
Introduction to Graph Databases
In today’s data-driven world, the relationships between big data points are often as valuable as the data itself. Traditional databases excel at storing and retrieving structured information, but they struggle when it comes to understanding and leveraging the complex connections that exist between different pieces of data. This is where graph databases emerge as a powerful solution, revolutionizing how we store, query, and analyze interconnected information.
A graph database is a specialized database management system that uses graph structures with nodes, edges, and properties to represent and store data. Unlike traditional relational databases that organize data in tables with rows and columns, graph databases model data as networks of relationships, making it intuitive to work with connected information. The core components of a graph database include nodes (which represent entities like people, places, or things), relationships (which define how nodes are connected), and properties (which store additional information about both nodes and relationships).
The importance of graph-based databases lies in their ability to treat relationships as first-class citizens in the data model. While relational databases require complex joins to traverse relationships, graph databases can follow connections directly, making queries about connected data significantly faster and more intuitive. This approach is particularly valuable in scenarios where understanding the relationships between entities is crucial for deriving insights or making decisions.
The rise of graph databases can be traced back to the early 2000s, but their popularity has surged dramatically in recent years. This growth is driven by the explosion of connected data from social networks, the Internet of Things (IoT), recommendation systems, and the increasing need for real-time analytics on complex relationships. Companies like Facebook, LinkedIn, Google, and Amazon have pioneered the use of graph databases to power their core services, demonstrating the technology’s potential at massive scale.
Graph Databases vs. Relational Databases
Understanding the fundamental differences between graph databases and relational databases is crucial for making informed decisions about data architecture. While both serve the purpose of storing and managing data, their approaches and strengths vary significantly.
The most significant difference lies in their data models. Relational databases organize data in tables with predefined schemas, where relationships are established through foreign keys and must be explicitly defined through joins. In contrast, graph based databases store data as nodes and relationships, where connections are explicit and can be traversed directly without complex join operations. This fundamental difference makes graph databases naturally suited for scenarios involving complex, interconnected data.
Schema flexibility represents another key distinction. Relational databases typically require rigid schemas that must be defined upfront and are difficult to modify once data is stored. Graph databases offer much greater flexibility, allowing for schema evolution and the addition of new node types, relationship types, and properties without disrupting existing data or requiring extensive database migrations.
When it comes to query performance, the differences become particularly pronounced when dealing with connected data. Relational databases struggle with queries that require multiple joins across several tables, especially as the number of relationships increases. Graph databases excel in these scenarios, as they can traverse relationships in constant time, regardless of the overall database size. For example, finding friends-of-friends in a social network might require complex recursive joins in SQL but can be accomplished with a simple graph traversal in a graph database.
Graph databases are ideal when your use case involves highly connected data, such as social networks, recommendation engines, fraud detection systems, or knowledge graphs. They’re particularly valuable when you need to perform queries like “find all paths between two entities,” “identify clusters or communities,” or “recommend items based on similar user behavior patterns.” The ability to perform these operations efficiently makes graph databases indispensable for many modern applications.
However, relational databases remain the better choice for scenarios involving structured, tabular data with well-defined relationships and heavy transactional workloads. They excel at handling large volumes of structured data, complex aggregations, and scenarios where ACID compliance is critical. Applications like financial systems, inventory management, and traditional business applications often benefit more from relational database architectures.
Performance comparisons between the two technologies depend heavily on the specific use case. While relational databases can handle simple queries and aggregations very efficiently, graph databases demonstrate superior performance for relationship-heavy queries. Benchmarks consistently show that graph databases outperform relational databases by orders of magnitude when traversing multiple levels of relationships, making them the clear choice for connected data scenarios.
Understanding the Graph Data Model
The graph data model provides an intuitive and flexible way to represent complex, interconnected data. To fully leverage the power of graph databases, it’s essential to understand the fundamental components and concepts that make up this model.
Nodes serve as the primary entities in a graph database, representing real-world objects, concepts, or entities. Each node can have multiple labels that categorize it (such as “Person,” “Product,” or “Location”) and can store properties as key-value pairs containing additional information about the entity. For example, a Person node might have properties like name, age, email, and occupation. The flexibility of nodes allows for rich data representation without the constraints of fixed table schemas.
Relationships define the connections between nodes and are equally important as the nodes themselves. Each relationship has a type (such as “FRIENDS_WITH,” “PURCHASED,” or “LOCATED_IN”), a direction (from one node to another), and can also contain properties that describe the nature or characteristics of the connection. For instance, a “PURCHASED” relationship might include properties like purchase_date, quantity, and price. The directional nature of relationships allows for modeling complex scenarios while maintaining semantic clarity.
The Labeled Property Graph Model is the most widely adopted graph data model, used by popular graph databases like Neo4j, Amazon Neptune, and TigerGraph. In this model, both nodes and relationships can have labels and properties, providing a rich and expressive way to model complex domains. Labels act as types or categories, while properties store the actual data. This model strikes an excellent balance between flexibility and structure, allowing for both schema-free development and the ability to enforce constraints when needed.
The RDF (Resource Description Framework) Triples model represents an alternative approach used primarily in semantic web applications and knowledge graphs. RDF organizes data as subject-predicate-object triples, where the subject and object are resources (similar to nodes) and the predicate defines the relationship between them. While more rigid than the labeled property graph model, RDF triples provide excellent support for reasoning and inference, making them particularly valuable for knowledge representation and semantic applications.
Understanding these fundamental concepts is crucial for effective graph database design and implementation. The choice between different graph models often depends on the specific requirements of your application, the need for semantic reasoning, and the tools and technologies you plan to use in your graph database ecosystem.
Real-World Use Cases of Graph Databases
Graph databases have found applications across numerous industries and use cases, demonstrating their versatility and power in handling connected data scenarios. Understanding these real-world applications helps illustrate the practical value and potential of graph database technology.
Social Networks represent perhaps the most intuitive application of graph databases. Platforms like Facebook, LinkedIn, and Twitter use graph databases to model user relationships, enabling features like friend recommendations, network analysis, and social graph exploration. The ability to efficiently query multi-degree connections (friends of friends of friends) and identify influential users or communities makes graph databases essential for social media platforms. These systems can quickly answer questions like “How are two users connected?” or “Find mutual connections between users.”
Recommendation Engines leverage graph databases to provide personalized recommendations by analyzing user behavior patterns, product relationships, and collaborative filtering data. E-commerce giants like Amazon and streaming services like Netflix use graph databases to understand customer preferences and suggest relevant products or content. By modeling users, items, and their interactions as a graph, these systems can identify similar users, related products, and emerging trends to deliver highly targeted recommendations.
Fraud Detection systems benefit enormously from graph databases’ ability to identify suspicious patterns and connections across large datasets. Financial institutions use graph databases to detect money laundering, credit card fraud, and other financial crimes by analyzing transaction networks and identifying unusual patterns. The ability to quickly traverse relationships and identify rings of fraudulent activity makes graph databases invaluable for real-time fraud prevention.
Knowledge Graphs have become increasingly important for organizations seeking to organize and leverage their institutional knowledge. Companies like Google, Microsoft, and IBM use knowledge graphs to power search engines, virtual assistants, and AI applications. These systems model entities, concepts, and their relationships to enable semantic search, question answering, and knowledge discovery. Knowledge graphs help organizations break down data silos and create unified views of their information assets.
Supply Chain Management applications use graph databases and link analysis to optimize logistics, track products through complex supply networks, and identify potential disruptions. The ability to model suppliers, manufacturers, distributors, and customers as a connected network enables better visibility, risk assessment, and optimization opportunities. Graph databases can quickly identify alternative suppliers, assess the impact of disruptions, and optimize routing and inventory decisions.
Master Data Management (MDM) represents an area where graph databases have generated significant interest, though the reality often differs from the hype. While graph databases can effectively model entity relationships and help identify duplicate records, implementing comprehensive MDM solutions requires careful consideration of data governance, quality processes, and integration challenges. Success in MDM with graph databases requires more than just technology—it demands well-designed processes and organizational commitment to data quality.
Cybersecurity applications leverage graph databases to analyze network traffic, identify attack patterns, and understand the relationships between different security events. Security teams can model networks, devices, users, and threats as graphs to detect advanced persistent threats, analyze attack paths, and respond to incidents more effectively. The ability to correlate events across time and systems makes graph databases powerful tools for security analytics.
Several organizations have achieved remarkable success with graph database implementations. For example, Walmart uses graph databases for real-time recommendation engines that have significantly improved customer engagement and sales. NASA leverages graph databases to model complex relationships in space mission data, enabling better decision-making and risk assessment. These case studies demonstrate the tangible business value that well-implemented graph database solutions can deliver.
Choosing the Right Graph Database
Selecting the appropriate graph database for your specific needs requires careful consideration of various factors, including technical requirements, scalability needs, query language preferences, and organizational constraints. The graph database landscape offers numerous options, each with distinct strengths and use case focus areas.
Understanding the distinction between native and multi-model graph databases is crucial for making informed decisions. Native graph databases are built specifically for graph workloads, with storage and processing engines optimized for graph operations. Multi-model databases support graph functionality alongside other data models like document or key-value storage. While native graph databases typically offer better performance for graph-specific operations, multi-model databases provide flexibility for organizations with diverse data storage needs.
Neo4j stands as the most popular native graph database, offering robust features, excellent documentation, and strong community support. Its Cypher query language provides an intuitive, SQL-like syntax for graph operations. Neo4j excels in scenarios requiring complex graph analytics, real-time recommendations, and knowledge graph applications. However, it can be expensive for large-scale deployments, and its horizontal scaling capabilities are limited compared to some alternatives. Neo4j is particularly well-suited for organizations prioritizing ease of use and comprehensive graph analytics capabilities.
Amazon Neptune offers a fully managed graph database service that supports both property graph and RDF data models. Neptune provides excellent integration with other AWS services and offers good scalability and reliability. It supports multiple query languages, including Gremlin and SPARQL, making it versatile for different use cases. Neptune is ideal for organizations already invested in the AWS ecosystem and those requiring managed database services. However, vendor lock-in and potentially high costs for large datasets are considerations to evaluate.
TigerGraph focuses on high-performance analytics and real-time graph processing, offering superior scalability and performance for large-scale graph analytics workloads. Its GSQL query language provides powerful capabilities for complex graph algorithms and analytics. TigerGraph excels in scenarios requiring real-time fraud detection, recommendation engines at scale, and complex graph analytics. The platform is particularly suitable for organizations with large datasets and demanding performance requirements, though it may have a steeper learning curve than some alternatives.
ArangoDB represents a multi-model approach, supporting graph, document, and key-value data models within a single database system. Its AQL (ArangoDB Query Language) provides unified access to different data models, making it attractive for organizations with diverse data storage needs. ArangoDB offers good performance, horizontal scaling capabilities, and flexibility in data modeling. It’s well-suited for organizations requiring multiple data models and those seeking to consolidate their database infrastructure.
Memgraph focuses on real-time graph analytics and streaming data processing, offering in-memory storage for high-performance applications. It provides compatibility with Neo4j’s Cypher query language while delivering superior performance for real-time use cases. Memgraph is particularly valuable for applications requiring low-latency graph queries and real-time analytics, such as fraud detection and recommendation systems.
The open-source graph database ecosystem offers several compelling options for organizations seeking cost-effective solutions or those requiring extensive customization. Neo4j Community Edition, Apache TinkerPop, JanusGraph, and ArangoDB Community Edition provide robust graph database capabilities without licensing costs. These options are particularly attractive for startups, research institutions, and organizations with strong technical teams capable of managing database infrastructure.
When evaluating graph database options, consider factors such as scalability requirements (both horizontal and vertical scaling needs), performance characteristics (query latency, throughput, and concurrent user support), query language preferences (Cypher, Gremlin, SPARQL, or proprietary languages), integration requirements (with existing systems and tools), support and community (availability of documentation, tutorials, and professional support), and total cost of ownership (including licensing, infrastructure, and operational costs).
Graph Query Languages
Graph query languages provide the interface for interacting with graph databases, enabling users to create, read, update, and delete graph data. Understanding the various query languages available and their strengths is essential for effective graph database utilization.
Cypher, developed by Neo4j, has become one of the most popular and intuitive graph query languages. Its ASCII-art syntax makes it easy to visualize graph patterns, with nodes represented in parentheses and relationships shown with arrows. For example, the pattern (person:Person)-[:FRIENDS_WITH]->(friend:Person) clearly represents a friendship relationship between two people. Cypher’s declarative approach allows users to specify what they want to retrieve without worrying about how the database executes the query, making it accessible to both technical and non-technical users.
Gremlin, part of the Apache TinkerPop project, provides a functional, step-based approach to graph traversal. Rather than declaring patterns like Cypher, Gremlin queries are built as a series of traversal steps that navigate through the graph. This imperative style gives users fine-grained control over query execution but can result in more verbose queries. Gremlin’s strength lies in its flexibility and the fact that it works across multiple graph database implementations, making it valuable for organizations using diverse graph technologies.
SPARQL(SPARQL Protocol and RDF Query Language) serves as the standard query language for RDF data and semantic web applications. SPARQL queries work with RDF triples and provide powerful capabilities for reasoning and inference over semantic data. While more complex than property graph query languages, SPARQL excels in scenarios requiring semantic reasoning, ontology-based queries, and integration with linked data sources.
GSQL, TigerGraph’s proprietary query language, focuses on high-performance graph analytics and provides built-in support for complex graph algorithms. GSQL allows users to define reusable query patterns and supports both real-time queries and batch analytics workloads. Its strength lies in handling large-scale graph analytics efficiently, though its proprietary nature means vendor lock-in considerations.
GQL (Graph Query Language)represents an emerging international standard for graph database queries, developed by ISO/IEC. GQL aims to provide a standardized approach to graph querying, similar to how SQL standardized relational database queries. While still in development, GQL promises to bring consistency across different graph database implementations and reduce the learning curve for developers working with multiple graph technologies.
Practical query examples help illustrate the differences between these languages. Finding mutual friends in Cypher might look like: MATCH (user:Person {name: 'Alice'})-[:FRIENDS_WITH]-(mutualFriend)-[:FRIENDS_WITH]-(friend:Person {name: 'Bob'}) RETURN mutualFriend. The same query in Gremlin would be: g.V().has('Person', 'name', 'Alice').both('FRIENDS_WITH').where(both('FRIENDS_WITH').has('name', 'Bob')). These examples demonstrate how different languages approach the same problem with varying syntax and conceptual models.
Data Modeling Best Practices
Effective graph data modeling is crucial for building performant and maintainable graph database applications. Unlike relational databases with their normalized table structures, graph databases require a different approach to data modeling that emphasizes relationships and connectivity patterns.
Identifying nodes and relationships represents the foundational step in graph data modeling. Nodes should represent distinct entities or concepts in your domain, while relationships should capture meaningful connections between these entities. A common mistake is creating too many node types or failing to properly identify the most important relationships. Start by identifying the core entities in your domain and the primary ways they connect, then gradually add complexity as your understanding of the domain deepens.
When defining properties, focus on attributes that are intrinsic to nodes or relationships rather than trying to normalize data as you would in a relational model. Graph databases benefit from denormalization, so it’s often better to duplicate some data to improve query performance. However, be mindful of properties that change frequently, as updates can be more expensive than in relational databases. Consider which properties you’ll need for filtering, sorting, or aggregation operations, as these will benefit from indexing.
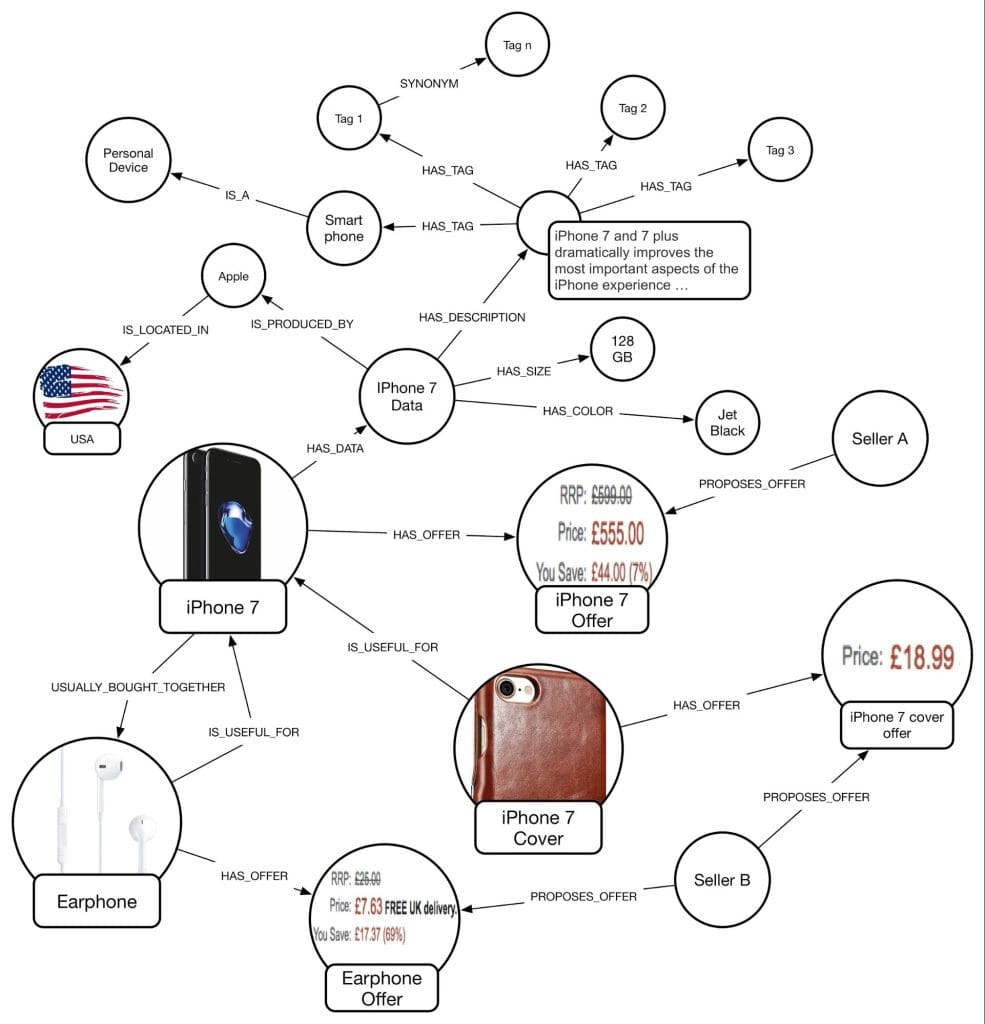
Schema management in graph databases requires a balance between flexibility and structure. While graph databases allow for schema evolution, it’s important to establish conventions and patterns early in your project. Consider using consistent naming conventions for node labels, relationship types, and properties. Implement validation rules where appropriate, and plan for schema migration strategies as your application evolves. Document your graph schema thoroughly, as the flexibility of graph databases can lead to confusion without proper documentation.
Practical examples of graph data models help illustrate these concepts. For an e-commerce application, you might model customers, products, orders, and categories as nodes, with relationships like PURCHASED, BELONGS_TO_CATEGORY, and SIMILAR_TO. A social media application might focus on users, posts, and topics, with relationships like FOLLOWS, POSTED, LIKED, and TAGGED_IN. The key is to model your graph based on the queries you need to perform rather than trying to directly translate relational database designs.
Consider the query patterns your application will need to support when designing your graph model. If you frequently need to find products purchased by friends of a user, ensure that user-to-user and user-to-product relationships are efficiently modeled. If you need to perform recommendation algorithms, consider adding relationship properties that capture interaction strength or recency. The graph model should make your most common and important queries as efficient as possible.
Graph Database Performance Optimization
Optimizing graph database performance requires understanding both the unique characteristics of graph workloads and the specific implementation details of your chosen database system. Performance optimization in graph databases involves several key areas that differ significantly from traditional relational database optimization.
Indexing strategies in graph databases focus on accelerating node and relationship lookups rather than traditional table scans. Most graph databases automatically index node labels and relationship types, but you’ll need to create explicit indexes on properties used in WHERE clauses, ORDER BY statements, or as starting points for graph traversals. Consider creating composite indexes for queries that filter on multiple properties simultaneously. However, be mindful that excessive indexing can slow down write operations and consume significant storage space.
Query optimization techniques for graph databases often involve understanding how the query planner works and structuring queries to minimize unnecessary traversals. Start queries from the most selective nodes (those with the highest filtering criteria) to reduce the search space early. Use EXPLAIN or PROFILE commands to understand query execution plans and identify bottlenecks. Avoid Cartesian products by ensuring all parts of your query pattern are connected, and consider breaking complex queries into smaller, more focused operations.
Data partitioning strategies become crucial as graph databases scale beyond single-machine capabilities. Unlike relational databases where horizontal partitioning is well-established, graph partitioning presents unique challenges due to the interconnected nature of graph data. Consider partitioning strategies based on graph topology, such as clustering highly connected nodes together, or use application-specific partitioning based on tenant isolation or geographical boundaries. Some graph databases offer automatic sharding capabilities, while others require manual partition management.
Monitoring and tuning graph database performance requires attention to metrics specific to graph workloads. Monitor query latency, especially for traversal-heavy operations that might degrade as the graph grows. Track memory usage carefully, as many graph databases rely heavily on caching for performance. Monitor the distribution of node degrees (number of relationships per node) to identify potential hotspots or supernodes that might cause performance issues. Implement alerting for unusual query patterns or performance degradation.
Consider implementing caching strategies for frequently accessed subgraphs or query results. Many applications benefit from application-level caching of common traversal results, especially for read-heavy workloads. However, be careful to invalidate caches appropriately when underlying data changes. Some graph databases offer built-in caching mechanisms that can significantly improve performance for repetitive queries.
Graph Algorithms
Graph algorithms represent one of the most powerful aspects of graph database technology, enabling sophisticated analysis and insights that would be difficult or impossible to achieve with traditional database systems. Understanding and leveraging these algorithms can unlock significant value from your graph data.
PageRank algorithm, originally developed by Google for ranking web pages, calculates the importance or influence of nodes within a graph based on the quantity and quality of their incoming relationships. In graph databases, PageRank can identify influential users in social networks, important products in recommendation systems, or critical components in network infrastructure. The algorithm works by iteratively distributing “importance scores” through the graph until convergence is reached, providing a relative ranking of all nodes.
Shortest path algorithms find the most efficient route between two nodes, considering various factors such as relationship weights, types, or constraints. These algorithms are essential for applications like route optimization, network analysis, and social network analysis. Variants include unweighted shortest path (finding the path with the fewest hops), weighted shortest path (considering relationship weights), and all-pairs shortest path (finding shortest paths between all node pairs). Applications range from GPS navigation systems to supply chain optimization.
Community detection algorithms identify clusters or groups of highly connected nodes within larger graphs. These algorithms help uncover natural groupings in data, such as friend groups in social networks, customer segments in e-commerce, or functional modules in biological networks. Popular community detection algorithms include Louvain modularity, Label Propagation, and Connected Components. The insights from community detection can inform marketing strategies, product recommendations, and organizational analysis.
Centrality measures provide different perspectives on node importance within a graph. Degree centrality measures the number of direct connections a node has, while betweenness centrality identifies nodes that frequently appear on shortest paths between other nodes. Closeness centrality measures how quickly a node can reach all other nodes in the graph. Each centrality measure reveals different aspects of node importance and can be valuable for different applications, from identifying key influencers to finding critical infrastructure components.
Real-world applications of graph algorithms demonstrate their practical value across industries. Financial institutions use community detection to identify money laundering networks and fraud rings. Social media platforms employ PageRank and centrality measures to identify influential users and optimize content distribution. Supply chain companies use shortest path algorithms to optimize logistics and identify alternative routes during disruptions. Telecommunications companies leverage centrality measures to identify critical network nodes and plan infrastructure investments.
Many modern graph databases provide built-in implementations of common graph algorithms, making them accessible without requiring deep algorithmic expertise. However, understanding the principles behind these algorithms helps in selecting appropriate algorithms for specific use cases and interpreting their results correctly. Consider the computational complexity of different algorithms, especially when working with large graphs, and evaluate whether approximate algorithms might provide sufficient accuracy with better performance.
Emerging Trends in Graph Databases
The graph database landscape continues to evolve rapidly, driven by advances in machine learning, cloud computing, and the growing recognition of connected data’s value. Understanding these emerging trends helps organizations prepare for the future and identify new opportunities for leveraging graph database technology.
Graph Machine Learning represents one of the most exciting developments in the graph database space. This field combines the relationship-rich nature of graph data with machine learning techniques to create more accurate and insightful models. Graph Neural Networks (GNNs) can learn from both node features and graph topology to make predictions about nodes, relationships, or entire graphs. Applications include fraud detection systems that consider both transaction patterns and network effects, recommendation engines that leverage social influence, and drug discovery platforms that model molecular interactions.
The integration of graph databases with machine learning workflows is becoming increasingly seamless, with many graph database vendors providing native support for ML operations. This includes features like automated feature engineering from graph topology, built-in support for popular ML frameworks, and specialized hardware optimization for graph ML workloads. Organizations are beginning to realize that the combination of graph databases and machine learning can provide competitive advantages that neither technology could achieve alone.
Knowledge Graph Advancements continue to drive innovation in how organizations capture, organize, and leverage their institutional knowledge. Modern knowledge graphs are becoming more sophisticated, incorporating automated knowledge extraction from unstructured data, real-time updates from multiple data sources, and advanced reasoning capabilities. The integration of natural language processing with knowledge graphs enables more intuitive querying and interaction, making these systems accessible to business users without technical expertise.
Enterprise knowledge graphs are evolving beyond simple entity-relationship models to include temporal information, uncertainty measures, and provenance tracking. This evolution enables more nuanced reasoning and decision-making, particularly in domains like healthcare, finance, and scientific research where accuracy and traceability are critical. The rise of conversational AI and chatbots is also driving demand for knowledge graphs that can support natural language understanding and generation.
GQL Adoption represents a significant step toward standardization in the graph database industry. As GQL development progresses through international standards bodies, we can expect to see increased adoption across different graph database implementations. This standardization will reduce vendor lock-in, improve developer productivity, and enable better tooling and integration across the graph database ecosystem. Organizations should monitor GQL development and consider how standardization might impact their graph database strategies.
The emergence of GQL also signals the maturation of the graph database market, similar to how SQL standardization helped establish relational databases as a mainstream technology. This standardization is likely to accelerate graph database adoption in enterprise environments where standards compliance and long-term technology sustainability are important considerations.
Graph Database as a Service offerings are becoming more sophisticated and widely available, reducing the barriers to graph database adoption. Cloud providers are investing heavily in managed graph database services that handle infrastructure management, scaling, backup, and security. These services enable organizations to focus on application development and data modeling rather than database administration, accelerating time-to-value for graph database projects.
The evolution toward serverless and auto-scaling graph database services promises to make graph technology even more accessible to smaller organizations and development teams. Pay-per-use pricing models and automatic scaling capabilities reduce the financial and operational risks associated with graph database adoption, potentially leading to broader market penetration.
Additional trends worth monitoring include the integration of graph databases with streaming data platforms for real-time graph updates, the development of quantum-inspired graph algorithms for solving complex optimization problems, and the emergence of specialized graph hardware that can accelerate graph computations. These developments suggest that graph databases will continue to evolve and find new applications across diverse industries and use cases.
Conclusion
Graph databases have emerged as a transformative technology for organizations seeking to unlock the value hidden within their connected data. Throughout this comprehensive exploration, we’ve seen how graph databases excel in scenarios where relationships between data points are as important as the data itself, offering superior performance and intuitive modeling for connected data use cases.
The key takeaways from our analysis highlight several critical points for organizations considering graph database adoption. First, graph databases provide significant advantages over traditional relational databases when dealing with highly connected data, complex relationship queries, and scenarios requiring flexible schema evolution. Their ability to treat relationships as first-class citizens enables more natural data modeling and dramatically improved query performance for traversal-heavy operations.
The diverse range of real-world applications—from social networks and recommendation engines to fraud detection and knowledge graphs—demonstrates the versatility and practical value of graph database technology. Organizations across industries have successfully leveraged graph databases to solve complex business problems, improve customer experiences, and gain competitive advantages through better understanding of their connected data.
Choosing the right graph database requires careful consideration of factors including scalability requirements, query language preferences, integration needs, and total cost of ownership. The landscape offers robust options ranging from native graph databases like Neo4j and TigerGraph to cloud-managed services like Amazon Neptune, each with distinct strengths for different use cases and organizational contexts.
The importance of proper data modeling, performance optimization, and leveraging graph algorithms cannot be overstated. Success with graph databases requires understanding their unique characteristics and designing solutions that take advantage of their strengths while mitigating potential limitations. Organizations must invest in developing graph database expertise and establishing best practices for data modeling, query optimization, and system maintenance.
Looking toward the future, emerging trends in graph machine learning, knowledge graph advancement, query language standardization, and cloud-native services promise to make graph databases even more powerful and accessible. Organizations that begin building graph database capabilities now will be well-positioned to leverage these advancing technologies and gain competitive advantages from their connected data assets.
For organizations ready to explore graph databases further, the recommended next steps include conducting a thorough assessment of your connected data use cases, evaluating different graph database options through proof-of-concept projects, and investing in team education and training. Start with a focused use case that demonstrates clear value, build expertise gradually, and scale your graph database initiatives as your organization gains experience and confidence with the technology.
The future belongs to organizations that can effectively leverage the relationships within their data. Graph databases provide the foundation for this capability, offering the tools and techniques necessary to transform connected data into actionable insights and competitive advantages. The time to begin your graph database journey is now—the technology is mature, the tools are robust, and the potential for transformative business impact has never been greater.