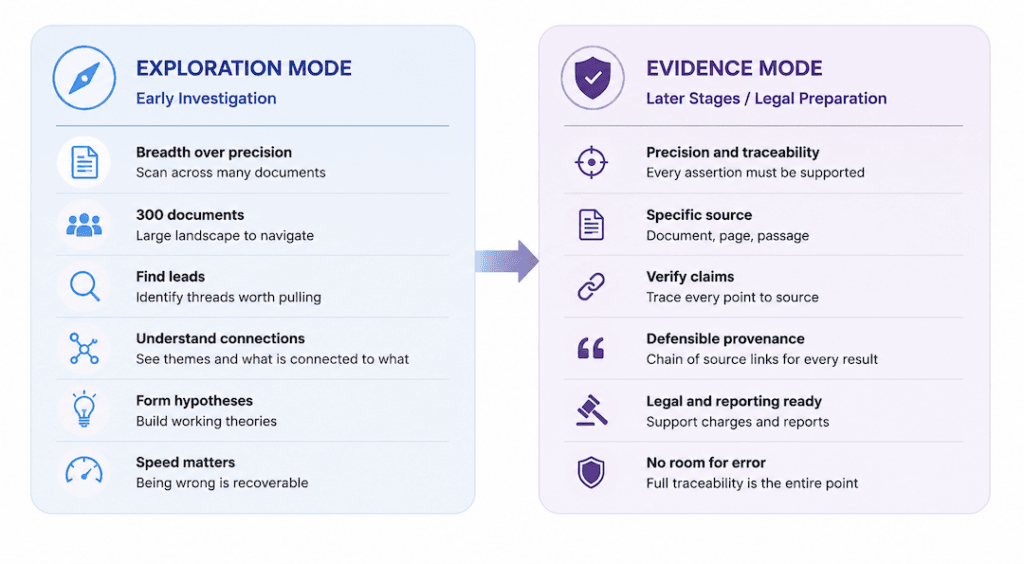
What’s striking is that the same architecture supports both modes. The analyst decides how deeply to verify. The system always makes verification possible. In exploration mode, the source links are there, but the analyst moves fast. In evidence mode, those same links become the chain of provenance that makes every result defensible.
The goal is a single tool, designed with the right foundation from the start.
The question we’re always asked: what about data sovereignty?
Every conversation I have with intelligence or law enforcement customers eventually reaches the same question, and it’s the right question: where does our data go?
The answer reflects a clear position on our part. GraphAware is not an LLM company. We do not host language models or operate them on behalf of customers. Any AI capability we build for GraphAware Hume is designed around a simple division of responsibilities, where the customer brings their own LLM, deployed in their own private cloud environment and governed by their own policies. The customer’s data stays in the customer’s environment. Nothing reaches GraphAware. Nothing reaches a shared public cloud service.
Some vendors treat this as a limitation. We treat it as a precondition. For several years, the honest answer to “can we use LLMs on sensitive operational data?” was “not yet”. The barrier was sovereignty. Private cloud LLM deployments resolved it. The AI capability we are building is not a compromise between capability and security. It’s both, fully, because the architecture is being designed around the constraint rather than in spite of it.
It also means the customer remains in control of the model itself. Which model they choose, how it’s configured, when it’s updated, and what it’s permitted to do.
A consistent direction
Document Intelligence is one layer in an AI strategy for GraphAware Hume that we’ve been developing over the past several years. Our strategy is grounded in a clear and important principle: AI in intelligence analysis should act as a co-pilot that makes analysts faster, more confident, and better informed. It should never replace their judgement, produce conclusions they cannot verify, or operate in ways they cannot understand.
The graph has always been GraphAware Hume’s foundation — a connected view of intelligence built from data that would otherwise be siloed. Document Intelligence will sit alongside it, applying the same rigour and the same transparency to the unstructured case material that the graph alone isn’t designed to address. The two work together. Neither is a replacement for the other, nor is either a replacement for the analyst.
GraphAware Hume 3.0 is built around a clear priority: putting analysts in control of their analysis. Workspaces give analysts the structural environment to own their work. Document Intelligence will enable them to question it. Together, they will make GraphAware Hume a genuinely analyst-centric intelligence analysis platform.
In the next post in this series, I’ll look at the architectural choices that shape how Document Intelligence is being built, and why the approach many AI vendors default to runs into problems in high-stakes professional contexts. Not to dismiss those approaches, but because understanding the trade-offs is what allows teams to make genuinely informed decisions about the tools they adopt.
GraphAware Hume is a graph-powered intelligence analysis platform used by law enforcement and intelligence agencies. Document Intelligence is currently in active development. If you would like to follow the progress of this work or discuss how it applies to your organisation’s needs, get in touch.
