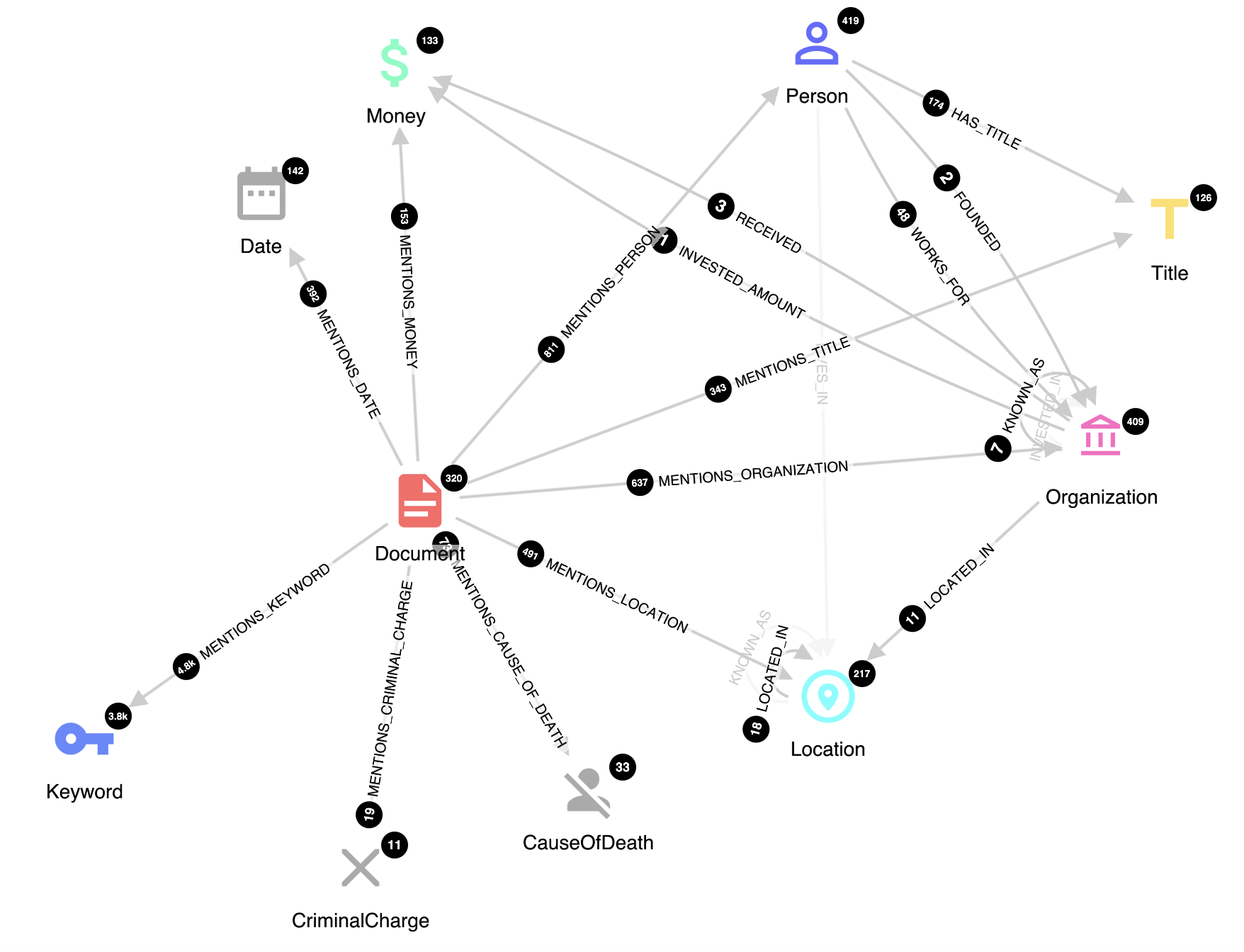
Knowledge Graphs (KGs) have become the backbone of multiple applications, including search engines, chatbots, and question and answering tools, where interactivity plays a crucial role.
If you have read our post Hume in Space: Monitoring Satellite Technology Markets with a ML-powered Knowledge Graph, you surely wonder: is there a way to extract relations among named entities without heavy investment? Investment in terms of time to label training dataset and to develop, train and deploy a machine learning model?
Everyone has a passion for something. Be it music, politics, sports, coffee or … pancakes. Such passion makes you strive for new information, for understanding of the current trends. Take pancakes: you might watch for new recipes on your favourite website, you might look at cooking shows or youtube videos to get more inspiration about how to serve them … but overall, you can probably handle this pretty well. It’s not like there is much room for revolutionising the pancake recipe.
Data is everywhere. News, blog posts, emails, videos and chats are just a few examples of the multiple streams of data we encounter on a daily basis. The majority of these streams contain textual data – written language – containing countless facts, observations, perspectives and insights that could make or break your business.
One of the key components of Information Extraction (IE) and Knowledge Discovery (KD) is Named Entity Recognition, which is a machine learning technique that provides us with generalization capabilities based on lexical and contextual information. Named Entities are specific language elements that belong to certain predefined categories, such as persons names, locations, organizations, chemical elements or names of space missions. They are not easy to find and subsequently classify (for example, organizations and space missions share similar formatting and sometimes even context), but having them is of significant help for various tasks: improving search capabilities relating documents among themselves or...