Categories
Topics


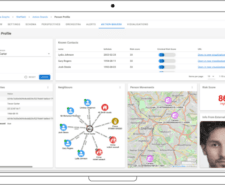
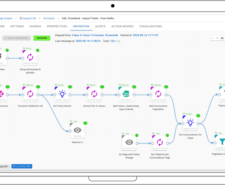
Easily converting multiple distributed data sources into a single, connected source of truth, is the start of a great graph-native intelligence analysis. Hume Orchestra is used for data ingestion from …
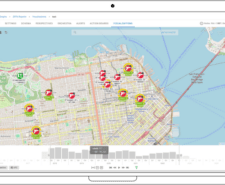
In the realm of intelligence analysis, data often needs to be contextualised within geographic or temporal frameworks. Through Geospatial Analysis, Hume provides visibility into the locations of the data, while …
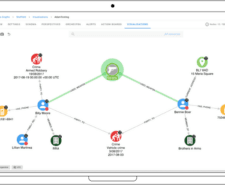
Run complex intelligence analysis with ease using Hume Actions – customised queries that offer the full power of Neo4j’s Cypher query language. With a single click, unlock answers to investigative …