
Organisations are drowning in information yet starved of insights. The problem is an inability to connect, integrate, and make sense of disparate data sources scattered across systems, departments, and organisations.
Enter linked data, an approach that transforms isolated data silos into interconnected knowledge networks, enabling higher levels of data discovery, integration, and intelligence.
What do we mean by linked data?
Before diving into the intricacies of linked data, it’s essential to establish a solid foundation by understanding what data means in our modern context and how linked data revolutionises traditional data management approaches.
But first, we need to understand a more fundamental topic.
What is Data?
Data is the collection of facts, observations, measurements, or descriptions that can be processed and analysed to produce useful information.
In its raw form, data appears as individual elements such as numbers, text, images, or multimedia. When this information is organised, structured, and placed in context, it becomes a valuable asset that organisations can use to make better decisions.
Types of data
Modern organisations work with several different types of data.
- Structured data is organised in databases with clearly defined schemas, making it easy to store and query.
- Semi-structured data includes formats such as XML and JSON, which have some organisational structure but do not follow a strict schema.
- Unstructured data includes emails, documents, images, and social media posts that do not follow a predefined format.
Each type of data brings its own challenges when it comes to integration, analysis, and use across systems and applications.
The importance of data management
Effective data management ensures that data remains accurate, accessible, secure, and compliant with regulations. It allows organisations to gain real value from their information and use it to support decision-making, innovation, and growth.
Poor data management, on the other hand, can lead to inconsistencies, duplicated records, security risks, and missed opportunities for competitive advantage.
Defining linked data
The core concept
Linked data represents a different approach to storing and managing information. Instead of keeping data in isolated systems, it creates clear connections between related pieces of data across different sources, platforms, and organisations.
In traditional databases, relationships between data are often hidden within specific applications or systems. Linked data makes these relationships explicit, machine-readable, and accessible using web standards. This allows data from different places to be connected and understood in a consistent way.
By linking information together, separate data sources can become part of a larger knowledge network where related concepts, entities, and ideas are connected.
For example, a customer record in a CRM system could link directly to product details, purchase history, support tickets, and even external sources such as social media profiles or industry databases.
The semantic web vision
Linked data forms the foundation of the Semantic Web, a concept introduced by Tim Berners-Lee. The idea is to create a web where machines can understand and process information in a meaningful way, not just display it.
Rather than simply storing information, the Semantic Web connects knowledge in a way that allows computers to understand relationships, interpret context, and even infer new insights. This creates a global knowledge graph where applications can discover relevant information automatically, understand how different pieces of data relate to one another, and respond intelligently to complex queries.
As a result, interacting with information moves beyond simple keyword searches towards more context-aware and intelligent information discovery.
Why linked data matters
Linked data helps solve many of the challenges organisations face when managing modern data environments. Connecting information across systems, it improves data integration, makes data easier to discover, and enables different platforms and applications to work together more effectively.
Organisations that adopt linked data often see improvements in data quality, lower integration costs, and faster access to insights. It also becomes easier to uncover hidden relationships and patterns within data.
These advantages can lead to better decision-making, improved customer experiences, and new opportunities for innovation and growth.
Linked data vs. traditional data
Structured vs unstructured data
Traditional data systems are designed to handle structured data with predefined schemas, but they often struggle with unstructured or semi-structured information.
Linked data treats all information as connected resources, regardless of format. This allows different types of data to be accessed and analysed together.
Relational databases vs graph databases
Relational databases store data in tables and link records using foreign keys. Linked data uses graph-based models, where entities and their relationships are both central parts of the data.
This makes it easier to represent complex, connected information and run flexible queries that would be difficult in traditional SQL systems.
Graph models also avoid common relational challenges such as complex joins, rigid schemas, and difficulty modelling many-to-many relationships. This makes it easier for organisations to adapt their data models as requirements change.
The power of relationships
In traditional databases, relationships are usually secondary and handled through joins.
Linked data treats relationships as equally important as the data itself, allowing connections to be explored, queried, and analysed more naturally.
Key components of linked data
Understanding the technical components behind linked data is important for anyone working with or implementing linked data systems.
These components form the foundation that allows data to be published, discovered, and used as part of an interconnected network of information.
URIs (Uniform Resource Identifiers)
What are URIs and why are they important?
URIs are the core addressing mechanism in linked data. They provide globally unique identifiers for entities, concepts, or resources.
Unlike traditional database keys, which only work within a single system, URIs allow resources to be identified and referenced across different applications, organisations, and domains.
They also make it possible to create distributed data networks where resources can be linked regardless of where they are stored or which systems manage them. This ability to reference and connect data across boundaries is fundamental to how linked data works.
Best practices for creating and managing URIs
Designing effective URIs requires careful attention to naming, consistency, and long-term stability. URIs should be clear and human-readable where possible, follow consistent patterns, and remain stable over time.
Organisations should also establish governance around URIs, covering ownership, maintenance, and how namespaces are managed as systems evolve.
Common approaches include using domain names to establish authority and creating meaningful path structures that reflect how data is organised. It is also best to avoid implementation details that might change.
RDF (Resource Description Framework): describing relationships
RDF triples
RDF provides the core data model for linked data using triples. Each triple is a statement made up of three parts: subject, predicate, and object.
This simple structure allows facts to be expressed in a machine-readable way, making data easier to process, query, and connect across systems.
RDF serialisation formats
RDF data can be written in several formats depending on the technical context.
- Turtle is a compact, human-readable format often used for development and data modelling.
- JSON-LD works well with web applications and APIs because it integrates easily with JavaScript.
- RDF/XML provides compatibility with systems that use XML.
Different formats suit different use cases, and many organisations support more than one to ensure compatibility across tools and platforms.
How RDF enables semantic queries and reasoning
Because RDF represents data in a structured, connected way, it enables more advanced querying than traditional data formats.
Applications can explore relationships between entities, combine information from multiple sources, and uncover connections that are not immediately obvious. This allows systems to answer more complex questions and generate deeper insights from linked data.
SPARQL: querying linked data
Introduction to the SPARQL query language
SPARQL is the standard query language for linked data. It plays a similar role to SQL in relational databases but is designed for graph-based data models.
SPARQL allows users to query linked data, explore relationships between entities, and retrieve information from connected datasets.
SPARQL queries work by matching patterns within RDF data.
- SELECT queries return specific pieces of data
- WHERE clauses define the patterns to match
- FILTER statements add conditions to refine results
For example, a query could search for employees of a company by matching a pattern such as a person who works for a specific organisation.
Advanced SPARQL queries
SPARQL also supports more advanced query types.
- CONSTRUCT queries generate new RDF graphs from existing data
- DESCRIBE queries return detailed information about a resource
- Federated queries allow queries to run across multiple linked data sources
These features make it possible to analyse and combine data from different systems in ways that would be difficult with traditional query languages.
Linked Open Data (LOD)
Linked Open Data builds on the principles of linked data by adding open licensing, allowing data to be freely accessed, used, and shared.
Common licences include CC0 (Creative Commons Zero), which places data in the public domain, and CC-BY (Creative Commons Attribution), which allows reuse as long as the original source is credited.
Open licences are important because they allow data from different organisations to be combined and reused. This increases the overall value of the data and supports the creation of shared knowledge networks.
The 5-star linked open data scheme
Tim Berners-Lee introduced the 5-Star Linked Open Data scheme to help assess how open and usable a dataset is.
- ★ Data is available on the web with an open licence
- ★★ Data is provided in a structured, machine-readable format
- ★★★ Data uses a non-proprietary format
- ★★★★ Data uses web standards such as URIs and RDF
- ★★★★★ Data links to other datasets to provide context and enable discovery
This framework helps organisations evaluate the quality of linked data and provides a path for improving their own data publishing practices.
Real-world use cases of linked data
The value of linked data becomes clearer when looking at how organisations use it in practice. Across industries, it helps connect information, improve decision-making, and uncover insights that would otherwise remain hidden.
Healthcare: improving patient care and research
Integrating patient records
Healthcare providers often store patient information across many systems, including electronic health records, laboratory databases, imaging platforms, and pharmacy systems. Linked data makes it possible to connect these sources and create a unified view of a patient.
For example, a patient’s profile could link demographic data, diagnoses, lab results, prescriptions, and imaging studies. This connected view helps clinicians make better decisions, avoid duplicate tests, and reduce the risk of harmful drug interactions.
Supporting drug discovery and personalised medicine
Researchers and pharmaceutical companies also use linked data to connect genomic data, clinical trials, drug information, and patient outcomes.
By linking these datasets, researchers can identify which treatments are most effective for specific patient groups and uncover new opportunities for developing therapies.
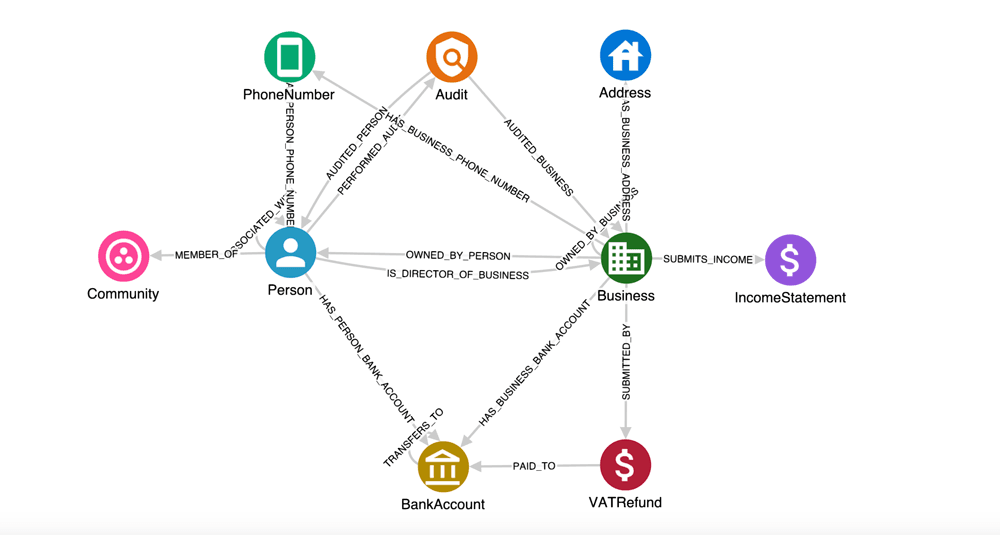
Finance: improving risk management and compliance
Detecting fraud and money laundering
Financial institutions use linked data to connect customer relationships, transaction histories, and risk indicators across multiple accounts and services.
These connected views make it easier to identify suspicious patterns and detect fraud schemes that might involve multiple accounts or organisations.
Improving KYC (Know Your Customer) processes
KYC regulations require financial institutions to verify customer identities and assess risk. Linked data helps connect customer records with external sources such as regulatory databases, sanctions lists, and ownership registries.
This approach reduces manual work while improving the accuracy and completeness of risk assessments. Institutions can also update risk profiles automatically as new information becomes available.
E-commerce: powering product discovery and recommendations
Improving search and recommendations
E-commerce platforms use linked data to build product knowledge graphs that connect products with attributes, categories, brands, reviews, and purchasing patterns.
These connections improve search results and enable more relevant recommendations by understanding relationships between products, such as complementary items, alternatives, or upgrades. This also supports more effective cross-selling and upselling.
Creating personalised shopping experiences
By linking customer data with product information and browsing behaviour, platforms can deliver more personalised shopping experiences.
This might include tailored product recommendations, customised catalogues, and targeted promotions based on individual preferences and context.
Example
Amazon uses a large product knowledge graph that links millions of products with attributes, reviews, and purchasing behaviour. This allows its systems to understand relationships between products and deliver more accurate recommendations.
Publishing: enhancing content discoverability and reach
Connecting articles, authors, and topics
Publishers use linked data to connect articles with authors, topics, sources, and related content. This helps readers discover relevant material and explore related subjects more easily.
These connections also allow publishers to generate automated recommendations, create topic-based collections, and identify emerging themes.
Improving search engine visibility
Search engines increasingly rely on structured data to understand content and context. By using linked data and schema markup, publishers can improve how their content appears in search results.
This helps search engines recognise relationships between articles, authors, and topics, improving visibility and making it easier for readers to find relevant content.
How to publish linked data: step-by-step
Publishing linked data requires careful planning, technical implementation, and ongoing maintenance.
This guide outlines the key steps organisations can follow to publish data as linked data, making it easier for both internal and external users to discover, access, and use it.
Step 1: Identify your data sources
What data should you publish as linked data?
The first step is deciding which data sources are most suitable for linked data publication. Focus on data that provides broad value, connects to external resources, or supports clear user needs.
Common candidates include reference data, master data, and datasets describing widely relevant entities such as products, people, organisations, or locations.
It is also worth prioritising data that benefits from network effects, where value increases as more organisations publish related information. Examples include bibliographic records, geographic data, organisational directories, and product catalogues.
Assess the quality and completeness of your data
Data quality is essential when publishing linked data. Review your data for accuracy, completeness, consistency, and timeliness, and address any issues before publication.
Establish clear quality metrics and monitoring processes to maintain standards over time. This may include validation rules, automated checks, and feedback mechanisms that allow users to report problems or suggest improvements.
Step 2: Choose a vocabulary or ontology
Select a vocabulary or ontology
Choosing the right vocabulary or ontology helps ensure that others can understand and reuse your linked data.
Start by looking for existing vocabularies that fit your domain. Reusing established standards improves interoperability and reduces the effort required to implement and maintain your data model.
Common examples include:
- Schema.org for describing web content
- Dublin Core for general metadata
- FOAF for people and social relationships
There are also domain-specific vocabularies, such as FIBO for financial services, HL7 FHIR for healthcare, and GoodRelations for e-commerce.
Create custom vocabulary if needed
If existing vocabularies do not fully cover your requirements, you may need to define your own terms. This should be done carefully, as custom vocabularies reduce interoperability and require additional documentation.
When creating new terms, follow clear naming conventions, provide precise definitions, and document how they should be used. Where possible, share these extensions with relevant standards bodies or community groups to encourage wider adoption.
Step 3: Create URIs for your data
Assign unique URIs to each entity in your data
Create a consistent URI strategy that gives every entity in your dataset a unique and stable identifier.
URIs should be clear, predictable, and designed to remain stable over time. When defining patterns, consider your organisation’s structure, governance, and technical setup.
Common approaches include hierarchical structures, opaque identifiers, or a mix of both. Whatever approach you choose, document it clearly and apply it consistently across all data sources.
Use HTTP URIs so that people can look up those names
Your URIs should use HTTP so they can be resolved on the web and return information about the resource they identify. This means putting the right web infrastructure in place to serve linked data when someone accesses a URI.
It is also good practice to support content negotiation, so different clients can request the format that suits them best, such as JSON-LD, Turtle, or RDF/XML.
Step 4: Create RDF triples
Describe relationships using RDF triples
The next step is to represent your data as RDF triples, describing entities and the relationships between them using the vocabularies and ontologies you have chosen.
This usually involves mapping your source data into RDF so that existing information can be published in a linked data format.
As part of this process, pay close attention to data types, language tags, and how relationships are modelled. Validation and testing can also help ensure your RDF output is accurate and consistent.
Choose an RDF serialisation format
Choose the RDF format that best fits your technical needs and how the data will be used.
- JSON-LD is often a good choice for web applications and APIs
- Turtle is easier to read and is useful for development and debugging
Supporting more than one format can make your linked data more accessible across different tools and use cases.
It is also good practice to use the correct HTTP headers and content negotiation so clients can request their preferred format.
Step 5: Publish your linked data
Host your linked data on a web server
Publish your linked data on reliable web infrastructure that can provide consistent availability and handle expected traffic. Good performance practices such as caching, compression, and general optimisation help ensure efficient delivery and a better user experience.
You may also choose to provide a SPARQL endpoint, which allows users to query your linked data directly using the SPARQL query language. This can support deeper exploration and analysis but may require additional infrastructure and security controls.
Register your linked data in public directories
If you are publishing Linked Open Data, consider registering your dataset in directories such as the LOD Cloud, DataHub, or other domain-specific catalogues. This helps others discover and use your data.
Include clear metadata about your dataset, such as descriptions, licences, update frequency, and contact details. Using standards like DCAT (Data Catalog Vocabulary) can help improve compatibility with data catalogues and discovery platforms.
The linked data ecosystem
The linked data ecosystem includes a wide range of tools and technologies that support the creation, management, and use of linked data.
Understanding these tools and what they do can help organisations choose the right technologies when planning and implementing linked data solutions.
Graph databases: storing and querying linked data
Neo4j
Neo4j is a widely used native graph database designed to store and query graph-structured data efficiently. It uses the Cypher query language, visual query tools, and a range of APIs for integrating with applications. Neo4j is particularly well-suited to use cases that involve exploring complex relationships and running fast, real-time graph queries.
RDF triplestores: managing RDF data
Apache Jena: Apache Jena is a comprehensive Java framework for building semantic web and linked data applications. It includes RDF APIs, SPARQL query engines, reasoning capabilities, and tools for working with ontologies. Jena is widely used in academic and research contexts and provides extensive customisation capabilities.
RDF4J: RDF4J (formerly Sesame) is a Java framework for processing RDF data that includes parsers, writers, and query engines for working with RDF in various formats. It provides both embedded and server-based deployment options and supports federation across multiple RDF repositories.
Fuseki: Apache Jena Fuseki is a SPARQL server that provides HTTP interfaces for querying and updating RDF data. It can be deployed as a standalone server or embedded within applications and includes web-based administration interfaces for managing datasets and monitoring performance.
The future of linked data: Emerging trends
The linked data landscape continues to evolve as new technologies and business needs emerge. Understanding these trends helps organisations prepare for future opportunities in the linked data ecosystem.
Linked data and AI
Linked data can improve how machine learning systems work by providing structured, connected knowledge.
Knowledge graphs built from linked data help AI models understand relationships between entities and incorporate external knowledge. This can improve both accuracy and explainability, which is particularly important in areas such as healthcare and finance.
New techniques such as knowledge graph embeddings and graph neural networks are also making it easier to combine linked data with machine learning, supporting tasks such as entity resolution, link prediction, and recommendations.
Linked data and Blockchain
Blockchain technologies may help strengthen data integrity and provenance in linked data ecosystems.
By recording publication events and updates on an immutable ledger, blockchain can provide verifiable records of where data came from and how it has been used.
Decentralised identity systems and smart contracts could also support secure data sharing, automated licensing, and new incentive models for publishing and maintaining high-quality linked data.
Conclusion: Embracing the power of linked data
Linked data is changing how organisations manage and connect information. By linking data across systems, organisations can break down silos, discover new insights, and support better decision-making.
The technologies and principles covered in this guide—such as RDF, SPARQL, and semantic vocabularies—provide the foundation for building connected knowledge networks that make data more useful and accessible.
Real-world examples across healthcare, finance, e-commerce, and publishing show that linked data is already delivering practical value today.
However, successful implementation requires attention to challenges such as data quality, scalability, interoperability, and security. Organisations that address these areas and adopt the right tools and processes are best placed to benefit from linked data.
As linked data continues to evolve alongside technologies like AI and blockchain, its role in creating intelligent, connected systems will only grow.
For organisations looking to improve how they manage and use information, linked data offers a powerful approach for connecting data, uncovering insights, and supporting innovation.