
Graph algorithms represent one of the most powerful and versatile tools in computer science, enabling us to solve complex problems involving relationships, connections, and networks. From social media friend recommendations to GPS navigation systems, graph algorithms power many of the technologies we use daily. This comprehensive guide will explore the fundamental concepts, advanced techniques, and real-world applications of graph algorithms, providing you with the knowledge needed to implement these powerful tools effectively.
What are graph algorithms?
A graph, in the context of computer science and mathematics, is a data structure consisting of nodes (vertices) connected by edges. This simple yet powerful abstraction can represent countless real-world scenarios: social networks where people are nodes and friendships are edges, transportation systems where cities are nodes and roads are edges, or molecular structures where atoms are nodes and bonds are edges.
Graph algorithms are computational procedures designed to solve problems related to graphs. These algorithms help us answer critical questions such as: What’s the shortest path between two points? How can we find communities within a network? Which nodes are most influential in a system? How can we detect cycles or dependencies?
The importance of graph algorithms extends far beyond theoretical computer science. They form the backbone of modern technology infrastructure, powering search engines, recommendation systems, fraud detection mechanisms, and network optimisation tools. Understanding graph algorithms is crucial for software engineers, data scientists, and researchers working with interconnected data.
Graph algorithms can be broadly categorised into several types: traversal algorithms that explore graph structures systematically, shortest path algorithms that find optimal routes, spanning tree algorithms that create minimal connected subgraphs, flow algorithms that optimise resource distribution, and specialised algorithms for specific applications like ranking and community detection.
Key graph concepts
Before diving into specific algorithms, it’s essential to understand the fundamental concepts that form the foundation of graph theory. These concepts provide the vocabulary and framework necessary to discuss and implement graph algorithms effectively.
Nodes (vertices)
Nodes, also called vertices, are the fundamental units of a graph. They represent entities, objects, or points of interest in the system being modelled. In a social network, nodes might represent individual users; in a transportation network, they could represent cities or intersections; in a computer network, they might represent servers or routers.
Edges
Edges are the connections between nodes, representing relationships, pathways, or interactions. The nature of these relationships depends on the specific application. In a friendship network, edges represent mutual connections; in a web graph, they represent hyperlinks; in a transportation network, they represent roads or flight routes.
Directed vs. undirected graphs
Directed graphs (digraphs) have edges with a specific direction, indicated by arrows. These are useful for modelling asymmetric relationships like web links, where page A might link to page B without B linking back to A. Undirected graphs have bidirectional edges, suitable for symmetric relationships like physical roads that can be travelled in both directions.
Weighted vs. unweighted graphs
Weighted graphs assign numerical values to edges, representing costs, distances, capacities, or strengths of relationships. An unweighted graph treats all edges equally. Weighted graphs are essential for optimisation problems where the “cost” of traversing different edges varies significantly.
Cyclic vs. acyclic graphs
A cycle in a graph is a path that starts and ends at the same node. Acyclic graphs contain no cycles, making them particularly useful for representing hierarchical relationships or dependencies. Directed Acyclic Graphs (DAGs) are especially important in applications like task scheduling and dependency resolution.
Connected vs. disconnected graphs
A connected graph has a path between every pair of nodes. In disconnected graphs, some nodes cannot reach others, creating isolated components. Understanding connectivity is crucial for algorithms that need to ensure all nodes can be reached or processed.
Dense vs. sparse graphs
Graph density refers to the ratio of existing edges to possible edges. Dense graphs have many connections relative to their size, while sparse graphs have relatively few edges. This distinction affects algorithm choice and performance, as different algorithms perform better on dense versus sparse graphs.
Graph representation
The way we represent graphs in computer memory significantly impacts the performance and applicability of different algorithms. Each representation method has distinct advantages and trade-offs that make it suitable for specific use cases.
Adjacency matrix
An adjacency matrix is a two-dimensional array where entry (i,j) indicates whether there’s an edge from node i to node j. For weighted graphs, the entry contains the edge weight; for unweighted graphs, it contains 1 for existing edges and 0 for non-existing edges.
Advantages: Constant-time edge lookup O(1), simple implementation, efficient for dense graphs, easy to work with mathematically.
Disadvantages: Space complexity O(V²) regardless of edge count, inefficient for sparse graphs, and adding/removing vertices is expensive.
Adjacency list
An adjacency list represents each node as a list of its neighbouring nodes. This can be implemented using arrays, linked lists, or hash tables, depending on the specific requirements and programming language.
Advantages: Space-efficient for sparse graphs O(V + E), fast iteration over neighbours, efficient vertex addition/removal.
Disadvantages: Edge lookup time varies O(degree of vertex), slightly more complex implementation than adjacency matrix.
Adjacency set
Similar to adjacency lists but using sets (hash sets) to store neighbours, providing faster edge lookup while maintaining space efficiency for sparse graphs.
Advantages: Fast edge lookup O(1) on average, space-efficient for sparse graphs, efficient neighbour iteration.
Disadvantages: Higher memory overhead per edge compared to adjacency lists, implementation complexity.
Edge list
An edge list simply stores all edges as a list of pairs (or triplets for weighted graphs), representing the source node, destination node, and optionally the weight.
Advantages: Minimal space overhead, simple implementation, efficient for algorithms that process all edges.
Disadvantages: Slow edge lookup O(E), inefficient for neighbour queries, poor performance for most graph algorithms.
Graph traversal algorithms
Graph traversal algorithms systematically visit all nodes in a graph, forming the foundation for many more complex graph algorithms. The two primary traversal methods, Breadth-First Search (BFS) and Depth-First Search (DFS), each offer unique advantages for different applications.
Breadth-first search (BFS)
BFS explores a graph level by level, visiting all nodes at distance k before visiting nodes at distance k+1. This systematic approach makes BFS ideal for finding shortest paths in unweighted graphs and analysing graph structure layer by layer.
The algorithm uses a queue data structure to maintain the order of exploration. Starting from a source node, BFS adds all immediate neighbours to the queue, then processes each queued node by adding its unvisited neighbours to the queue.
Depth-first search (DFS)
DFS explores a graph by going as deep as possible along each branch before backtracking. This approach is naturally recursive and can be implemented using either recursion or an explicit stack data structure.
DFS is particularly useful for problems involving path exploration, cycle detection, and topological sorting. The algorithm’s deep exploration pattern makes it excellent for finding paths between nodes and analysing graph connectivity.
Shortest path algorithms
Shortest path algorithms solve one of the most fundamental problems in graph theory: finding the optimal route between nodes. These algorithms have countless applications, from GPS navigation to network routing protocols.
Dijkstra’s algorithm
Dijkstra’s algorithm finds the shortest path from a source node to all other nodes in a weighted graph with non-negative edge weights. The algorithm maintains a priority queue of nodes ordered by their current shortest distance from the source.
The algorithm works by repeatedly selecting the unvisited node with the smallest known distance, then updating the distances to its neighbours if a shorter path is found. This greedy approach guarantees optimal solutions for graphs with non-negative weights.
Bellman-Ford algorithm
The Bellman-Ford algorithm can handle graphs with negative edge weights and can detect negative cycles. It works by relaxing all edges repeatedly, gradually improving distance estimates until convergence.
While slower than Dijkstra’s algorithm, Bellman-Ford’s ability to handle negative weights makes it valuable for certain applications like currency arbitrage detection and some network protocols.
Floyd-Warshall algorithm
The Floyd-Warshall algorithm finds shortest paths between all pairs of vertices in a weighted graph. It uses dynamic programming to build up solutions by considering intermediate vertices.
This algorithm is particularly useful when you need the shortest paths between all node pairs and when the graph is relatively small, as its cubic time complexity can become prohibitive for large graphs.
A* search algorithm
A* is an extension of Dijkstra’s algorithm that uses heuristics to guide the search toward the target, making it more efficient for single-destination shortest path problems. The algorithm combines the actual distance from the start (g-cost) with a heuristic estimate to the goal (h-cost).
The effectiveness of A* depends heavily on the quality of the heuristic function. A good heuristic should be admissible (never overestimate the actual cost) and consistent to guarantee optimal solutions.
Minimum spanning tree algorithms
Minimum Spanning Tree (MST) algorithms find the subset of edges that connects all vertices with the minimum total edge weight, without forming cycles. These algorithms are crucial for network design and optimisation problems.
Prim’s algorithm
Prim’s algorithm builds the MST by starting with an arbitrary vertex and repeatedly adding the minimum-weight edge that connects the current tree to a new vertex. This approach ensures the tree grows in a connected manner.
The algorithm maintains a priority queue of edges and uses a cut property to ensure optimality. At each step, it selects the minimum-weight edge crossing the cut between the current tree and remaining vertices.
Kruskal’s algorithm
Kruskal’s algorithm builds the MST by sorting all edges by weight and adding them to the tree if they don’t create a cycle. It uses a Union-Find data structure to efficiently detect cycles.
This algorithm is particularly efficient for sparse graphs and provides a different perspective on MST construction compared to Prim’s vertex-centric approach.
Advanced graph algorithms
Advanced graph algorithms tackle more specialised and complex problems, often building upon the fundamental algorithms we’ve discussed. These algorithms are essential for sophisticated applications in data science, network analysis, and optimisation.
Maximum flow algorithms
Maximum flow algorithms solve the problem of finding the maximum amount of flow that can be sent from a source to a sink in a flow network. The Ford-Fulkerson method and its implementation, the Edmonds-Karp algorithm, are among the most important approaches.
These algorithms work by finding augmenting paths from source to sink and updating flow values until no more improvement is possible. The max-flow min-cut theorem establishes the fundamental relationship between maximum flow and minimum cut in networks.
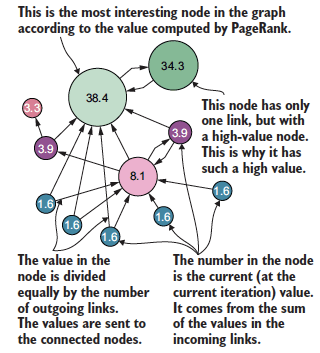
PageRank algorithm
PageRank, developed by Google’s founders, ranks nodes in a graph based on their importance as determined by the link structure. The algorithm models a random walker who follows links with probability d and jumps to random pages with probability (1-d).
The algorithm iteratively updates node scores until convergence, creating a ranking that considers both the number and quality of incoming links. This approach revolutionised web search and has applications far beyond search engines.
Community detection algorithms
Community detection algorithms identify clusters or groups of nodes that are more densely connected internally than externally. The Louvain method and Label Propagation are popular approaches for this problem.
These algorithms help reveal the modular structure of networks, identifying natural groupings that might represent functional units, social circles, or organisational divisions.
Topological sort
Topological sorting produces a linear ordering of vertices in a Directed Acyclic Graph (DAG) such that for every directed edge (u,v), vertex u comes before vertex v in the ordering. This algorithm is fundamental for dependency resolution and scheduling problems.
Graph neural networks (GNNs)
Graph Neural Networks represent a cutting-edge approach to machine learning on graph-structured data. GNNs can learn node embeddings, predict links, and classify entire graphs by leveraging both node features and graph structure.
Popular GNN architectures include Graph Convolutional Networks (GCNs), GraphSAGE, and Graph Attention Networks (GATs), each offering different approaches to aggregating information from node neighbourhoods.
Real-world applications of graph algorithms
Graph algorithms power many of the technologies and services we interact with daily. Understanding these applications helps illustrate the practical importance and versatility of graph-based approaches to problem-solving.
Social network analysis
Social media platforms leverage graph algorithms extensively to enhance user experience and engagement. According to research from AlgoCademy, “Social media platforms like Facebook, LinkedIn, and Twitter heavily rely on graph algorithms to analyse user connections, recommend friends, and detect communities.”
Friend recommendation systems use algorithms like collaborative filtering combined with graph traversal to suggest connections based on mutual friends, shared interests, and interaction patterns. Community detection algorithms help identify groups of users with similar interests or strong interconnections, enabling targeted content delivery and advertising.
Influence analysis using centrality measures helps platforms identify key opinion leaders and understand information propagation patterns. This knowledge is crucial for content moderation, viral marketing campaigns, and understanding social dynamics.
Recommendation systems
Modern recommendation systems often model user-item interactions as bipartite graphs, where users and items form two distinct node sets connected by preference edges. Graph algorithms then identify patterns and similarities to generate personalised recommendations.
Collaborative filtering approaches use graph algorithms to find similar users or items based on connection patterns. Random walk algorithms can discover items through multi-hop paths, enabling serendipitous recommendations that pure similarity-based methods might miss.
Knowledge graphs enhance recommendations by incorporating semantic relationships between entities, allowing systems to understand why certain recommendations make sense and provide explanations to users.
Route optimization
Navigation systems rely heavily on shortest path algorithms to provide optimal routes for various transportation modes. Modern GPS systems must consider multiple factors, including traffic conditions, road types, tolls, and user preferences.
Dynamic routing algorithms continuously update optimal paths based on real-time traffic data, using variants of Dijkstra’s algorithm with time-dependent edge weights. Multi-modal transportation planning combines different transportation methods using graph algorithms that can switch between walking, public transit, and driving segments.
Logistics companies use vehicle routing problem (VRP) algorithms, which extend basic shortest path algorithms to optimise delivery routes for multiple vehicles with capacity constraints and time windows.
Fraud detection
Financial institutions use graph algorithms to detect fraudulent activities by analysing transaction networks and identifying suspicious patterns. Fraudulent transactions often exhibit distinct graph patterns, such as rapid money transfers through multiple accounts or unusual connection patterns between accounts.
Community detection algorithms help identify networks of potentially coordinated fraudulent accounts, while anomaly detection algorithms flag transactions that deviate significantly from normal patterns. Graph-based approaches are particularly effective because fraudsters often create networks of accounts to distribute and launder money.
Real-time fraud detection systems use streaming graph algorithms to analyse transactions as they occur, enabling immediate blocking of suspicious activities.
Bioinformatics
Biological systems are naturally represented as graphs, making graph algorithms essential tools in bioinformatics. Protein-protein interaction networks, gene regulatory networks, and metabolic pathways all benefit from graph-based analysis.
Drug discovery uses graph algorithms to identify potential drug targets by analysing protein interaction networks and finding central or bridging proteins whose disruption might have therapeutic effects. Pathway analysis helps researchers understand how genes and proteins work together in biological processes.
Phylogenetic tree construction uses graph algorithms to build evolutionary relationships between species based on genetic similarity data, helping researchers understand evolutionary history and relationships.
Network flow optimisation
Telecommunications and computer networks use graph algorithms for routing, load balancing, and capacity planning. Internet routing protocols like OSPF (Open Shortest Path First) use shortest path algorithms to determine optimal routes for data packets.
Content delivery networks (CDNs) use graph algorithms to determine optimal server placement and content routing to minimise latency and maximise throughput. Network reliability analysis uses graph algorithms to identify critical nodes and edges whose failure would significantly impact network connectivity.
Software-defined networking (SDN) systems use graph algorithms to dynamically reconfigure network paths based on current conditions, enabling more efficient and adaptive network management.
Graph databases
Graph databases represent a paradigm shift in data storage and querying, designed specifically to handle highly connected data efficiently. Unlike traditional relational databases that struggle with complex relationships, graph databases make connections first-class citizens.
Native graph storage
Native graph databases store data in graph structures from the ground up, optimising storage and retrieval for connected data. This approach provides significant performance advantages for graph traversal operations compared to traditional databases that simulate graphs using tables and foreign keys.
Index-free adjacency is a key feature of native graph databases, where each node directly references its connected nodes without requiring index lookups. This design enables constant-time traversal of relationships, making complex graph queries much faster.
Neo4j
Neo4j is the leading graph database platform, offering both community and enterprise editions. It uses the Cypher query language, which provides an intuitive way to express graph patterns and traversals using ASCII art-like syntax.
Neo4j excels in use cases requiring complex relationship queries, such as intelligence analysis, fraud detection, recommendation engines, network analysis, and knowledge management systems. Its ACID compliance and clustering capabilities make it suitable for production environments requiring high availability and consistency.
The platform includes built-in graph algorithms through the Graph Data Science library, providing implementations of centrality measures, community detection, similarity algorithms, and pathfinding algorithms optimized for large-scale graphs.
Complexity analysis of graph algorithms
Understanding the computational complexity of graph algorithms is crucial for selecting appropriate algorithms and predicting performance on different graph sizes and structures. Complexity analysis helps developers make informed decisions about algorithm selection and optimisation strategies.
Time complexity considerations
Graph algorithm time complexity typically depends on the number of vertices (V) and edges (E) in the graph. Dense graphs where E approaches V² require different algorithmic approaches than sparse graphs where E is closer to V.
Space complexity analysis
Space complexity for graph algorithms includes both the graph representation and auxiliary data structures. The choice of graph representation significantly impacts space requirements:
Big O notation in practice
While Big O notation provides asymptotic analysis, practical performance depends on constant factors, cache behaviour, and implementation details. For example, a theoretically faster algorithm might perform worse on small graphs due to higher constant factors or poor cache locality.
Understanding the practical implications of complexity analysis helps in making informed decisions about algorithm selection based on expected graph characteristics and performance requirements.
Handling large graphs
As data volumes continue to grow exponentially, handling large graphs with millions or billions of nodes and edges presents unique challenges. Traditional algorithms and data structures may become impractical, requiring specialised techniques and distributed approaches.
Graph partitioning strategies
Graph partitioning divides large graphs into smaller, more manageable subgraphs while minimising the number of edges between partitions. Effective partitioning strategies enable parallel processing and reduce memory requirements for individual processing units.
Common partitioning approaches include:
- Edge-cut partitioning: Minimises edges between partitions
- Vertex-cut partitioning: Replicates high-degree vertices across partitions
- Hash-based partitioning: Uses hash functions for simple, balanced partitioning
- Community-based partitioning: Leverages natural community structure
Distributed graph processing
Distributed graph processing frameworks like Apache Spark GraphX, Apache Giraph, and Pregel enable processing of massive graphs across clusters of machines. These systems handle the complexity of distributed computation, fault tolerance, and communication optimisation.
The Pregel API, introduced by Google, provides a vertex-centric programming model where computation is expressed as a series of supersteps. Each vertex can send messages to its neighbours and update its state based on received messages, enabling the natural expression of many graph algorithms.
Streaming graph algorithms
Many real-world graphs are dynamic, with nodes and edges being added or removed continuously. Streaming graph algorithms process these updates incrementally without recomputing entire solutions from scratch.
These algorithms are essential for applications like real-time intelligence analysis, fraud detection, dynamic social network analysis, and live traffic routing, where graph structure changes rapidly and decisions must be made quickly.
Approximation algorithms
For extremely large graphs, exact algorithms may be computationally prohibitive. Approximation algorithms provide near-optimal solutions with significantly reduced computational requirements.
Sampling-based approaches analyse representative subsets of the graph to estimate global properties. These techniques are particularly useful for centrality measures, community detection, and graph summarisation tasks.
Conclusion
Graph algorithms represent a fundamental pillar of computer science and data analysis, providing powerful tools for understanding and optimising complex systems. From the basic traversal algorithms that form the foundation of graph analysis to sophisticated machine learning approaches like Graph Neural Networks, these algorithms continue to evolve and find new applications.
The practical importance of graph algorithms cannot be overstated. They power the recommendation systems that suggest products and content, the navigation systems that guide our daily travel, the fraud detection systems that protect our financial transactions, and the social networks that connect us globally. As noted by experts in the field, “Algorithmic literacy is as important as reading, writing, and arithmetic” – Medium.
Looking forward, several trends are shaping the future of graph algorithms:
- Integration with machine learning: Graph Neural Networks and embedding techniques are creating new possibilities for learning from graph-structured data
- Real-time processing: Streaming graph algorithms enable real-time analysis of dynamic networks
- Scalability solutions: Distributed processing frameworks and approximation algorithms address the challenges of massive graphs
- Domain-specific applications: Specialised algorithms for bioinformatics, social networks, and IoT applications
- Quantum graph algorithms: Emerging quantum computing approaches may revolutionise certain graph problems
To effectively leverage graph algorithms in your work, consider the following recommendations:
- Start with the fundamentals: Master BFS, DFS, and shortest path algorithms as they form the foundation for more advanced techniques
- Choose appropriate representations: Select graph representations based on your specific use case and performance requirements
- Consider scalability early: Plan for growth by choosing algorithms and data structures that can handle increasing graph sizes
- Leverage existing libraries: Use well-tested implementations from libraries like NetworkX, SNAP, or graph database built-ins rather than implementing from scratch
- Understand your data: Analyse your graph’s characteristics (density, distribution, dynamics) to inform algorithm selection
Whether you’re building recommendation systems, analysing social networks, optimising logistics, or exploring biological relationships, graph algorithms provide the computational foundation for extracting insights from connected data. As our world becomes increasingly interconnected, the ability to understand and manipulate these relationships through graph algorithms becomes ever more valuable.
FAQ
What is a graph algorithm?
A graph algorithm is a computational procedure designed to solve problems related to graphs – data structures consisting of nodes (vertices) connected by edges. These algorithms analyse relationships, find optimal paths, detect patterns, and solve optimisation problems in networked data. Examples include shortest path algorithms for navigation, centrality measures for influence analysis, and community detection for identifying clusters in social networks.
What are the different types of graph algorithms?
Graph algorithms can be categorised into several main types:
1. Traversal algorithms like BFS and DFS for systematic graph exploration
2. Shortest path algorithms like Dijkstra’s and A* for finding optimal routes
3. Minimum spanning tree algorithms like Prim’s and Kruskal’s for network optimisation
4. Flow algorithms for capacity and matching problems
5. Centrality algorithms for identifying important nodes
6. Community detection algorithms for clustering
7. Specialised algorithms like topological sorting and cycle detection.
What are the applications of graph algorithms?
Graph algorithms have extensive real-world applications, including:
– GPS navigation and route optimisation
– Social media friend recommendations and influence analysis
– fraud detection in financial networks
– recommendation systems for e-commerce and streaming platforms
– network routing and optimisation in telecommunications
– supply chain optimisation
– knowledge graph construction for AI systems.
How do I choose the right graph algorithm for my problem?
Choosing the right graph algorithm depends on several factors:
1. Problem type – whether you need shortest paths, connectivity analysis, or optimisation
2. Graph characteristics – size, density, whether it’s directed/undirected, weighted/unweighted
3. Performance requirements – real-time vs. batch processing, memory constraints
4. Accuracy needs – exact vs. approximate solutions
5. Dynamic requirements – static vs. streaming graphs.
Start by clearly defining your problem, analysing your graph’s properties, considering scalability needs, and evaluating trade-offs between accuracy and performance.