
“Relevance is the practice of improving search results for users by satisfying their information needs in the context of a particular user experience, while balancing how ranking impacts business’s needs.” [1]
Providing relevant information to the user performing search queries or navigating a site is always a complex task. It requires a huge set of data, a process of progressive improvements, and self-tuning parameters together with infrastructure that can support them.
Such search infrastructure must be introduced seamlessly and smoothly into the existing platform, with access to all relevant data flows to provide always up-to-date data. Moreover, it should allow for easy addition of new data sources, to cater to new requirements, without affecting the entire system or the current relevance.
Information must be stored and managed correctly as well as take into account the relationships between individual items, providing a model and access patterns that can be also processed automatically by artificial minds (machines). These models are generally referred to as Knowledge Graphs. They have become a crucial resource for many tasks in machine learning, data mining and artificial intelligence applications.
Knowledge Graphs: An Introduction
A knowledge graph is a multi-relational graph composed of entities as nodes and relationships as edges with different types that describe facts in the world.
Out of the many features involved in the processing of data sources to create a knowledge graph, Natural Language Processing (NLP) plays an important role. It assists in reading and understanding text to automatically extract “knowledge” from a large number of data sources.[3]
The search goal varies based on the domain in which it is used, so it would differ substantially amongst web search and product catalog navigation in an ecommerce site, scientific literature discovery, and expert search prominent in medicine, law and research. All these domains differ in terms of business goals, the definition of relevance, synonyms, ontologies and so on.
In this blog post, we introduce knowledge graphs as the core data source on top of which a relevant search application has been built. We describe in detail the data model, the feeding and updating processes, and the entire infrastructure applied to a concrete application. We will consider a product catalog for a generic ecommerce site as the use case for this article; however, the concepts and ideas could be applied easily to other scenarios.
The Use Case: Ecommerce
In all ecommerce sites, text search and catalog navigation are not only the entry points for users but they are also the main “salespeople.” Compared with web search engines, this use case has the advantage that the set of “items” to be searched is more controlled and regulated.
However, there are a lot of critical aspects and peculiarities that need to be taken into account while designing the search infrastructure for this specific application:
- Multiple data sources: Products and related information come from various heterogeneous sources like product providers, information providers, and sellers.
- Multiple category hierarchies: An ecommerce platform should provide multiple navigation paths to simplify access from several perspectives and shorten the time from desire to purchase. This requires storing and traversing multiple category hierarchies that are subject to change over time based on new business requirements.
- Marketing strategy: New promotions, offers, and marketing campaigns are created to promote the site or specific products. All of them affect, or should affect, results boosting.
- User signals and interactions: In order to provide a better and more customized user experience, clicks, purchases, search queries, and other user signals must be captured, processed and used to drive search results.
- Supplier information: Product suppliers are the most important. They provide information like quantity, availability, delivery options, timing and changes in the product’s details.
- Business constraints: Ecommerce sites have their own business interests, so they must also return search results that generate profit, clear expiring inventory, and satisfy supplier relationships.
All these requirements and data could affect “relevance” in several ways during search, as well as how the product catalog should be navigated. Keeping these constraints in mind, designing a relevant search infrastructure for ecommerce vendors requires an entire ecosystem of data and related data flows together with platforms to manage them.
Relevant Search
Relevant search revolves around four elements: text, user, context, and business goal:
- Information extraction and NLP are key to providing search results that mostly satisfy the user’s text query in terms of content.
- User modelling and recommendation engines allow for customizing results according to user preferences and profiles.
- Context information like location, time, and so on, further refine results based on the needs of the user while performing the query.
- Business goals drive the entire implementation, as search exists to contribute to the success and profitability of the organization.
In our previous blog posts on text search and NLP for social media recommendations, we described how to use advanced NLP features and graphs to combine text, user profiles and behaviour to customize the search experience using recommendation engines.
Relevant searches also require context information, previous searches, current business goals, and feedback loops to further customize user experience and increase revenues. These must be stored and processed in ways that can be easily accessed and navigated during searches without affecting the user experience in terms of response time and quality of the search.
Knowledge Graphs: The Model
In order to provide relevant search, the search architecture must be able to handle highly heterogenous data in terms of sources, schema, volume and speed of generation. This data includes aspects such as textual descriptions and product features, marketing campaigns and business goals. Moreover, these have to be accessed as a single data source, so they must be normalized and stored using a unified schema structure that satisfies all the informational and navigational requirements of a relevant search.
The graph data model, considered as both the storage and the query model, provides the right support for all the components of a relevant search. Graphs are the right representational option for the following reasons:
- Information Extraction attempts to make the text’s semantic structure explicit by analysing its contents and identifying mentions of semantically defined entities and relationships within the text. These relationships can then be recorded in a database to search for a particular relationship or to infer additional information from the explicitly stated facts. Once “basic” data structures like tokens, events, relationships, and references are extracted from the text provided, related information can be extended by introducing new sources of knowledge like ontologies (ConceptNet 5, WordNet, DBpedia, domain specific ontology) or further processed/extended using services like AlchemyAPI.
- Recommendation Engines build models for users and items/products based on dynamic (such as user previous sessions) or static (such as description) data, which represent relationships of interests. Hence a graph is a very effective structure to store and query these relationships, even allowing them to be merged with other sources of knowledge such as user and item profiles.
- Context information is a multi-dimensional representation of a status or an event. The types and number of dimensions can change greatly and a graph allows for the required high degree of flexibility.
- A graph can be used to define a rule engine that could enforce whichever business goal is defined for the search.
Lately, the use of graphs for representing complex knowledge and storing them in a easy-to-query model has become prominent for information management, and the term “knowledge graph” is becoming increasingly popular. Sometimes defined as “ encyclopaedias for machines,” knowledge graphs have become a crucial resource for advanced search, machine learning and data mining applications [4]. Nowadays, graph construction is one of the hottest topics in artificial intelligence (AI).
A knowledge graph, from a data model perspective, is a multi-relational graph composed of entities as nodes and relationships as edges with different types. An instance of an edge is a triple (e1, r, e2) which describes the directed relationship r between the two entities e1 and e2.
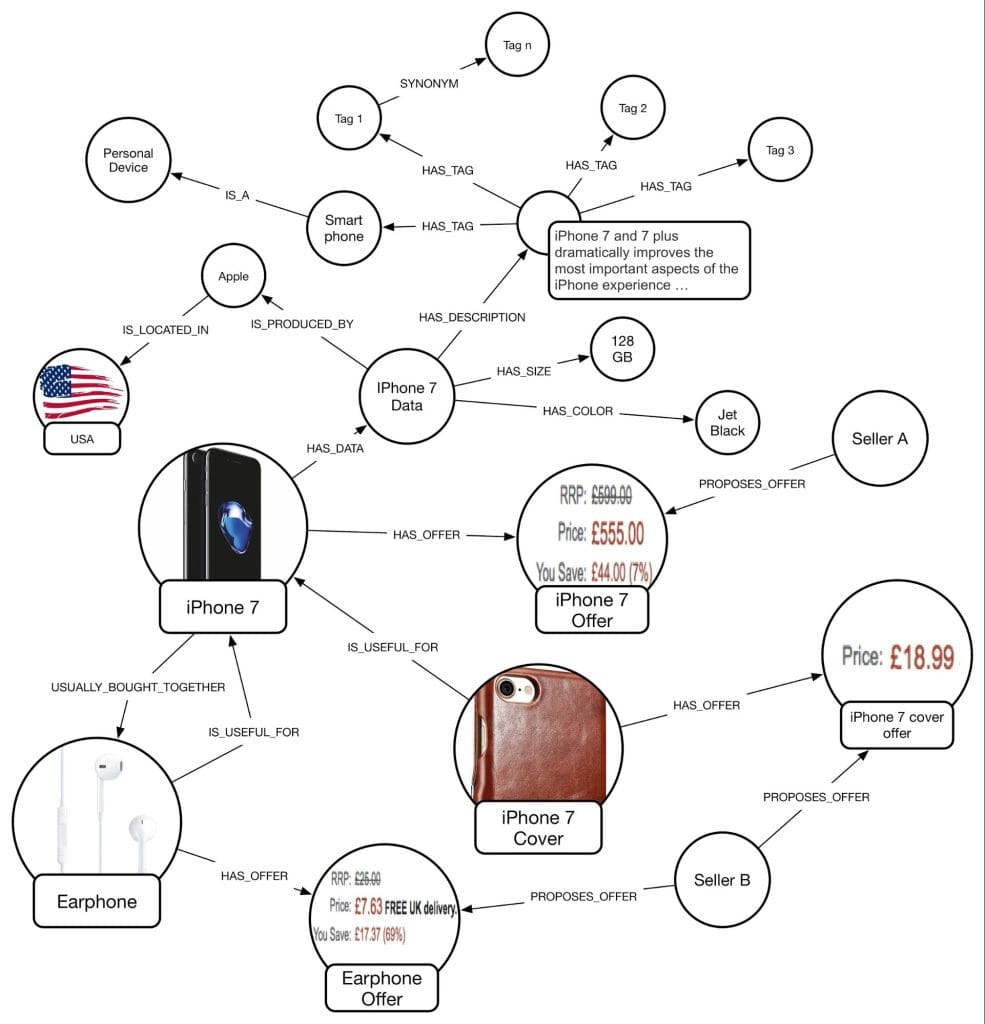
This schema merges multiple knowledge graphs into one big knowledge graph that can be easily navigated. Many of the relationships in the schema above are explicitly loaded using data sources like prices, product descriptions, and some relationships between products (like IS_USEFUL_FOR), while others are inferred automatically by machine learning tools.
This is the logical model which can be extended to a more generic and versatile design with various types of relationships. Consider this sample as a representation of product attributes:
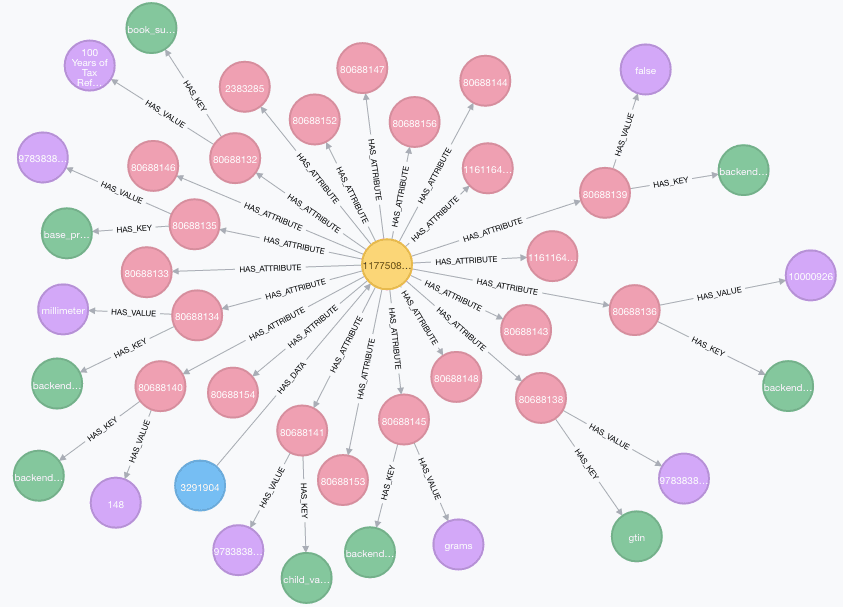
The specific relationships that describe a product feature, for instance HAS_SIZE, HAS_COLOUR, are replaced with more general and dynamic schema:
(p:ProductData)-[:HAS_ATTRIBUTE]->(a:Attribute),
(a)-[:HAS_KEY]->(k:Key {ref: "Size"}),
(a)-[:HAS_VALUE]->(v:Value {data: "128 GB"})
Part of the model is built using NLP by processing the information available in product details. In this case, GraphAware NLP framework as described in a previous blog post, is used to extract knowledge from text.
After the first round in which text is processed and organized into tags as described in the schema, information is extended using ConceptNet 5 to add new knowledge like synonyms, specification, generalization, localization, and other interesting relationships. Further processing allows computing of similarities between products, clustering them, and automatically assigning multiple “keywords” to describe the cluster.
The knowledge graph is the heart of the infrastructure not only because it is central to aiding the search but also because it is a living system growing and learning day by day, following the user needs and the evolving business requirements.
Infrastructure: A 10k-Foot View
Considering the relevant search goals described earlier, the model of the knowledge graph designed for the specific use case, and the type and amount of data to be processed together with the related data flows and requirements in terms of textual search capabilities, we defined the following architecture described in high-level terms:
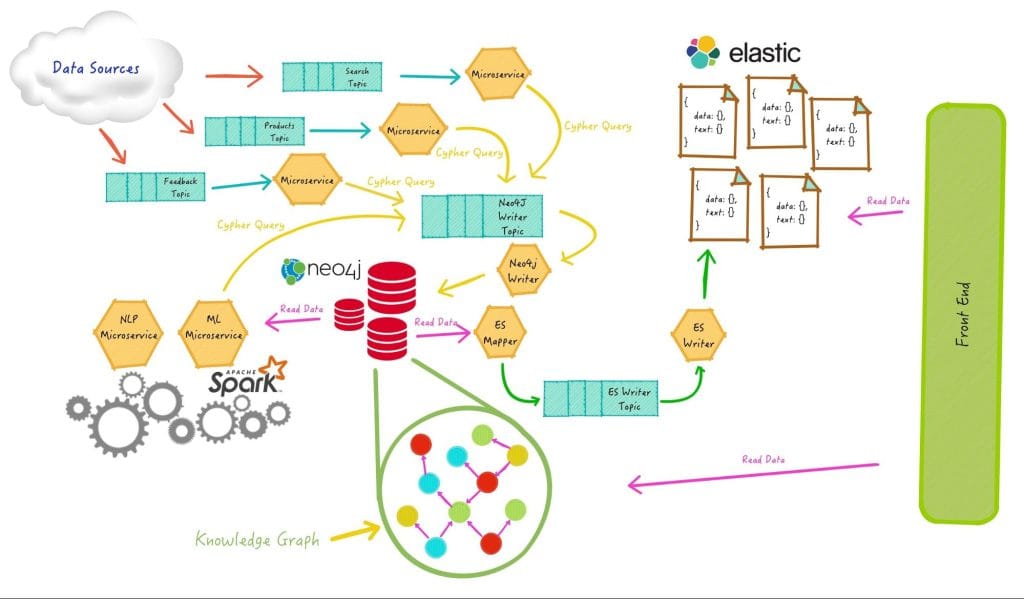
The data flow is composed of several data sources like product information sources, product offers, sellers, click streams, feedbacks and more. All of these data items flow from outside to inside the data architecture using Apache Kafka as the queue and streaming platform for building real-time data pipelines. Information goes through a multi-step process where it is transformed before being stored in Neo4j, the main database of the infrastructure.
In order to avoid concurrency issues, only one microservice reads from the queue and writes to Neo4j. The raw sources are then enriched and processed and new relationships between objects are created. In this way, the knowledge graph is created and maintained.
Many machine learning tools and data mining algorithms as well as Natural Language Processing operations are applied to the graph and new relationships are inferred and stored. In order to process this huge amount of data, an Apache Spark cluster is seamlessly integrated into the architecture through the Neo4j-Spark connector.
At this point, data is transformed to several document types and sent to an Elasticsearch cluster where it is stored as documents. In Elasticsearch, these documents are analyzed and indexed for providing text search. The front-end interacts with Neo4j for providing advanced features that require graph queries that cannot be expressed using documents or simple text searches.
We will now describe in more detail the two core elements of the infrastructure.
The Neo4j Roles
Neo4j is the core of the architecture – it is the main database, the “single source of truth” of the product catalog since it stores the entire knowledge graph on which all the searches and navigations are performed. It is a viable tool in a relevant search ecosystem offering not only a suitable model for representing complex data (text, user models, business goals, and context information), but also for providing efficient ways of navigating this data in real time.
Moreover, at an early stage of the “search improvement process,” Neo4j can help relevance engineers to identify salient features describing the content, the user, or the search query. Later on it will help to find a way to instruct the search engine about those features through extraction and enrichment.
Once the data is stored in Neo4j, it goes through a process of enrichment that comprises three main categories: cleansing, existing data augmentation, and data merging.
First, cleansing. It’s usually well worth the time to parse through documents, look for mistakes such as misspellings and document duplications, and correct them. Otherwise, users might not find a document because it contains a misspelling of the query term. Or they may find 20 duplicates of the same document, which would have the effect of pushing other relevant documents off the end of the search results page. Neo4j and the GraphAware NLP framework provide features that find duplicates or synonyms and relate them, as well as search for misspellings of words.
Second, the existing data is post-processed to augment the features already there. For instance, machine learning techniques can be used to classify or cluster documents. The possibilities are endless. After this new metadata is attached to the documents, it can serve as a valuable feature for users to search through.
Finally, new information is merged into the documents from external sources. In our ecommerce use case, the products being sold often come from external vendors. Product data provided by the vendors can be sparse: for instance, missing important fields such as the product title. In this case, additional information can be appended to documents. The existing product codes can be used to look up product titles, or missing descriptions can be written in by hand. The goal is to provide users with every possible opportunity to find the document they’re looking for, and that means more and richer search features.
Elasticsearch is for SEARCH
It is worth noting here that Elasticsearch is not a database. It is built for providing text searches at super-high speed over a cluster of nodes. Also, it can’t provide full ACID support.
“Lucene, which Elasticsearch is built on, has a notion of transactions. Elasticsearch, on the other hand, does not have transactions in the typical sense. There is no way to rollback a submitted document, and you cannot submit a group of documents and have either all or none of them indexed. What it does have, however, is a write-ahead-log to ensure the durability of operations without having to do an expensive Lucene-commit. You can also specify the consistency level of index-operations, in terms of how many replicas must acknowledge the operation before returning. […] Visibility of changes is controlled when an index is refreshed, which by default is once per second, and happens on a shard-by-shard-basis.” [Source: Elasticsearch as a NoSQL Database]
Nonetheless, in our opinion, it is used as the main data store too often. This approach could lead to a lot of issues in terms of data consistency and ease of managing the data stored in the documents.
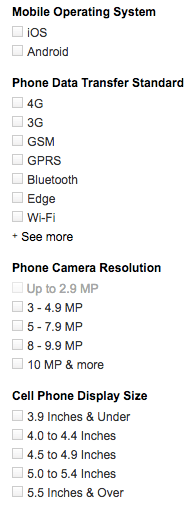
Elasticsearch can provide an efficient interface for accessing catalog information, providing not only advanced text search capability but also any sort of aggregation and faceting. Faceting is the capability of grouping search results for providing predefined filters and allowing users to simply refine the search. This is an example from Amazon:
It can also be useful for providing analytics as well as other capabilities like collapsing results. The latter, added in the latest version (5.3.x at the time of writing), allows you to group results and avoid having to show the same results when they only contain minor differences.
Those among many others are the reasons why in the proposed architecture Elasticsearch is used as the front-end search interface to provide product details as well as autocomplete and suggestion functionalities.
Conclusion
This post continues our series on advanced applications and features built on top of a graph database using Neo4j. The knowledge graph plays a fundamental role since it gathers and represents all the data needed in an organic and homogeneous form and allows access, navigation and extensibility in an easy and performant way.
It is the core of a complex data flow with multiple sources and feeds the Elasticsearch front-end. In this blog post, our presentation of a complete end-to-end architecture illustrates an advanced search infrastructure that powers highly relevant searches.
If you believe GraphAware NLP framework or our expertise with knowledge graphs would be useful for your project or organisation, please drop an email to nlp@graphaware.com specifying “Knowledge Graph” in the subject and one of our GraphAware team members will get in touch. _ GraphAware is a Gold sponsor of GraphConnect Europe.
References
[1]
D. Turnbull, J. Berryman – Relevant Search, Manning
[2]
A. L. Farris, G. S. Ingersoll, and T. S. Morton – Taming Text, Manning
[3]
Google Knowledge Graph – www.google.com/intl/es419/insidesearch/features/search/knowledge.html
[4]
L. Del Corro – Knowledge graphs: Encyclopaedias for machines – www.ambiverse.com/knowledge-graphs-encyclopaedias-for-machines/
[5]
E. Gabrilovich, N. Usunier – Constructing and Mining Web-Scale Knowledge Graphs, SIGIR ‘16 Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval
