
There’s a pattern I’ve seen time and again when supporting teams through intelligence analysis platform rollouts: implementation purgatory.
Projects drag on for months, sometimes years, before delivering meaningful value. Data is integrated. Systems are configured. Workflows are designed. Analysts are trained. But despite all that effort, teams often reach a point where they still can’t answer the questions that matter.
This isn’t a problem with the work itself. That integration process is necessary in any environment. The problem is how long it takes before teams can start seeing value from it.
In many cases, data must be fully integrated before analysis begins. Workflows must be defined before users engage. The system must be “complete” before it’s useful.
In practice, that approach delays the most important moment: when analysts can start working with connected data to answer real investigative questions.
It doesn’t have to be that way.
With the right approach, teams can begin working with a connected intelligence environment in a matter of days. Not as a finished system, but as a usable graph. One that already supports real analysis, answers real questions, and proves value early, building momentum from the outset.
This blog post outlines a five-day process I’ve used with teams to move from fragmented data to a working, connected intelligence environment. The same pattern applies anywhere teams need to connect data, explore relationships, and answer complex questions under pressure.
Why teams start looking for a different approach
By the time organisations begin exploring graph-powered intelligence analysis, they are usually facing a familiar set of challenges:
- Critical information exists across multiple systems, but understanding how that information connects requires manual work
- Analysts spend too much time switching between tools, cross-referencing records, and reconstructing context to understand what matters and what information can be trusted
- Important connections between people, locations, events, or assets are hidden and impossible to uncover
- Questions that should be straightforward take hours or days to answer
In many cases, the data already exists. What’s missing is the ability to explore how it connects.
To make this concrete, let’s explore the problem with a specific example, based on an imaginary vehicle-theft investigation.
In this scenario, the data is spread across multiple systems:
- ANPR systems capturing vehicle sightings, movements, and location patterns
- Vehicle registration systems holding ownership and vehicle history
- Intelligence databases listing known individuals and links to previous offences
- Custody, arrest, and digital forensics systems linking suspects to devices and past activity
When data is siloed like this, answering even simple questions requires stitching together results from multiple systems.
GraphAware Hume addresses this by creating a connected intelligence picture, allowing analysts to explore relationships directly rather than reconstructing them manually.
A five-day path to connected intelligence
The goal of this process isn’t to build a complete system. It’s to get the team working with a live intelligence platform that lets them answer real investigative questions faster and more clearly than was previously possible. In five days, they’ll establish a solid, connected intelligence foundation to build from.
To make this concrete, imagine the team is trying to answer a simple question:
Are any vehicles repeatedly present near specific crime locations, and are they linked to known individuals?
The five-day process focuses on answering that question as quickly as possible using GraphAware Hume.
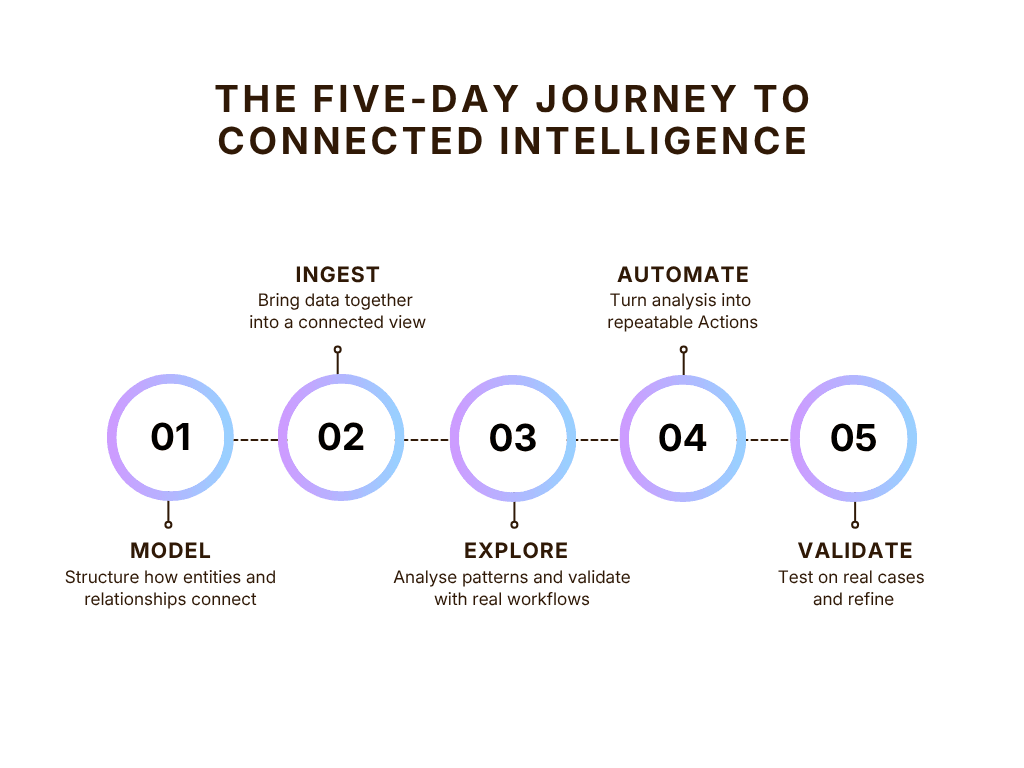
Day 0: Prepare the foundations
Before the five days begin, I’ve found the team needs to align on three things: the specific analytical question to answer, the data sources required to answer it, and how analysts currently approach the problem.
This stage also addresses the practical constraints that can derail a proof of concept, particularly those related to data access. In many organisations, accessing data involves security reviews, compliance checks, and ownership approvals that can be time-consuming to navigate. Resolving these upfront means the five days can be used for actual work.
In the vehicle-theft scenario, this means being specific about both the question and the data required to answer it.
From a data perspective, the team confirms access to the relevant systems:
- ANPR data capturing vehicle sightings
- Vehicle registration records
- Intelligence databases covering known individuals
At the same time, the analytical question is broken down into a series of smaller, answerable steps:
- Where did the crimes take place?
- Which ANPR cameras were nearby?
- When did the crimes occur?
- Which vehicles were captured in those locations during the relevant time windows?
- Do any vehicles appear repeatedly across multiple incidents?
- Who are those vehicles linked to?
This decomposition is critical. It turns a broad investigative question into a sequence of concrete steps that will later inform the data model and the queries analysts run.
Crucially, this stage is not driven solely by developers. Intelligence analysts are actively involved throughout, ensuring the problem is grounded in real investigative work rather than assumptions about how analysis should happen.
By the end of this stage, there is a clearly defined use case, confirmation that the right data is accessible, and alignment on what success looks like.
Day 1: Define how the data connects
Day one establishes the foundation for the graph data model. This is when the team defines which entities exist and how they connect.
This is also where close collaboration between developers and analysts matters most. The model is not designed in isolation. It is shaped by the people who will use it, reflecting how investigations actually unfold rather than how systems happen to store data.
The model determines what analysts can see and the kinds of questions they can ask. If it mirrors how data is stored across systems, analysis remains fragmented. If it reflects how investigators think about the problem, analysis becomes intuitive and insightful.
Rather than recreating source systems, the team defines a structure aligned to the investigative questions they are trying to answer.
In the vehicle theft scenario, this means deciding what should be represented as entities (e.g. people, vehicles, incidents), what relationships should exist between them, and what attributes matter for the questions being asked.
By the end of the day, the team has a working model that allows them to:
- Identify how vehicle sightings, incidents, locations, and known individuals connect
- See how vehicles can be traced across incidents and time windows
- Understand how proximity to crimes and links to known individuals can be represented in the model
This model becomes the foundation for everything that follows. It defines how data will be ingested, how relationships will be explored, and ultimately what analysts can see and understand.
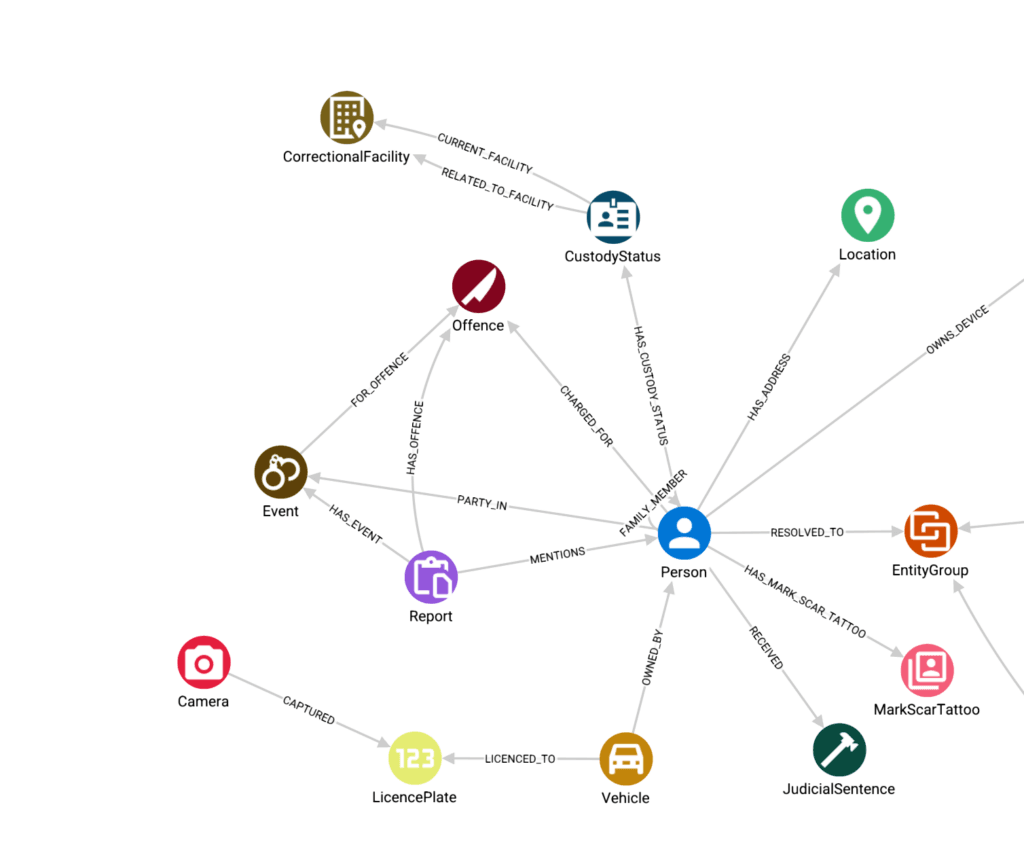
What graph data modelling involves
In GraphAware Hume, the graph data model serves as the schema for organising and exploring data.
Defining that schema means defining three core components:
- Nodes, such as people, vehicles, or locations
- Relationships between them, such as `OWNS`, `SIGHTED_AT`, or `ASSOCIATED_WITH`
- Attributes, such as incident timestamps, vehicle identifiers, or ANPR camera coordinates.
These decisions are driven by the questions analysts need to answer.
For the vehicle theft investigation, a starting model might represent ownership simply as:
(Person)-[:OWNS]->(Vehicle)
But a simple ownership relationship may not tell the full story. Criminals may use cars registered to a family member or associate. A more useful model might use shared context:
(Vehicle)-[:REGISTERED_TO]->(Person)
(Person)-[:RESIDES_AT]->(Address)
This allows analysts to identify indirect connections, such as vehicles registered to individuals who share an address with other known suspects.
These modelling decisions determine what analysts can and can’t see. Getting them right at day one is what makes the exploration on day three meaningful.
It’s important to remember that the model isn’t fixed. It evolves as analysts start working with the data and new requirements emerge.
Day 2: Ingest the data
Day two is largely engineering work, and it’s the day I tell teams to resist the urge to over-engineer. The goal is simple: turn the graph data model from day one into something analysts can actually explore.
Data from multiple source systems is ingested through pipelines in Hume Orchestra, then transformed and mapped onto the nodes and relationships defined on day one.
In this scenario, that means bringing together ANPR data, vehicle registrations, incident reports and device identifiers, and connecting them in a way that reflects the model defined on day one.
By the end of the day, the data is no longer a set of disconnected records. It forms a connected structure that’s ready to be explored.
What building a pipeline looks like
In GraphAware Hume, this is handled using GraphAware Hume Orchestra, our workflow engine for data integration and transformation.
Workflows are built visually in Orchestra’s canvas, where components are linked together to define how data flows from source to graph.
A typical pipeline might include:
- A data source component reading from a database, file, or API
- Processing components to clean and structure the data
- Integration steps that call out to external services where needed (for example, for entity resolution, data enrichment, or extraction from unstructured text)
- A persistence component writing the result into the graph
In this scenario, that might involve:
- Streaming ANPR data and linking sightings to vehicles and locations
- Joining vehicle registration data to known individuals
- Parsing incident reports and associating them with both
In this phase, the role of Hume Orchestra is to act as the integration layer between source systems, data stores, and external services, bringing data together into a single connected intelligence view that can be explored in GraphAware Hume.
These modelling decisions determine what analysts can and can’t see. Getting them right at day one is what makes the exploration on day three meaningful.
It’s important to remember that the model isn’t fixed. It evolves as analysts start working with the data and new requirements emerge.
Day 3: Explore the graph
The goal of day three is to put the connected data into the hands of analysts and enable them to start answering real investigative questions.
Analysts begin exploring the graph in the same way they would approach a real case, starting from a hypothesis, searching for known entities, and expanding outward.
In this vehicle theft scenario, an analyst might:
- Start with a specific incident and define a time window around it
- Use geospatial filtering to identify ANPR cameras within a defined radius
- Restrict results to a relevant timeframe using the time controls
- Return the set of vehicles captured in that window and group them for further analysis
- Repeat this process across multiple incidents to identify vehicles that appear repeatedly
Over time, this reveals vehicles that are consistently present across multiple crime locations and time windows.
This is the point where analysis moves beyond isolated records. Teams are no longer asking whether the data connects; they can see how it connects, and what that reveals. Day three also serves a practical function, with analysts and developers working together to identify which analysis steps are being repeated. Any process that an analyst finds themselves repeating is a candidate for automation. These become the foundation for day four.
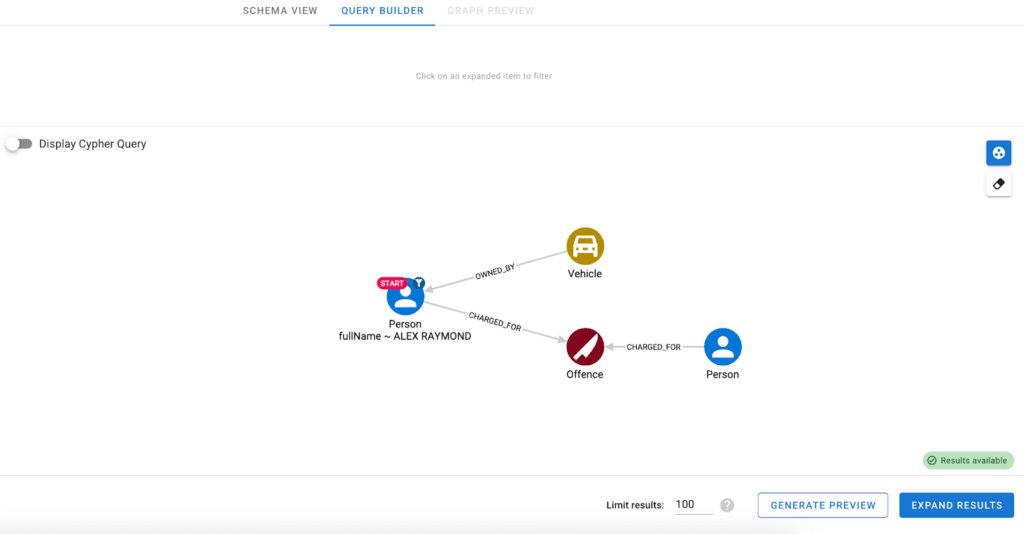
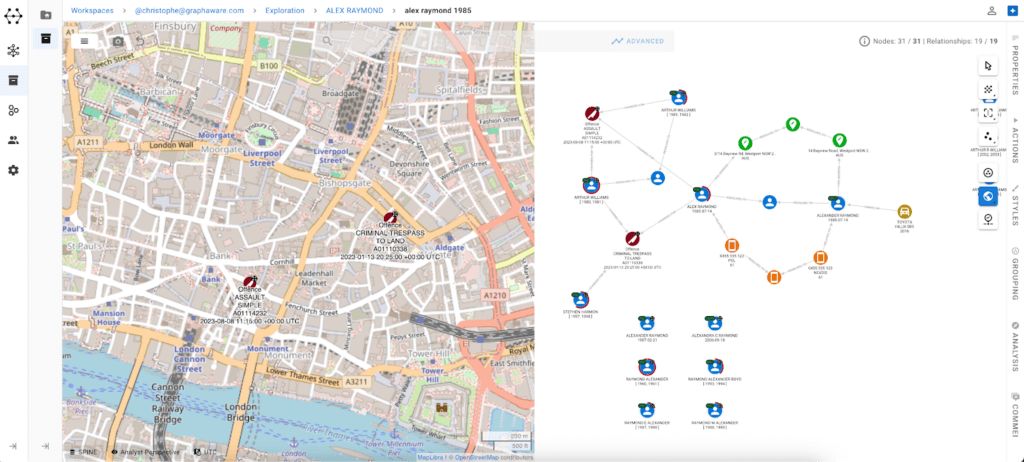
What analysts do at this stage
At this stage, analysts begin working directly with connected data, moving away from document-based workflows towards a connected, graph-driven model.
Instead of searching across isolated records, they explore how people, vehicles, locations, and events relate to each other, building a clearer understanding of how activity connects.
A typical exploration workflow involves:
- Searching for entities of interest and expanding their relationships
- Identifying patterns, overlaps, and anomalies in the graph
- Framing investigative questions as relationships between entities
- Iteratively refining searches and views to focus on what matters
In the vehicle theft scenario, that might include:
- Exploring links between vehicle sightings, registered owners, and known associates
- Tracing connections from incidents to related people, vehicles, and locations
- Identifying vehicles that appear repeatedly across multiple incidents
This stage is also where validation begins. Teams assess whether the data model supports real investigative workflows, is intuitive for analysts to use, and surfaces the right information.
In practice, this often leads to immediate refinements, adjusting the model, improving data quality, or tuning how results are returned.
The role of GraphAware Hume in this phase is to provide an intuitive, visual environment for this exploration, allowing analysts to move from retrieving data to understanding how it connects.
Day 4: Turn analysis into repeatable workflows
The goal of day four is to take what analysts are doing manually and make it easily and quickly repeatable.
By this point, analysts have explored the data and identified common patterns in how they approach the problem.
In this scenario, that might include:
- Selecting an incident and time window
- Returning vehicles seen within a defined radius
- Comparing those vehicles across multiple incidents
- Surfacing links between recurring vehicles and known individuals
Individually, these steps are straightforward. But repeated manually, they become time-consuming and inconsistent.
Instead of relying on individual analysts to repeat the same process, the logic is captured as a Hume Action – a reusable canned Cypher query, so it can be applied consistently across investigations.
By the end of the day, the team has moved from exploratory analysis to a set of repeatable workflows that can be triggered in a few clicks. These repeated steps form the basis of the Actions defined in GraphAware Hume.
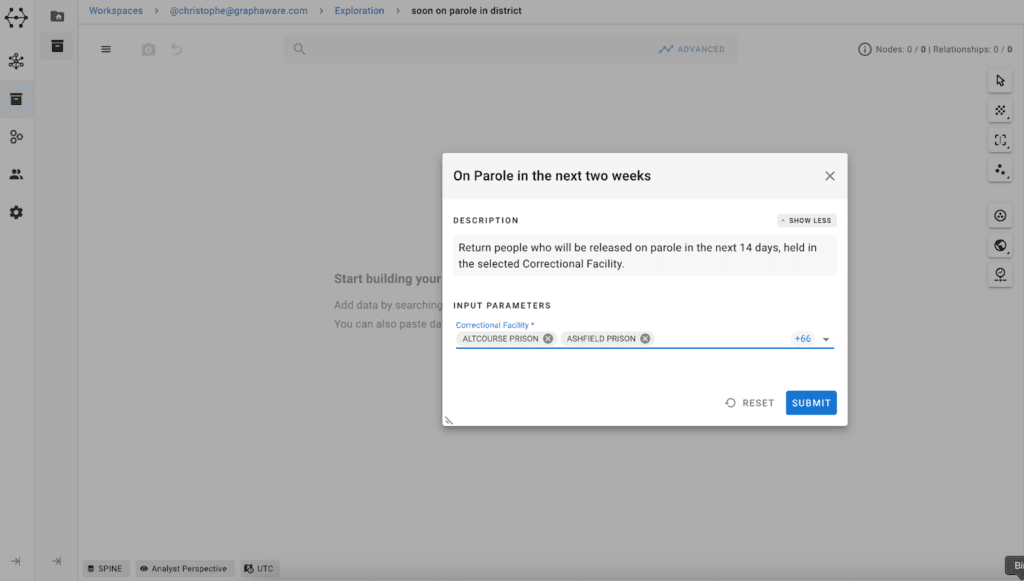
What Actions enable
In GraphAware Hume, repeated analytical workflows are captured as Actions.
These are reusable queries that can be saved and made available in the visualisation canvas for analysts to run on demand.
Actions can be created in different ways. Developers can define them either directly using Cypher queries or visually using GraphAware Hume’s query builder. In both cases, the underlying logic is captured and stored as a reusable operation.
Once defined, Actions can be shared across teams, scoped to different user groups, and applied to different datasets.
The result is that analysis moves from something individuals perform manually to something that can be executed consistently, repeatedly, and at scale.
Day 5: Observe, validate, and refine
The goal of day five is to understand how GraphAware Hume changes how analysis is done.
At this stage, the focus is not on demonstrating features, but on observing real usage. Analysts work through active or recently completed cases using the connected data and workflows created during the week.
In this scenario, that might mean starting with a set of incidents and identifying the vehicles and individuals associated with them.
By the end of the day, the comparison is clear: What previously required switching between systems and manually correlating results can now be done in a single environment, with the analysis logic visible and repeatable.
More importantly, analysts are no longer reconstructing the same logic from scratch each time. They are working from a connected intelligence view, with workflows that can be reused, refined, and shared.
What validation looks like
Validation at this stage is based on observation:
- Can analysts answer questions faster?
- Can they follow the logic of the analysis and the lineage of the data involved?
- Can they see connections they would have missed before?
- Can the same approach be reused across similar investigations?
This is also where Action Boards are introduced.
Once key entities and workflows are understood, teams create structured views that bring together the most relevant information in one place.
For example, a vehicle-focused board might show:
- Sightings over time
- Linked individuals
- Associated incidents
- Geographic patterns
These views are interactive and driven by Actions, allowing analysts to filter, refine, and explore without rebuilding the analysis each time.
Instead of assembling this view manually, analysts can access it instantly, creating consistency across investigations and reducing time spent gathering information.
In many cases, this is also where the impact becomes clear.
In one proof of concept, analysts who previously spent days correlating ANPR data, phone records and ownership information were able to identify four suspects within seconds, including one linked to another active case.
What comes after five days
The five-day process is not a one-off exercise. It’s the first cycle in an iterative process.
From this point, organisations typically repeat the cycle by:
- Adding new data sources
- Refining the model based on new requirements
- Introducing new actions to support evolving workflows
- Extending usage across teams
Each cycle builds on the last. The schema expands. Connections become richer. Workflows become more precise. Over time, the platform becomes a progressively richer and more reliable connected intelligence view.
With GraphAware Hume, organisations can move from fragmented data to a connected intelligence view in days rather than months, and then build on that foundation iteratively.
Interested in exploring how this could work in your organisation?
Get in touch to see how GraphAware Hume can help your team move from fragmented data to connected intelligence.
Get in touch