
This is the second in a three-part series on our approach to AI in GraphAware Hume. It explores some of the architectural choices behind Document Intelligence – an upcoming feature in active development.
In the first post of this series, I introduced the concepts behind Document Intelligence in GraphAware Hume: what it is, how it’ll accelerate the analyst experience at all stages of an investigation, and why evidence linkage is so important.
What I didn’t share is how Document Intelligence will work in practice. Not at the code level, but at the level of design decisions: the choices we’ve made, the approaches we tried (and moved on from), and the reasoning behind the architecture we’ve arrived at.
I want to explain some of our thought processes here. Not as a technical exercise, but because when you trust your analytical work to AI-enhanced tools, you need confidence that someone, somewhere, has made the right calls.
I’d rather show our work than ask you to take it on faith.
The approach that looks right on paper
When most organisations first think about applying AI to a collection of documents, they reach the same conclusion.
- You pre-process the documents
- The AI reads through them
- The AI extracts the important entities (people, locations, events, relationships, etc.)
- The AI builds a structured knowledge graph from that extraction
- The analysts query the graph
It’s a logical sequence. It mirrors how human teams often work: researchers process raw material, structure it, and hand structured intelligence to analysts. There’s real technology behind it, and the approach has a name in the AI research community: GraphRAG. There’s a strong body of work demonstrating its value in certain contexts.
We explored this approach seriously. We built GraphRAG prototypes and ran experiments. And I want to be direct about what we found, because the honest version of this story is more useful than the polished one.
Three problems we found with GraphRAG in law enforcement and intelligence work
The first problem we encountered was cost and complexity at the ingestion stage.
Building a knowledge graph from documents using a language model isn’t a single operation; it’s a pipeline. For each document, you extract entities, identify the relationships between them, build summaries, and resolve duplicates where the same person or organisation appears under different names. Each step requires a separate call to the AI model, and those costs compound quickly.
This is manageable for a small, stable document collection. But for a case with hundreds of constantly updated documents (which is the reality of intelligence work), the cost and time add up quickly. Every time a document changes, portions of the pipeline need to run again.
That’s an expensive, but solvable, engineering problem. The second problem is harder.
When you pre-process documents through an AI extraction pipeline, you’re asking the model to make interpretive decisions before an analyst has asked a single question:
- Which entities matter?
- Which relationships are significant?
- What level of detail should be captured?
The model makes those choices during ingestion based on patterns learned from its training, not on what your specific investigation actually needs. If the model extracts something incorrectly or misses something that turns out to be important, the errors are baked into your knowledge graph faster than any analyst can notice them.
This leads directly to the third and, for our customers, most consequential problem: the review bottleneck.
When AI extracts structured facts for an intelligence graph, those extractions need human verification, especially if they may later influence investigative decisions. That means a trained analyst reviewing the system’s output and confirming it’s correct.
It’s a necessary safeguard, not a design flaw or operational extra.
But language models can process documents at volumes and velocities that no team of analysts could ever review in parallel. The moment human sign-off becomes a mandatory gate for every extraction, automation stops being an accelerator and becomes a bottleneck instead. You’ve just moved the problem, not solved it.
We faced a choice: either accept that analysts would rely on AI-generated extractions they hadn’t meaningfully reviewed, or design a fundamentally different approach.
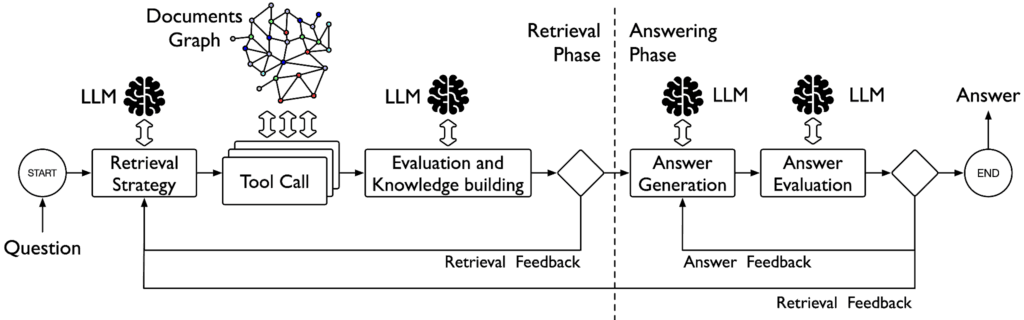
Flipping the GraphRAG problem around
The realisation we came to sounds simple in retrospect. The problem with building intelligence into the ingestion phase is that you’re answering questions before you know what they are. The analyst hasn’t asked anything yet. The model can only guess what will matter.
Instead, what if the intelligence lived in the question-answering phase? What if the AI only began working on the documents when an analyst actually asked a question?
This is the principle behind what the research community calls Agentic RAG, which will underpin Document Intelligence in GraphAware Hume. The terminology matters less than the concept, so let me describe what will actually happen when an analyst asks a question.
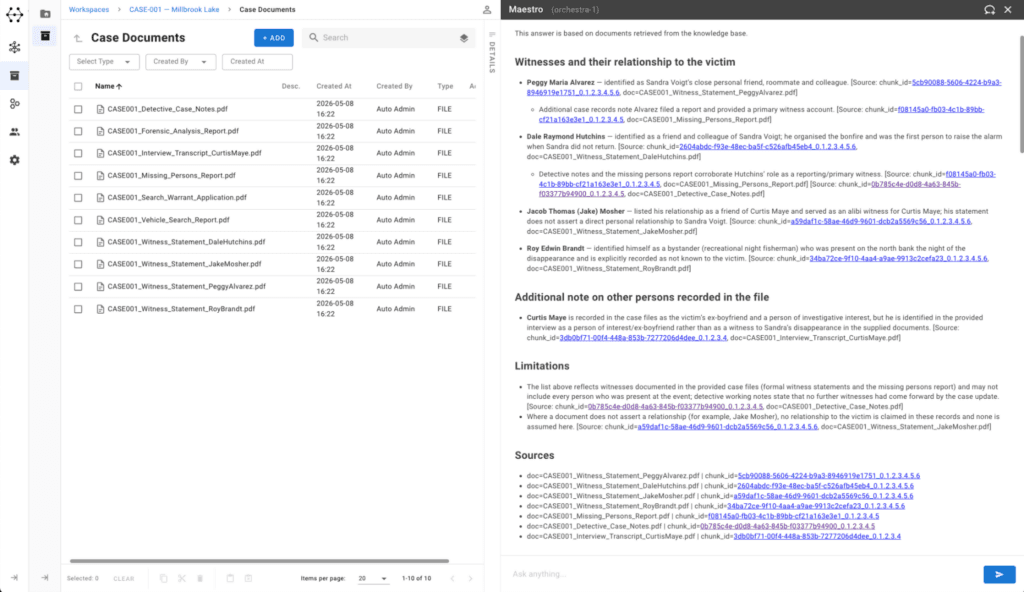
When an analyst asks a question through the Hume Maestro interface, the system won’t consult a prebuilt knowledge graph composed of entities and relationships. Instead, it will begin an active retrieval process using documents that have been chunked semantically and indexed: searching Workspace documents for relevant passages, assessing whether those results are sufficient to answer the question, and, if not, trying a different approach.
The documents are still stored in a graph, but in a simpler and lighter version that doesn’t require multiple LLM calls to build. It’s made up of fixed node types, such as Document, Page, and Chunk. The vector and full-text indexes do the rest.
The system might change how it searches. It might broaden or narrow its focus. It might switch from a conceptual search to an exact-phrase search when it determines that the first approach is missing something specific. It will keep a running record of what it has found so far, what is still missing, and what to try next.
When it has gathered enough evidence, and only then, it will construct an answer, always assembling that answer from the actual passages it retrieved, not from general knowledge.
A separate evaluation step will then review that answer before it’s shown to the analyst. Is the answer consistent with the evidence? Does the reasoning hold? If not, the system can loop back, seek better evidence, or attempt a different formulation before presenting anything to the analyst.
The whole process will be visible and logged. The analyst will be able to see the answer directly alongside its sources, including the path the system took to get there.

To take an example, say an analyst investigating a drug trafficking network asks:
‘Which witnesses place the suspect near the harbour between the 10th and 15th of March?’
The system would search the Workspace for documents and identify three relevant passages across two witness statements. It evaluates whether they’re sufficient, spots a gap: one statement mentions ‘the waterfront’ rather than ‘the harbour’. It broadens its search, finds a fourth passage, and presents the answer with direct links to each source.
Every sentence in the answer is linked to the specific passage it came from, so the analyst can verify each claim individually, see why the system broadened its search, and judge for themselves whether ‘the waterfront’ and ‘the harbour’ refer to the same location.
Proving the agentic approach
For our internal research and development, we used FinanceBench, a rigorous public benchmark of complex questions based on real financial documents, as our testing ground.
Financial document analysis and intelligence analysis share important characteristics: both involve large volumes of material, require multi-step reasoning rather than answers found in a single paragraph, and carry high stakes when conclusions are wrong.
These are results from our internal R&D testing, and should be understood as indicative of architectural direction rather than guaranteed operational performance.
We first benchmarked a standard single-pass retrieval system – an approach where the AI retrieves information once and generates an answer from the initial set of results. It achieved around 68% accuracy on complex, multi-step questions.
That’s reasonable for simple lookups, but not great for the kinds of questions that actually require analytical reasoning.
We then repeated the same experiments using the approach described above, with iterative retrieval and self-evaluation. This increased the accuracy to 74%: a meaningful improvement.
On questions requiring information from multiple documents simultaneously, the kind of question that matters most in intelligence work, simple retrieval scored just 18%. Whereas the agentic approach reached 54%.
There’s a third figure I’ll come back to in the final post in this series: 80.5%. That result involves something beyond the retrieval architecture itself. In my opinion, it’s the most interesting part of the story.
Building a structural answer to hallucination, not a behavioural one
I discussed hallucinations in the first post. It’s worth returning to them here with greater precision, because the risk of hallucination led us to the architecture I’ve described.
In its most basic form, a large language model generates text by predicting which words are most likely to come next based on what came before. It’s extraordinarily good at this. LLMs produce fluent, coherent, confident prose. The problem is that this capability doesn’t distinguish between text that’s grounded in real evidence and text that’s constructed from patterns.
When asked a question it can’t answer based on the available evidence, an LLM will usually produce an answer anyway that may align with its general training but not necessarily with the specific documents in front of it.
There are broadly two responses to this problem. The first is behavioural: train or instruct the model to say “I don’t know” more often, or to hedge its answers. This helps, but it relies on the model’s own judgement about when it’s uncertain, which is imperfect.
The second response is structural: design a system that can’t produce an output not anchored to retrieved source material. This is what evidence linkage does. The answer generation step in our architecture won’t have access to the model’s general knowledge as a fallback. It will work only from the retrieved passages. If those passages don’t contain the answer, the system will acknowledge that gap rather than filling it.

This isn’t a guarantee that every output will be correct. Retrieval can miss relevant passages, and the model can misinterpret what it finds. But it’s a much stronger constraint than a behavioural instruction, and it means that when the system is wrong, it will be wrong in a traceable way. There will be a source passage you can examine, and you can see exactly where the reasoning broke down.
For an analyst preparing evidence for legal proceedings, the distinction between “the system was wrong, and I can see why” and “the system was wrong and I have no way of knowing” is the difference between a recoverable error and an undetected one.
Evidence linkage answers the question, “Where did this sentence come from?” But there’s a complementary question that matters just as much to an analyst: “What did the system look at, and what did it leave out?” To answer it, Document Intelligence will take stock of the full document inventory before retrieval even begins.
The system will know every document present in the Workspace, and as the retrieval process unfolds, it will track which documents were surfaced by its searches and, of those, which actually contributed passages to the final answer.

The result is a complete picture of document coverage presented alongside every answer.
An analyst will see that each statement is anchored to a specific source passage, which case documents were consulted, which informed the answer, and which played no part at all.
That last category is more valuable than it might appear: knowing that a particular witness statement contributed nothing to an answer is itself analytically useful, and it removes the nagging doubt of whether the system simply ignored material it should have considered.
Together, sentence-level source attribution and Workspace-level coverage transparency turn the answer from something an analyst has to take on faith into something they can audit end-to-end. And that, in our experience, is what genuinely builds trust in the output.
The documents will stay simple; the thinking is in the question
Finally, I want to describe one last practical implication of the approach we have chosen. Because we’re moving the intelligence to query time rather than ingestion time, the documents can be stored in a simple, lightweight way, as shown in the schema below.
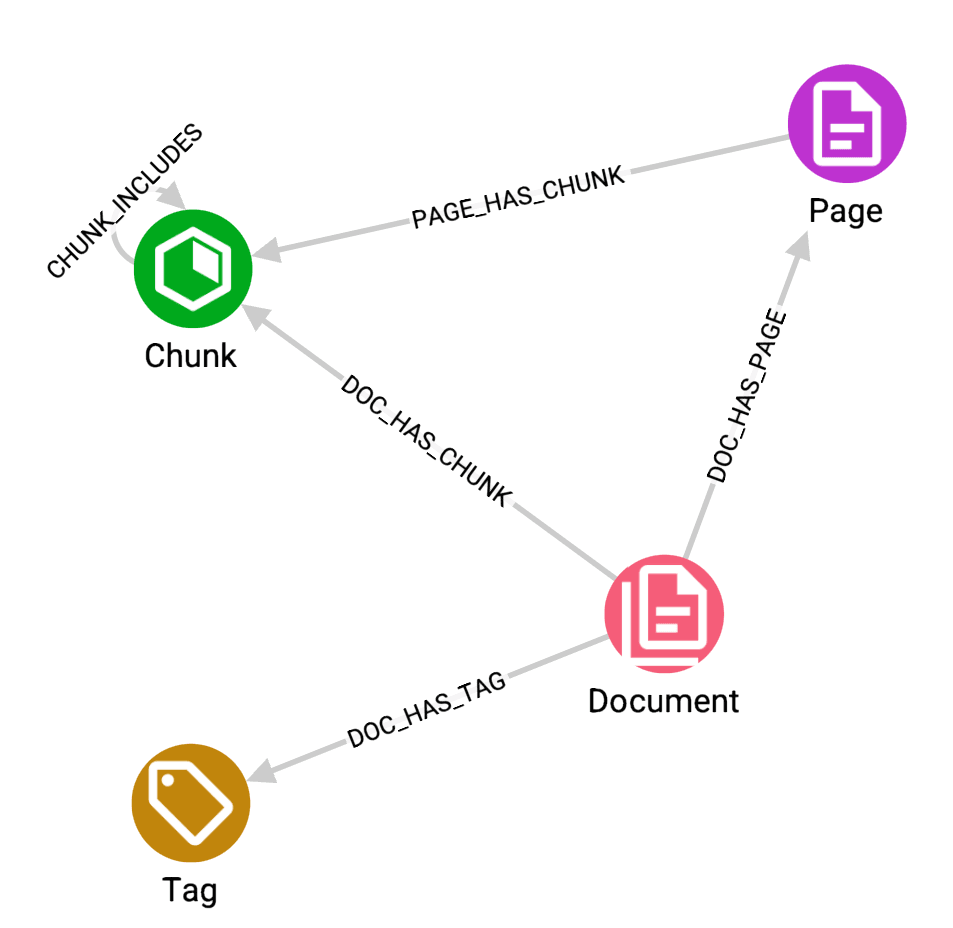
When a document is uploaded to a Workspace, it is chunked into sections and indexed so it can be searched using both conceptual similarity and exact text matching. That’s all. There’s no expensive extraction pipeline or AI processing before an analyst asks a question.
A document will be ready for querying in a fraction of the time it would take to extract a full knowledge graph. And if a document changes, such as an updated witness statement or a revised report, the update will be straightforward.
This has a practical consequence for how Document Intelligence will fit into the Workspace model introduced in GraphAware Hume 3.0.
An analyst will be able to add documents to a case Workspace at any point during an investigation, not just at the start. The system won’t need to be “rebuilt” as new material comes in. Instead, it will be ready to reason over whatever is there at the moment the analyst asks their question.
This aligns with how investigations work: iteratively, with new information constantly arriving, rather than as a clean batch process with a defined start and end.
In the next post, I’ll explain where the 80.5% figure comes from, and why I think the mechanism behind it is the most consequential part of what we’re building: a system that gets better the more it’s used, in ways your organisation can see, control, and audit.
GraphAware Hume is a graph-powered intelligence analysis platform used by law enforcement and intelligence agencies. Document Intelligence is currently in active development. If you would like to follow the progress of this work or discuss how it applies to your organisation’s needs, get in touch.
